[AI架构师转型系列-6] Agent的拆与不拆

[AI架构师转型系列-6] Agent的拆与不拆

用户5602664
发布于 2026-06-15 11:14:12
发布于 2026-06-15 11:14:12
本篇你将学到:
- 什么时候该拆、什么时候不该——三个判断条件的正反两面
- 设计多 Agent 架构——每个 Agent 独立选模型、独立扩缩容,Orchestrator 如何设计才不会成为瓶颈
- 部署上云的关键决策:网络规划、安全组、弹性伸缩、健康检查——每个数字的决策依据
- 拆了之后的新问题:延迟叠加、调试变难、上下文损耗——以及怎么缓解
- 亲手做三个高可用验证实验:停实例、压测扩容、模拟 LLM 不可用
第五篇用 Dify 跑完了验证流程——模型选型定了、成本预估做了修正、编排边界找到了几处误判并修正了 Prompt。方案验证过了,该上生产了。但在部署之前,有一个更重要的架构决策要做:MumuMall 的智能客服是一个 Agent 搞定所有事,还是拆成多个?
这个问题和十年前"单体应用要不要拆微服务"是同一类问题。但 Agent 的拆分决策比微服务更复杂——因为 Agent 的行为不是确定的。
拆分决策:什么时候该拆,什么时候不该
当前 MumuMall 的架构是一个 Agent + 四个 Tool。所有能力耦合在一个 Agent 里——它既要判断用户意图、又要检索知识库、又要管工单、又要判断什么时候转人工。
这像不像十年前那个单体应用?一个 War 包里塞了订单、用户、支付、物流。
什么时候该拆?三个判断条件:
条件一:Prompt 是否越来越长,越来越难维护。一个 Agent 要处理知识检索、工单查询、转人工三个场景,System Prompt 里需要定义三种场景的规则。每加一个新场景——比如"物流查询"——Prompt 就要加一段。三个月后 Prompt 2000 字,改一句担心影响全局。
MumuMall 的情况:当前四个场景,Prompt 已经 800 字。如果后面要加多语言客服、语音客服、主动营销——拆。
条件二:不同能力对模型的要求是否不同。知识检索需要理解自然语言、从文档中提取信息——需要参数量大的模型(Qwen-Max/DeepSeek-V3)。但意图判断就是一个分类任务——把用户输入分到"知识咨询/工单操作/转人工"三个类别——Qwen2.5-7B 绰绰有余。
如果意图判断用一个 7B 小模型自建部署,每次意图判断的 Token 成本几乎为零——和用大模型 API 做简单分类相比,单价差异可达数量级。单次金额不大,但架不住呼叫次数多,日积月累下来不是小数。架构师要想这件事。
MumuMall 的情况:意图判断和知识检索可以用不同模型——拆。
条件三:是否有些能力需要独立扩容。大促期间,MumuMall 咨询量可能翻几倍。但翻的不是所有场景——大促带来的增量咨询绝大部分是"我的订单什么时候到"这种物流查询,复杂退换货咨询的占比其实不高。
如果是一个 Agent,整条链路一起扩容。物流查询和生鲜售后用的是同一组 ECS 实例。如果是拆开的——Ticket Agent(负责工单和物流)单独扩容,Knowledge Agent(负责知识检索)保持不动。不同场景的流量增长曲线不一样,分开扩缩容才能把钱花在刀刃上。
MumuMall 的情况:不同场景的流量不均衡,独立扩容能省钱——拆。
三个条件全中。MumuMall 应该拆。
反过来——什么时候不该拆?
三个条件也可以反过来用:条件一个不沾时,不拆。
场景一:场景少、团队小。比如一个内部知识库问答系统,只有一个"检索知识库→回答问题"的场景。Prompt 再长也就一个场景的规则,半年不会变。团队就两个人,拆成多个 Agent 只会增加沟通成本——本来改一个 Prompt 的事,变成协调三个 Agent 的交互逻辑。
场景二:所有能力对模型的要求同一档。如果你的所有任务都需要强推理能力(比如法律文书分析),根本不存在"意图判断用小模型省钱"的空间——小模型做不了,全用大的。模型差异化带来的成本优势在这里是零。
场景三:流量小且均匀。比如一个内部使用的周报生成工具,每天就几十次调用,场景固定,大促跟你没关系。独立扩容对你没有意义——一台 ECS 全搞定,拆了反而多交几份基础资源费。
这三个场景有一个共性:业务复杂度还没到那个份上。过早拆分 = Agent 版的"微服务过度设计"——一个 CRUD 应用拆成八个微服务,除了让部署图好看,没什么实际收益。
判断公式很简单:三个条件中几个 —— 零个不拆,一个犹豫,两个倾向拆,三个全中就别犹豫了。但"犹豫"的时候,先别拆。把 Agent 写好、跑稳了,等需求逼到你不得不拆,那时候拆的理由是实打实的,不是杞人忧天。
拆成什么样
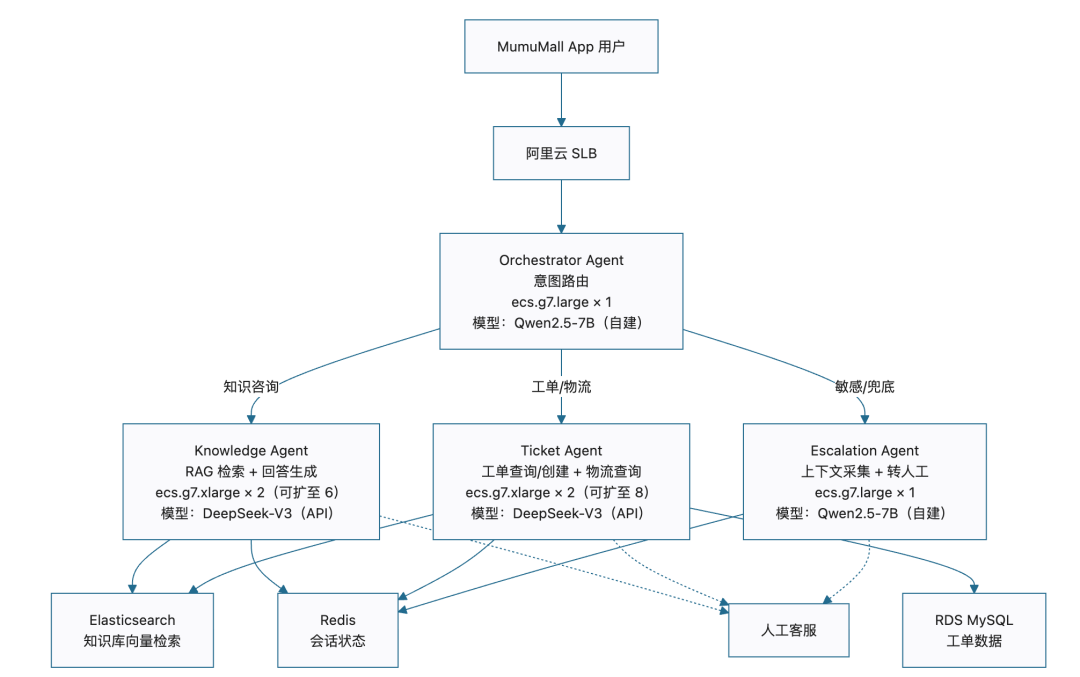
拆分为四个 Agent。每个有独立的职责、独立的模型选择、独立的扩容策略。
关键设计决策:
决策 | 选择 | 为什么不选别的 |
|---|---|---|
Orchestrator 用自建 7B | Qwen2.5-7B + Ollama 自建 | 意图判断是分类任务,7B 模型够用。自建零 Token 成本。不像知识检索需要理解复杂语义 |
Knowledge 和 Ticket 用大模型 API | 云端 API | 这两个 Agent 需要强中文理解和推理能力。小模型在复杂场景的准确率达不到业务要求(第 5 篇验证过,小模型在知识检索场景差距明显) |
Escalation 用自建 7B | Qwen2.5-7B + Ollama 自建 | 转人工只做上下文采集和格式化输出,不需要强推理 |
Knowledge 和 Ticket 独立部署 | 两组 ECS | 大促时物流查询流量暴增,Ticket 独立扩容,不影响 Knowledge |
Orchestrator 不扩容 | 1 台固定 | 意图判断极其轻量——每次只做分类,Token 消耗极低,一台中等规格的 ECS 就能撑住较高 QPS |
每个决策都写了"为什么选它、为什么不选别的"。这就是架构师的交付物——不是代码,是决策依据。
放大看 Orchestrator——最容易被低估的 Agent
四个 Agent 里,Orchestrator 最不起眼:不做知识检索、不查工单、不回应用户。但它是整个多 Agent 架构的中枢神经——它判错了,Knowledge Agent 再强也白搭。这里展开几个设计细节:
意图路由:不要只用 LLM分类,两级策略更稳。单纯用 LLM 做意图判断有两个风险:一是模型可能过度解读(用户说"退"就转人工,不管上下文),二是延迟不可控。建议两级策略:
- 第一级:规则前置。对明确的关键词直接路由——"物流""到哪了""什么时候到" → Ticket Agent;"退款""退货" → 知识检索先查政策。规则匹配不了的,再走第二级。
- 第二级:LLM 分类。把用户输入 + 历史上下文传给 7B 模型做意图分类。Prompt 里写出每个意图的边界条件——特别是"转人工"的触发规则(生鲜售后强情绪直接转、投诉二次升级转)。
规则挡住大部分简单流量,LLM 兜底模糊输入,延迟和成本都可控。
上下文传递:不是全传,是"翻译"。Orchestrator 不能把原始对话 dump 给下游 Agent。翻译一下:从"我的虾到了但不能用了,我要退款"里提取出结构化上下文——{问题类型: 生鲜售后, 情绪: 强负面, 诉求: 退款, 订单号: 未提供}。下游 Agent 不用再解析自然语言,直接对结构化信息做后续处理。这一步省掉的不只是 Token,更是下游判错的可能性。
误判兜底:用户反馈是最快的纠错信号。意图路由总会有误判。在每条回复末尾加一句:"我是 XX 助手,如果没有解决你的问题,输入'转人工'。"如果用户连发了两次"转人工",Orchestrator 不再做意图判断,直接升级到 Escalation Agent。让用户帮你的路由纠错,比你自己猜更准。
会话状态:用 Redis,别有状态部署。Orchestrator 不能是"有状态"的——如果这台 ECS 挂了,所有用户的会话上下文不能丢。会话状态统一放 Redis,Orchestrator 只从 Redis 读,不自己存。这样 Orchestrator 被 SLB 摘除换一台,用户会话无缝接上。
部署到云——关键配置与决策
网络规划
VPC: 172.16.0.0/16
├── 可用区 A 交换机: 172.16.1.0/24
│ ├── Orchestrator Agent(ECS)
│ ├── Knowledge Agent × 1(ECS)
│ ├── Ticket Agent × 1(ECS)
│ ├── Escalation Agent(ECS)
│ └── RDS 主库
├── 可用区 B 交换机: 172.16.2.0/24
│ ├── Knowledge Agent × 1(ECS)
│ ├── Ticket Agent × 1(ECS)
│ └── RDS 备库
└── 安全组:
├── SG-SLB:公网 443 开放
├── SG-Agent:仅接受 SLB + 内网,出站可访问 ES/RDS/Redis
├── SG-DB:仅接受 SG-Agent 流量
└── SG-ES:仅接受 SG-Agent 流量弹性伸缩策略
伸缩组 | 最小实例 | 最大实例 | 触发条件 | 冷却时间 |
|---|---|---|---|---|
Knowledge Agent | 2 | 6 | CPU > 70% 持续 2 分钟 | 300 秒 |
Ticket Agent | 2 | 8 | CPU > 70% 持续 1 分钟 | 180 秒 |
Orchestrator | 1 | 1 | 不伸缩 | — |
Escalation | 1 | 1 | 不伸缩 | — |
为什么 Ticket Agent 的冷却时间比 Knowledge 短?因为 Ticket 的流量尖刺更陡——大促秒杀时物流查询瞬间暴增,需要在 3 分钟内完成扩容。Knowledge 的流量增长更平稳。
健康检查与故障切换
SLB 健康检查: - 路径:GET /health - 间隔:5 秒 - 超时:3 秒 - 健康阈值:连续 3 次成功 - 不健康阈值:连续 3 次失败(15 秒后摘除)Agent 故障场景与恢复: - Orchestrator 挂了 → SLB 摘除 → 弹性伸缩自动重建 - Knowledge Agent 挂了 → SLB 摘除那个实例 → 另一个 AZ 的实例继续服务 - RDS 主库挂了 → 自动切到备库(高可用版,切换时间 < 30 秒) - DeepSeek API 不可用 → Orchestrator 检测到 Knowledge 返回异常 → 全员降级走规则引擎高可用验证——不验证,高可用就是纸上谈兵
架构师不能画完图就交给运维。高可用策略是自己设计的,必须自己验证。
实验一:停一个 Agent 实例——验证跨可用区高可用
操作:在控制台手动停止某个可用区的 Knowledge Agent 实例。
观察点:
- SLB 健康检查从发现异常到摘除实例,需要经历几次探测失败(取决于你配置的间隔和阈值)
- 摘除瞬间,SLB 将流量全部切到剩余健康实例——用 curl 持续探测 /chat 端点,看是否有请求失败
- 正常情况下,应在健康检查配置的时间窗口内完成切换,用户无感知
验证了什么:跨 AZ 部署 + 健康检查配置的生效链路。如果这里出了 5xx,说明健康检查间隔太宽、者阈值太松、或者 SLB 配置有问题。
实验二:压测触发弹性伸缩——验证自动扩缩容策略
操作:用压测工具模拟高并发场景,逐步加大 Ticket Agent 的查询负载。
观察点:
- 起始:实例正常负载,CPU 平稳
- 加压:CPU 持续攀升,触发你设定的伸缩规则(CPU 阈值 × 持续时长)
- 扩容中:新实例从启动到通过健康检查、接入 SLB 需要一定时间——这段时间所有流量压在老实例上,用户感知为响应变慢但不应该有 5xx
- 扩容完成后:CPU 回落到正常区间
- 减压后:负载回落到基线以下并持续一段时间,自动触发缩容,回到原始实例数
验证了什么:
- 伸缩规则(阈值 + 持续时间)是否合理——触发太灵敏会频繁扩缩,太迟钝用户已经感知到卡顿
- 冷却时间设得够不够——如果还没冷却完又来一波尖刺,会不会扩不动
- Ticket Agent 独立扩容的策略是否真的奏效——Knowledge Agent 不受影响,说明拆分是值的
实验三:模拟 LLM API 不可用——验证降级兜底策略
操作:在代码中注入故障,让 Orchestrator 调用模型 API 时收到连续错误(如 503/超时)。
观察点:
- Orchestrator 的熔断逻辑是否生效——连续失败达到阈值后,是否自动切换到降级模式
- 降级模式行为是否正确:不走 LLM,走规则引擎做关键词匹配 FAQ——匹配率不如 LLM,但系统还能顶住
- 规则匹配不到的问题,是否能正确转人工
- 当 API 恢复后,Orchestrator 是否能自动从降级模式切回正常模式
验证了什么:
- 降级逻辑不是写在文档里的,是跑在代码里的
- 用户体验会下降,但不会"客服系统挂了"——这是底线
- 降级模式下的转人工排队会不会被打爆——如果会,说明人工兜底策略也要跟着调整
三个实验跑完,架构师才知道自己的设计是不是对的。不跑实验的高可用方案 = 假设。假设不会帮你扛线上故障。
但是,拆了不是万事大吉——多 Agent 带来了三个新问题
架构决策没有免费午餐。三个条件告诉你"该拆",但拆完之后你要直面三个新问题。知道它们是什么、怎么缓解,这个决策才是完整的。
延迟叠加:一次请求要经过多个 Agent
单 Agent 时代,用户输入 → Agent → 输出,一个 LLM 调用搞定。拆了之后:用户输入 → Orchestrator(LLM 分类)→ Knowledge Agent(RAG 检索 + LLM 生成)→ 用户。串行两跳,每跳都是网络延迟 + LLM 推理时间。
缓解手段:
- Orchestrator 用规则 + 小模型,把这跳的延迟压到最低
- Orchestrator 把结构化上下文提前传给下游,下游不需要再解析一遍自然语言
- 异步预热:Orchestrator 分类的同时,并行调下游 Agent 的空闲连接,省一次 TCP 握手
调试变难:问题出在哪个 Agent?
单 Agent 时,用户说"这个回答不对",你打开日志看一条 Prompt 就够了。多 Agent 下,回答不对可能是 Orchestrator 分错类、可能是 Knowledge Agent 检索结果不相关、也可能是 Escalation Agent 误触发了。定位问题变成排错链:查 Orchestrator 的路由日志 → 查下游 Agent 的输入上下文 → 看是不是上游传错了信息。
缓解手段:
- 每个 Agent 的输出带上
trace_id,串联整条链路 - Orchestrator 的路由决策单独打一条结构化日志:
{输入, 路由结果, 置信度, 规则or LLM} - 如果某个 case 翻车了,能一键看到它是被哪个 Agent 带偏的——而不是三四个 Agent 的日志散在各处手动 grep
上下文传递有损耗:翻译过程中的信息丢失
Orchestrator 把"我的虾到了但死了,我要退款"翻译成结构化上下文时,丢失了语气(愤怒程度)、丢失了隐含意图(用户可能在暗示常客身份——"又是这样,上次也是你们")。下游 Agent 拿到的是一份"干净的摘要",而不是用户的原始表达。
这个损耗在某些场景下是致命的——比如 Escalation Agent 判断要不要转人工时,"语气"本身就是最重要的信号之一。
缓解手段:
- 结构化上下文 + 原始输入同时传给下游。下游既能快速解析结构,又能在需要时回溯原文
- 关键信号(情绪、紧急程度)在翻译时必须保留,不能被"结构化"过滤掉
- 设置几个必传字段:情绪标签、是否提及投诉历史、是否追问了三次以上
总结
拆分决策不是技术偏好,是三个条件的判断:Prompt 维护成本、模型差异化节省成本、独立扩容的经济性。三个全中才拆,一个不沾别拆。拆之前就想好代价——延迟叠加怎么压、调试链路怎么串、上下文传输什么东西不能丢。
部署决策不是运维的事,是架构师的事:每台 ECS 为什么选这个规格、弹性伸缩为什么配这个阈值、健康检查为什么设 3 次而不是 5 次——每个数字有依据。
高可用不是"配置了就完了",必须亲手验证:停实例看流量切换、压测看自动扩容、模拟故障看降级兜底。三个实验跑通了,你才敢跟客户说"这个系统能扛住大促"。
本篇产出:Agent 拆分决策框架(三个条件 + 不该拆的三种场景 + 拆后的三个代价)+ MumuMall 多 Agent 架构图 + Orchestrator 设计要点 + 阿里云部署配置 + 高可用验证报告。
下一篇:做完了,接下来你怎么把这一套复制到自己的项目里?你自己的转型路线图——L1 到 L5 每步做什么。还有,客户问你"我们该不该上 AI",你给他一个三阶段的采纳框架。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号