vLLM 最新版来了:推测解码终于能跑思考模型了

vLLM 最新版来了:推测解码终于能跑思考模型了

Ai学习的老章
发布于 2026-05-19 18:23:49
发布于 2026-05-19 18:23:49
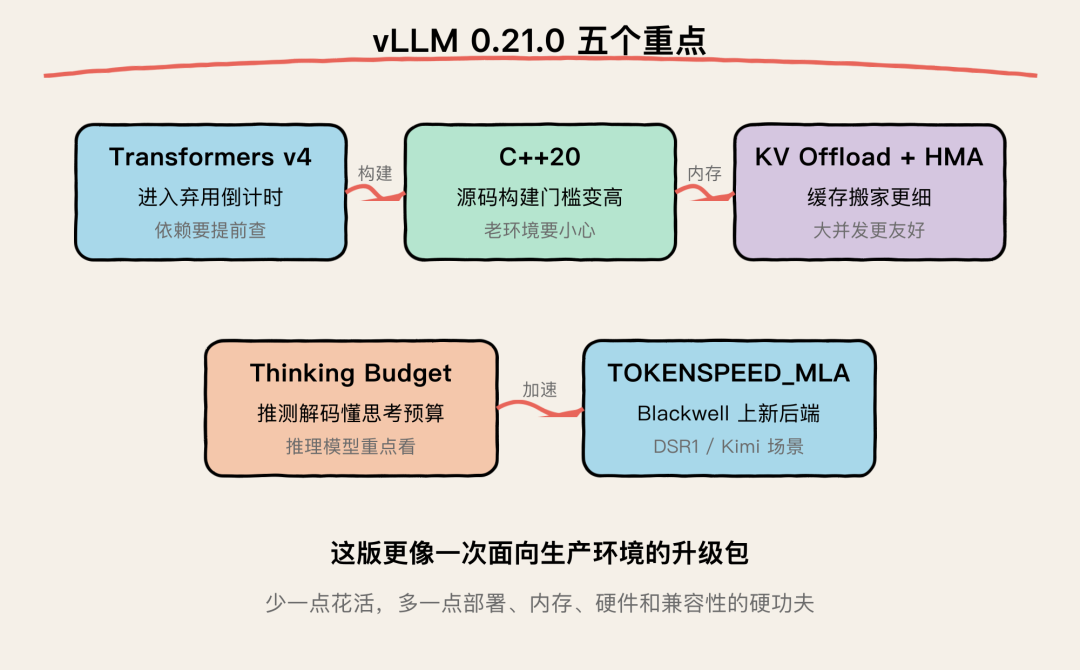
vLLM 0.21.0 五个重点
vLLM 0.21.0 五个重点
- vLLM 重磅项目
- vLLM 重要更新
- 大模型本地部署,vLLM 睡眠模式来了
- vLLM 赢完了:登顶开源推理引擎No1
- vLLM 最新版来了,修复 DeepSeek-V4 跑不稳、跑不快的问题
聊聊刚刚发布的 vLLM v0.21.0
如果你只是本地单卡偶尔跑模型,升级可以先观望
如果你在跑服务,尤其是 DeepSeek、Kimi、Qwen 这类模型,或者经常被 KV Cache、并发、显存、镜像体积折腾,这版值得认真看
简介
vLLM 官方对自己的定位很直接:一个用于大模型推理和服务的快速、易用库
它最有名的底层能力还是 PagedAttention,除此之外还有 continuous batching、chunked prefill、prefix caching、CUDA/HIP graph、量化、OpenAI 兼容 API、工具调用、reasoning parser、多硬件支持这些能力
说人话就是:你想把 Hugging Face 上的模型部署成一个能被应用调用的服务,vLLM 是目前最绕不开的选择之一

五个重点
第一,Transformers v4 support 进入弃用周期
官方 release 的措辞是 formally deprecates transformers v4 support,建议迁移到 Transformers v5
这里要准确一点,deprecated 的含义是进入弃用周期,旧项目大概率还能跑一段时间,但信号已经很清楚了:还绑在 Transformers v4 上的部署链路,要开始排查兼容性了
我个人挺支持这件事,推理框架长期背着旧依赖往前走,最后会变成谁都不敢动的泥潭
代价也很现实,如果你有老插件、老模型封装、魔改 tokenizer,升级前要多测几遍
第二,源码构建要求升级到 C++20
vLLM 现在要求 C++20-compatible compiler,用来匹配 PyTorch 相关构建变化,官方也明确标了 breaking build change
这条对直接 pip install 的用户影响可能不大,对源码编译、内网离线构建、魔改 vLLM 的同学影响很大
尤其是企业内网机器,编译器版本经常陈年老酒,一升级就露馅
第三,KV Offload 接上 Hybrid Memory Allocator
这条我很关注
KV Cache 是大模型服务里最容易吃掉显存的东西,长上下文、多并发、推理模型一叠上来,显存压力会非常真实
v0.21.0 把 KV offloading subsystem 和 Hybrid Memory Allocator 进一步整合,release 里提到了 scheduler-side sliding window group support、full HMA enablement、multi-connector HMA、MooncakeStoreConnector 等一串更新
这类更新普通用户看着不性感,但部署同学会懂:调度和内存管理稳一点,服务的上限就高一点
第四,推测解码开始尊重 thinking budget
这个是我最想聊的点
推测解码本来是用小模型或者 draft 机制帮大模型提前猜 token,用得好可以加速生成
问题是,推理模型多了一个很麻烦的东西:思考预算
模型什么时候想、想多久、哪些 token 属于 reasoning,这些都会影响推测解码的正确性
v0.21.0 的 release 明确写了 Speculative decoding now respects reasoning/thinking budgets,目标是让 reasoning models 的 spec decode 更正确
这句话看着短,但意义很大
DeepSeek-R1 之后,推理模型已经成了主流形态,推测解码如果适配不了 thinking budget,就会在最热门的模型类型上打折
当然,性能收益还要看模型、draft 模型、硬件和请求形态,别看到 spec decode 就默认吞吐翻倍
但方向是对的,而且是很关键的方向
第五,Blackwell 上来了 TOKENSPEED_MLA backend
如果你手里有 Blackwell,这条就很香
v0.21.0 新增 TOKENSPEED_MLA attention backend,面向 DeepSeek-R1/Kimi-K25 的 prefill + decode 场景
这说明 vLLM 的优化节奏越来越贴着新硬件走
普通消费级显卡用户不用为这条激动,但云厂商、企业推理集群、重度服务玩家会很关心
安装
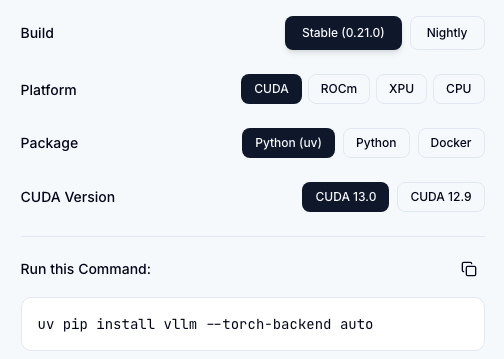
官方 Quickstart 推荐用 uv 管理环境,前置条件是 Linux,Python 3.10 到 3.13
如果你想锁定这次 v0.21.0,可以这样装:
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm==0.21.0 --torch-backend=auto
官方文档里的通用写法是这样,适合直接安装当前版本:
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm --torch-backend=auto
--torch-backend=auto 这个参数挺省心,它会根据 CUDA driver 自动选择合适的 PyTorch index
想临时跑一下,也可以不创建长期环境:
uv run --with vllm vllm --help
如果是 AMD ROCm,官方给的是额外 index:
uv venv --python 3.12 --seed
source .venv/bin/activate
uv pip install vllm --extra-index-url https://wheels.vllm.ai/rocm/
使用
vLLM 最常见的玩法,是直接起一个 OpenAI-compatible server
官方 Quickstart 里用的是 Qwen2.5-1.5B-Instruct:
vllm serve Qwen/Qwen2.5-1.5B-Instruct
默认服务地址是:
http://localhost:8000
查看模型列表:
curl http://localhost:8000/v1/models
普通 completions 调用:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
Chat Completions 调用:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-1.5B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."}
]
}'
Python 离线推理也很简单:
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
这里有个小坑,官方文档也提醒了:llm.generate 不会自动套 chat template
如果你跑的是 Instruct 或 Chat 模型,要自己套 tokenizer chat template,或者直接用 llm.chat
谁适合升级
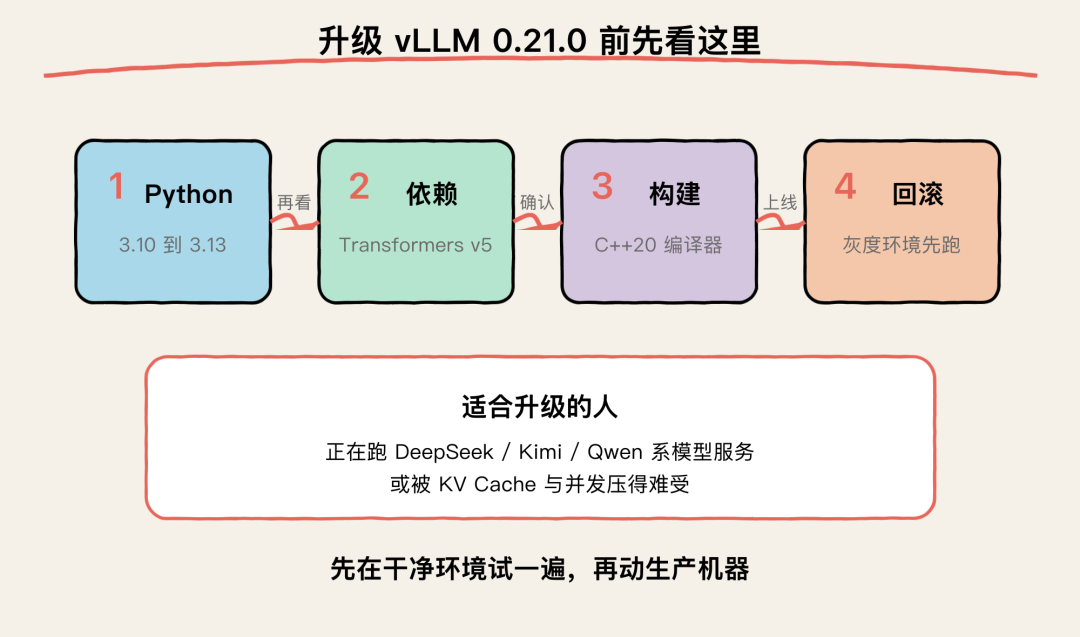
升级 vLLM 0.21.0 前先看这里
升级 vLLM 0.21.0 前先看这里
我会把适合升级的人分成四类:
第一类,正在跑推理模型服务的人
DeepSeek-R1、Kimi、Qwen 这类模型是你主力服务时,thinking budget + speculative decoding 这条值得关注
哪怕你暂时不用 spec decode,也能看出 vLLM 后面会继续围绕 reasoning model 做优化
第二类,被 KV Cache 和并发压得难受的人
长上下文、多用户并发、RAG、多轮对话,这些场景都会把 KV Cache 压力拉起来
KV Offload + HMA 相关更新很适合这类场景继续观察和测试
第三类,做集群和大规模服务的人
这版里 disaggregated serving、RayExecutorV2、DCP、NIXL、Mooncake connector 等更新不少
如果你只看本地跑一个模型,可能没感觉
如果你维护推理集群,这些才是大头
第四类,跟新硬件贴得很近的人
Blackwell、ROCm、CPU FP8、Intel XPU、IBM Power 都有更新
vLLM 已经越来越像一个多硬件推理调度底座,单纯把它理解成 NVIDIA GPU 上的 LLM server,已经有点窄了
不急着升的情况
有几种情况可以先稳住:
- 你当前 vLLM 版本很稳定,近期没有新模型、新硬件、新并发压力
- 你的环境依赖 Transformers v4,短期没时间做兼容检查
- 你需要源码构建,但机器上的编译器很旧
- 你只是用单卡本地玩玩模型,当前需求已经满足
这版很强,但它带着 breaking build change,升级前要尊重生产环境
总结
vLLM v0.21.0 给我的感觉,是一次很工程化的大版本升级
它清理旧依赖,抬高构建要求,继续强化 KV Cache 和大规模服务能力,同时开始认真处理 reasoning model 时代的推测解码问题
我最看重的是 thinking budget + speculative decoding,这代表推理框架开始真正适配“会思考”的模型
我最谨慎的是 C++20 和 Transformers v4 deprecation,这两个点可能会让老环境升级时踩坑
一句话建议:
生产服务玩家,建议尽快开灰度环境测
本地体验玩家,可以等社区多跑几天再动手
#vLLM #大模型部署 #推测解码 #KVCache #本地部署
制作不易,如果这篇文章觉得对你有用,可否点个关注,给我个三连击:点赞、转发和在看,若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号