
利用.style在熊猫数据帧中有条件地格式化单元格
提问于 2022-08-21 14:57:31
我试图使用.style对实际数字小于'Budget'列的记录进行有条件的格式化。
我尝试使用以下代码:
percent_scrap = (percent_scrap.style
.format("{0:,.2f}%")
.apply(lambda x: x == 'background-color: red'
if x > x['Bud Yield']
else '',
axis = 1
)
)但是lambda函数会产生错误:
系列的真值是不明确的。使用a.empty、a.bool()、a.item()、a.any()或a.all()。
我尝试创建一个“掩码”数据格式,将False映射到'background-color: red',然后将其传递给style函数,但也想不出如何正确地做到这一点。
我肯定还有更好的办法。
期望产出:
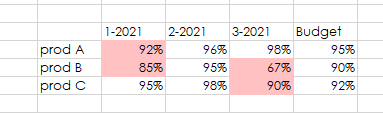

回答 2
Stack Overflow用户
回答已采纳
发布于 2022-08-22 12:43:59
您的lambda函数混合返回一个元素和一个数组对象的测试,因此出现了错误。
你最好使用这样的方法:
styler.apply(lambda s: np.where(s>df["budget"], "color:red", None), axis=0)这将将每一列计算为一个系列,即s,与dataframe列budget进行比较,并返回要应用于每一列的样式数组。
可以修改apply方法以排除budget列:
styler.apply(lambda s: np.where(s>df["budget"], "color:red", None), axis=0, subset=[col for col in df.columns if col != "budget"])Stack Overflow用户
发布于 2022-08-23 03:54:19
我终于想明白了:
percent_scrap = (percent_scrap.style
.apply(lambda x: ["color:red; font-weight:bold" if v < x.iloc[-1] and v != 0 else "" for v in x],axis = 1)
.format("{0:,.2f}%")
)这使我能够根据最后一列中的值格式化dataframe中的所有列。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73438775
复制









腾讯云开发者

