AzureSynapse管道如何向原始数据添加guid
AzureSynapse管道如何向原始数据添加guid
提问于 2022-09-07 23:53:31
我是AzureSynapse的新手,从技术上讲,我是一名从事数据工程任务的数据科学家。请帮帮我!
我有一些xlsx文件,其中包含需要导入到SQL数据库表中的原始数据。问题是原始数据没有uniqueidentifer列,在将数据插入到SQL数据库之前,我需要添加一个列。
通过在Copy命令上添加一个新列并将其设置为@guid(),我成功地将所有行添加到表中。但是,这会将每行的guid设置为相同的值(并非每一行都是唯一的)。
GUID绘图:
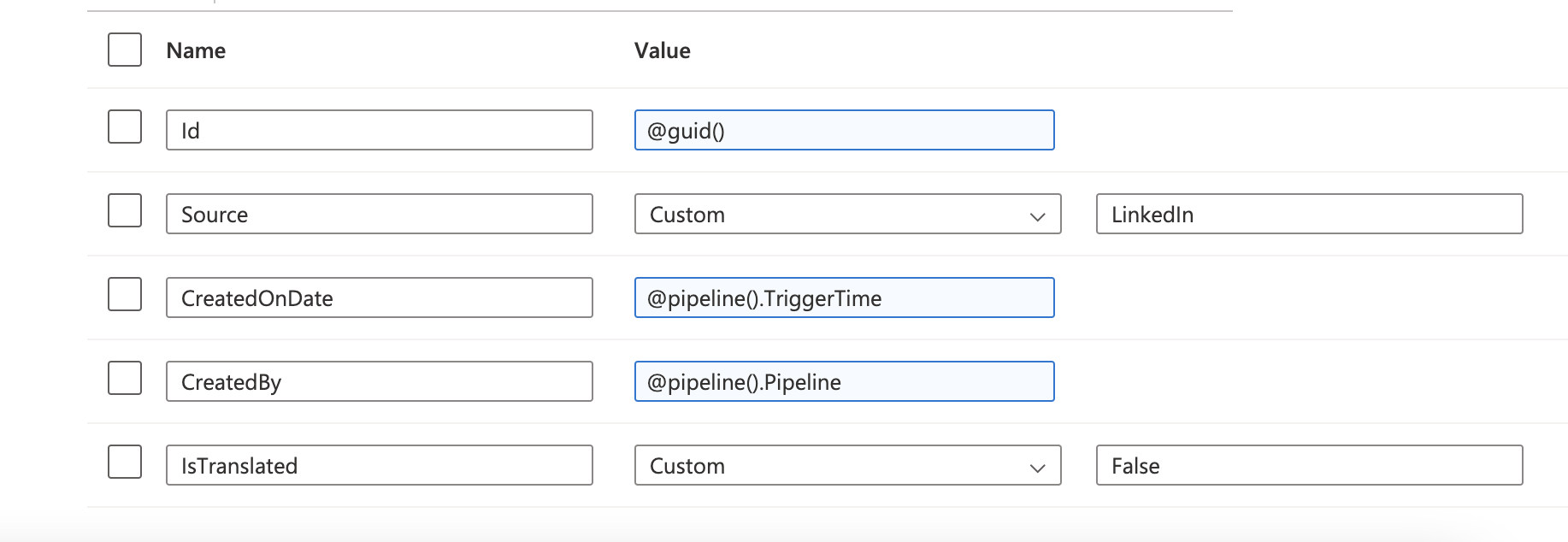
DB结果:

如果我不添加此映射,则管道会抛出一个错误,说明它不能将空Id导入列Id。这是有意义的,因为该列不接受空值。
是否有一种方法可以让AzureSynapse分析方法在原始xlsx文件中读取,然后将其导入到我的数据库中,并为每一行设置一个唯一标识符?如果是这样,我怎样才能做到这一点呢?
非常感谢大家的支持。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-08 03:21:52
以这种方式将动态内容提供给列的
- 将为整个生成相同的值,您可以使用
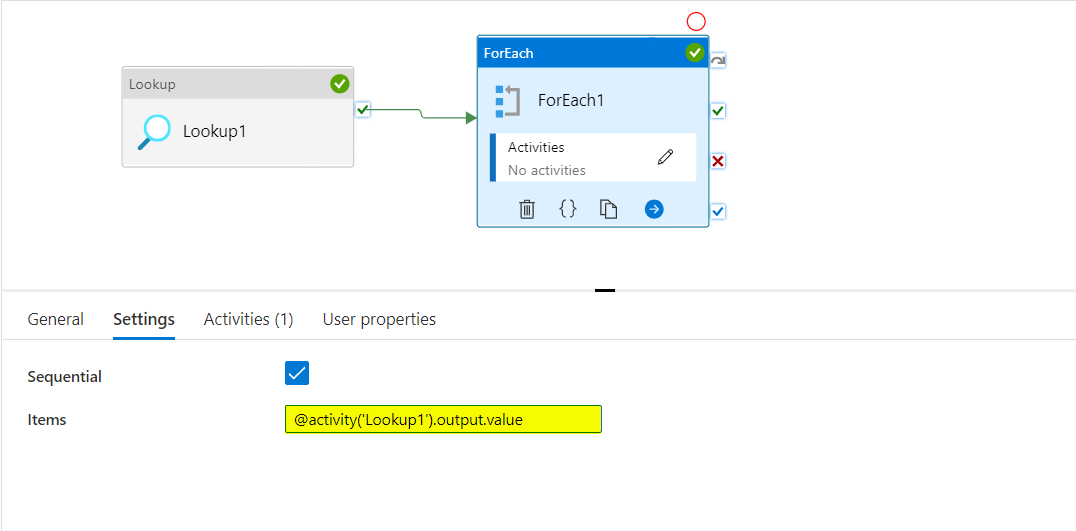
for each活动为每一行生成一个新的guid。- 可以使用
lookup活动从源Excel文件中检索数据(我的源只有name列)。将查找活动的输出数组赋予for each活动.
- 可以使用
@activity('Lookup1').output.value
- you
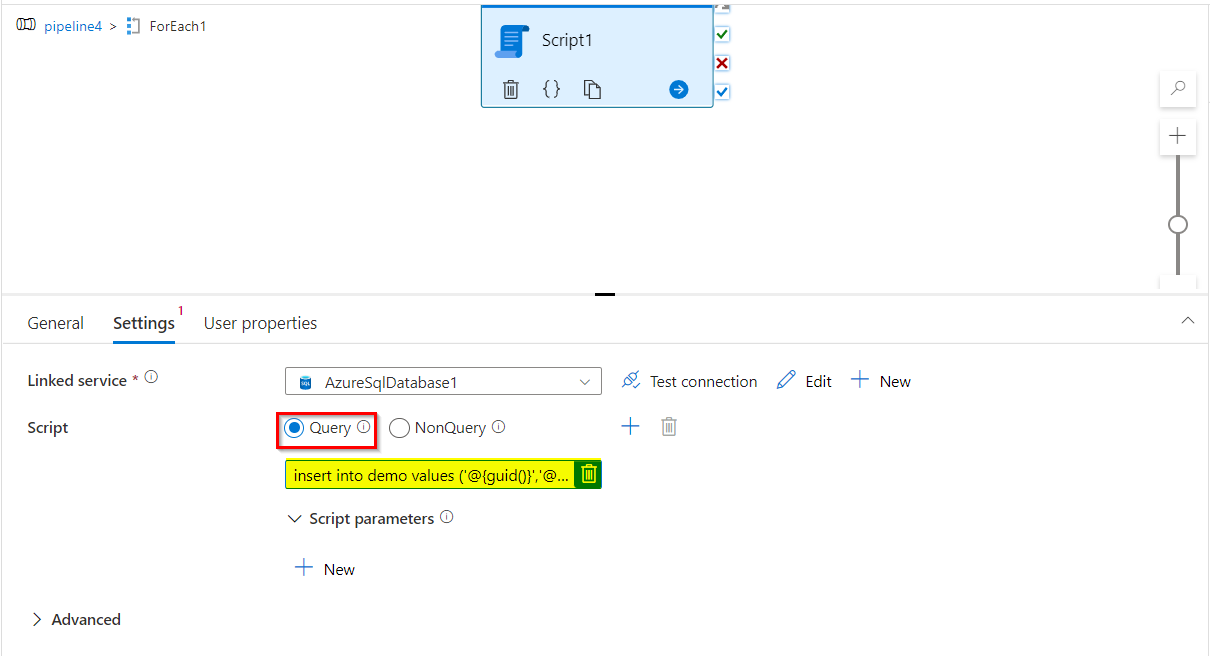
for each,因为您已经有了一个链接服务,所以创建一个脚本活动。在此脚本活动中,可以创建具有动态内容的查询,以便将值插入目标表。下面是我使用动态内容构建的查询.
insert into demo values ('@{guid()}','@{item().name}')
这允许您迭代源行,分别插入每一行,同时生成每个time的新guid。
您可以按照上述过程构建一个查询,以插入具有唯一标识符值的每一行。下面是一个图像,在该图像中,我使用复制数据插入前2行(与您的数据相同),并使用上述过程插入接下来的2行。
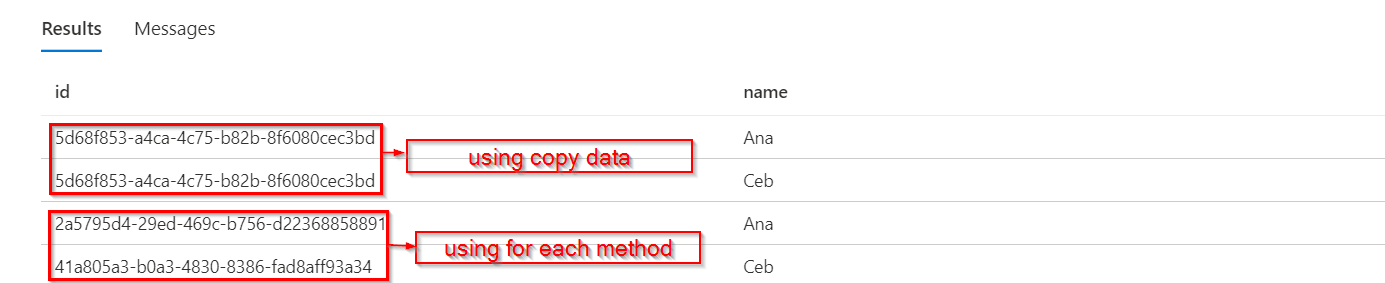
注意:我已经使用Azure数据库作为演示,但这不影响过程。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73645504
复制相关文章


相似问题
从ASP.Net应用程序LINQ到MS Access数据库?
使用VBA从Access应用程序使用ASP.NET VBA服务
使用Access数据库的ASP.NET
使用ASP.net和Access数据库从保护网站
使用ASP.NET连接到Access数据库
添加站长 进交流群
领取专属 10元无门槛券
AI混元助手 在线答疑

关注 腾讯云开发者公众号
洞察 腾讯核心技术
剖析业界实践案例

腾讯云开发者

