LaDI-VTON


LaDI-VTON: Latent Diffusion Textual-Inversion Enhanced Virtual Try-On
- paper https://arxiv.org/abs/2305.13501
- code https://github.com/miccunifi/ladi-vton

image-20230807102743722
Abstract
- a latent diffusion model (LDMs) extended with a novel additional autoencoder module that exploits learnable skip connections to enhance the generation process preserving the model’s characteristics 使用可学习跳层连接的自编码器模块和隐扩散模型可以提高生成过程中模特特征的保留率
- a textual inversion component that can map the visual features of the garment to the CLIP token embedding space and thus generate a set of pseudo-word token embeddings capable of conditioning the generation process 文本反演组件可以将衣服的视觉特征映射到CLIP的token嵌入空间,因此生成一套伪词tocken嵌入,从而能够影响生成过程,进而保留衣服的纹理和细节
Contributions
- 首次使用隐扩散模型LDMs
- 通过具有跳层连接的自编码器保留修复区域外的细节
- 定义了前向纹理反演模块进一步保留生成过程中输入衣服的纹理信息
- 在Benchmarks(DressCode & VITON-HD)上取得SOTA
Related Work
- Image-Based Virtual Try-On
- VITON coarse2fine, TPS, encoder-decoder arch
- learnable TPS, GANs, DMs
- Diffusion Models
- text-to-image synthesis
- image-to-image translation
- image-editting
- inpainting
- 和虚拟试衣最相关的task是人体图像生成
- Textual Inversion
- Textual inversion is a recent technique proposed to learn a pseudo word in the embedding space of the text encoder starting from visual concepts.
Methodology
基于Stable Diffusion架构,为了增强文图生成模型虚拟试衣的能力,修改了网络结构使得输入为衣服和模特的姿态,同时为了保留衣服细节,提出了前向textual inversion,最后使用masked skip connections提升SD的图像重建自编码器,从而提高了图像生成质量且更好地保留了模特图的细粒度细节。
- Stable Diffusion 文图生成模型
- CLIP 视觉-语言模型,将二者特征对齐到一个共享的特征空间
Overview
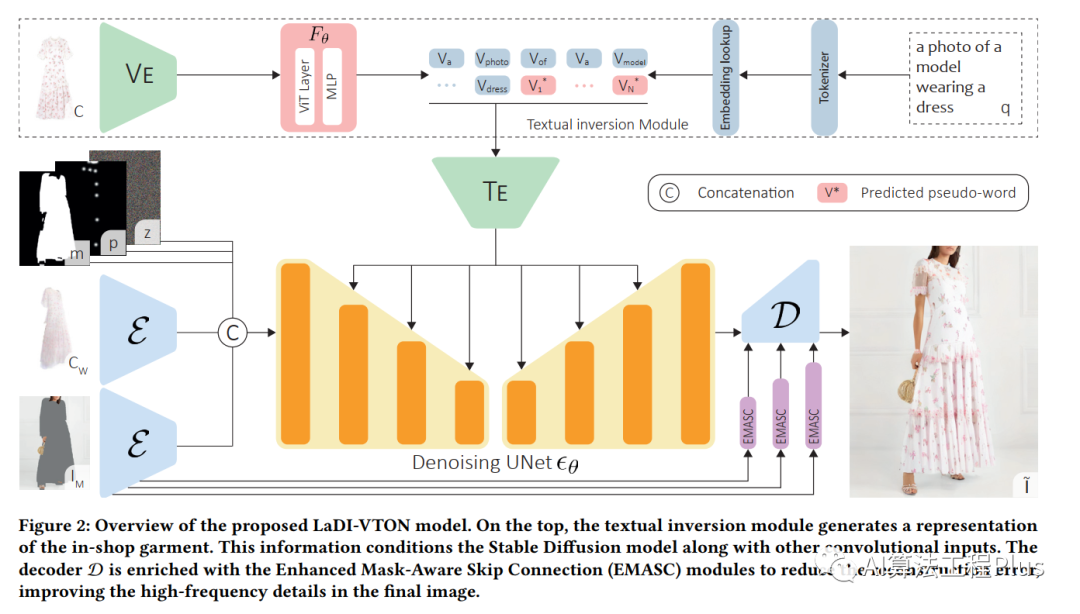
image-20230808135322123
Textual Inversion
- 纹理反演:输入图像,预测CLIP token特征空间中pseudo-word
- q: 文本提示,通过CLIP变换到特征空间得到true-word
- VE (visual encoder): OpenCLIP ViT-H/14 model pre-trained on LAION-2B
- 单层ViT + 3层MLP + GELU激活 + dropout
Diffusion Virtual Try-On Model
- 选择SD的inpainting pipeline
- 输入 textual-inverted information 𝑌ˆ of the in-shop garment, the pose map 𝑃, and the garment fitted to the model body shape 𝐶𝑊 (the warped garment)
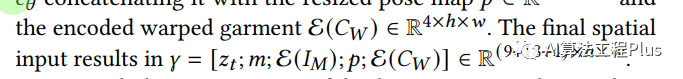
image-20230808150225064
Enhanced Mask-Aware Skip Connections
- EMASC
- 作用于masked image(mask from inpainting)
- 目的是学习传播编解码器对应的相关信息

image-20230808143928254

image-20230808144304322
CLOTHES WARPING PROCEDURE
coarse2fine
- step1coarse warping
- Toward characteristic-preserving image-based virtual try-on network.
- TPS:把cloth变形到model的pose和mask shape匹配
- step2 refine warping
- U-Net: Convolutional Networks for Biomedical Image Segmentation.
- U-net: 输入coarse garment, pose, model,输出target warped garment (GT)
Experiments
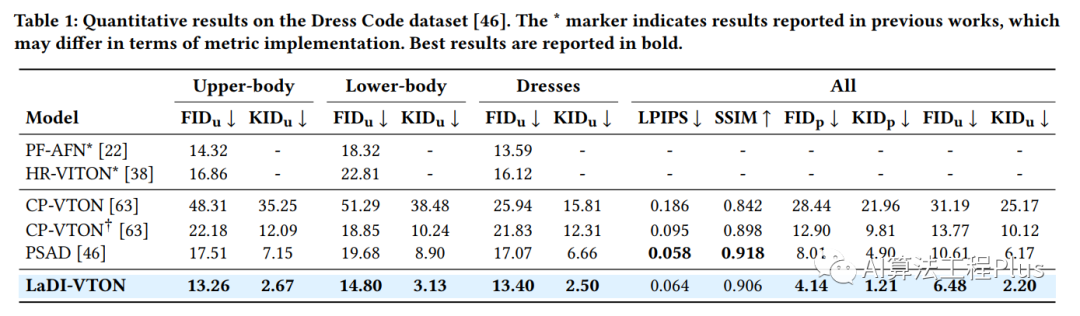
image-20230808144448627
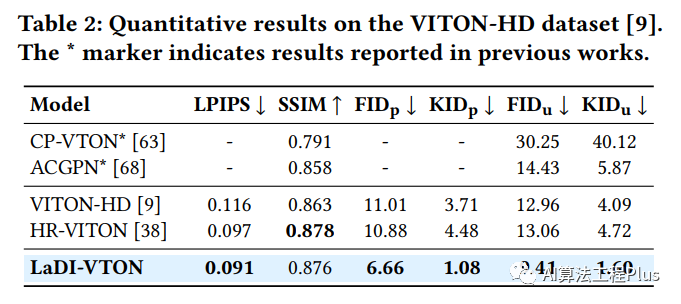
image-20230808144457075

image-20230808151741401
Conclusions
- 第一个基于LDMs的try-on
References
- Stable Diffusion pipeline
- https://huggingface.co/stabilityai/stable-diffusion-2-inpainting
- Textual Inversion: An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- https://arxiv.org/abs/2208.01618
- https://textual-inversion.github.io/
- LDMs: High-Resolution Image Synthesis with Latent Diffusion Models
- https://arxiv.org/abs/2112.10752
- https://github.com/CompVis/latent-diffusion
- CLIP: Learning Transferable Visual Models From Natural Language Supervision
- CLIP (Contrastive Language-Image Pre-Training)
- https://arxiv.org/abs/2103.00020
- https://github.com/OpenAI/CLIP
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-08 17:35,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 iResearch666 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号