CVPR2024 | 进一步提升超分重建质量,中科大提出用于图像超分的语义感知判别器SeD,即将开源

CVPR2024 | 进一步提升超分重建质量,中科大提出用于图像超分的语义感知判别器SeD,即将开源

AIWalker
发布于 2024-03-07 16:24:09
发布于 2024-03-07 16:24:09

https://arxiv.org/abs/2402.19387 https://github.com/lbc12345/SeD
本文概述
生成对抗网络(GAN)已被广泛用于恢复图像超分辨率(SR)任务中的生动纹理。判别器使 SR 网络能够以对抗性训练的方式学习现实世界高质量图像的分布。然而,这种分布学习过于粗粒度,容易受到虚拟纹理的影响,导致生成结果违反直觉。
为了解决这个问题,我们提出了一个名为 SeD 的简单而有效的语义感知判别器,它鼓励 SR 网络通过引入图像语义作为条件来学习更细粒度的分布。具体来说,我们的目标是从训练有素的语义提取器中挖掘图像的语义。在不同的语义下,鉴别器能够自适应地单独区分真假图像,从而引导 SR 网络学习更细粒度的语义感知纹理。为了获得准确和丰富的语义,我们充分利用最近流行的具有广泛数据集的预训练视觉模型(PVM),然后通过精心设计的空间交叉注意模块将其语义特征合并到鉴别器中。通过这种方式,我们提出的语义感知鉴别器使 SR 网络能够生成更加逼真和令人愉悦的图像。对两个典型任务(即 SR 和RealSR)的大量实验证明了我们提出的方法的有效性。
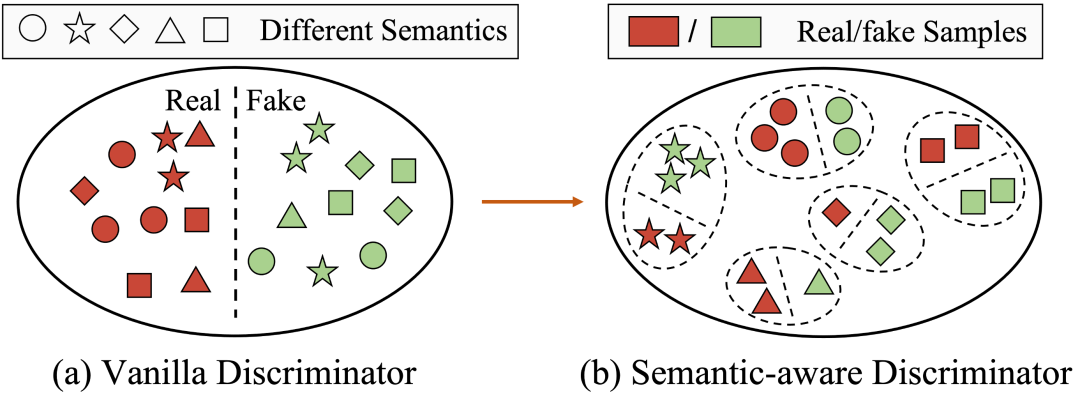
本文贡献
- 我们指出了细粒度语义感知纹理生成对于 SR 的重要性,并通过将预训练视觉模型 (PVM) 的语义合并到判别器中,首次提出了用于 SR 任务的语义感知判别器 (SeD) 。
- 为了更好地结合鉴别器的语义指导,我们提出了SeD的语义感知融合块(SeFB),它提取像素级语义并通过交叉注意方式将语义感知图像特征扭曲到鉴别器中。
- 对两种典型 SR 任务(即经典图像 SR 和真实世界图像 SR)的大量实验揭示了我们提出的 SeD 的有效性。此外,我们的 SeD 可以以即插即用的方式轻松集成到基于 GAN 的 SR 方法的许多基准中。
本文方案
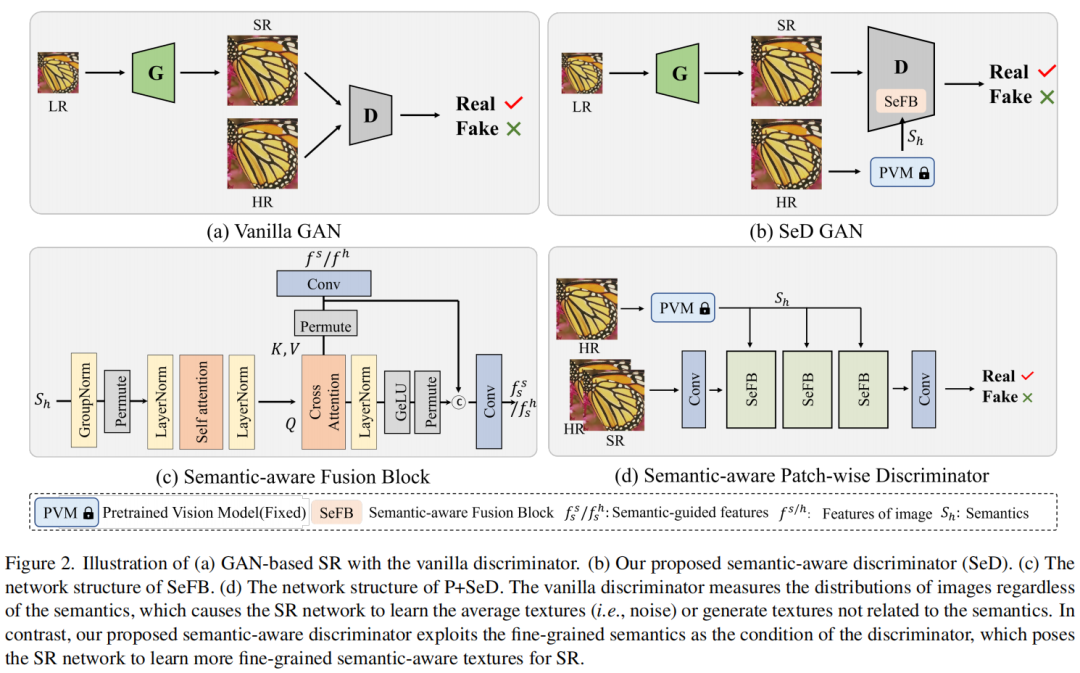
所提提出的语义感知鉴别器(SeD)的整体框架如图2所示。给定低分辨率图像
,我们可以首先获得超分辨率图像
。然后使用判别器𝐷来区分
和高分辨率图像
,强制 SR 网络生成类似真实的图像 。然而,普通判别器仅考虑图像的粗粒度分布,而忽略图像的语义。这将导致 SR 网络产生虚假甚至更糟糕的纹理。
一个有前途的纹理生成应该满足其语义信息。因此,我们的目标是实现语义感知鉴别器,它利用高分辨率图像
的语义作为条件。在这里,我们将大视觉模型作为语义提取器,表示为𝜙。我们的目标是实现更细粒度的语义感知纹理生成,其目标是
因此,如图2所示,高分辨率图像
将送入到固定的预训练语义提取器中提取语义
,然后SeFB模块对超分图像特征与高分辨率图像特征变换并送入到判别器中。基于语义感知特征,鉴别器可以实现语义感知分布测量。
Semantic Excavation
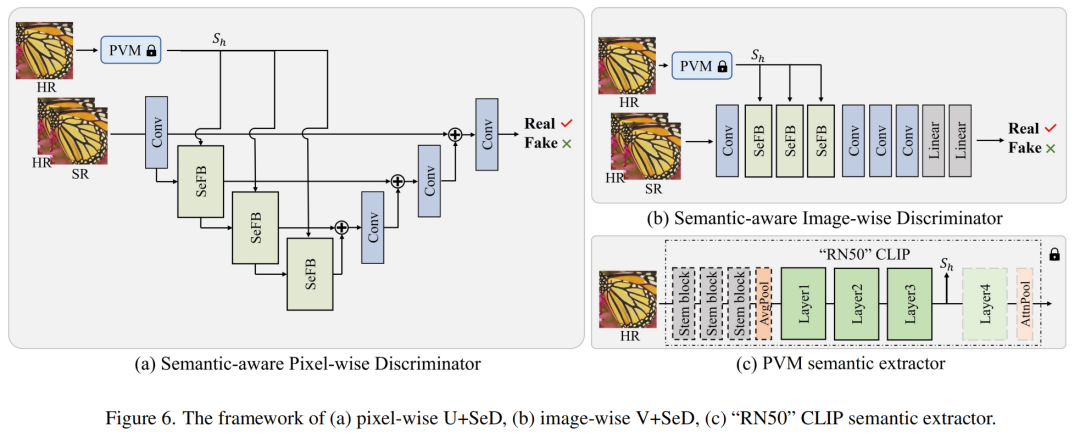
我们采用预训练的 CLIP“RN50”模型作为语义提取器。具体来说,“RN50”由四层组成,随着层数的增加,特征的分辨率被下采样,语义变得更加抽象。为了研究哪一层更适合我们的语义挖掘,我们系统地对这四层进行实验,并通过实验发现第三层的语义特征是最优的。
Semantic-aware Fusion Block
SeFB的架构如图2(c)所示,我们的目标是将语义感知纹理从图像扭曲到鉴别器,从而强制鉴别器聚焦关于语义感知纹理的分布。因此,在图 2(c) 中,语义
被传递到自注意力模块,然后作为查询馈送到交叉注意力模块.
Extension to Various Discriminators
在本文中,我们将提出的 SeD 合并到两个流行的判别器中,包括 patch-wise 判别器和 Pixel-wise 判别器。如图 2(d)所示,分片语义感知鉴别器由三个 SeFB 和两个卷积层组成。对于逐像素鉴别器,我们遵循中的方法并利用 U-Net 架构作为主干。我们在浅层特征提取阶段用我们提出的 SeFB 替换原始卷积层。
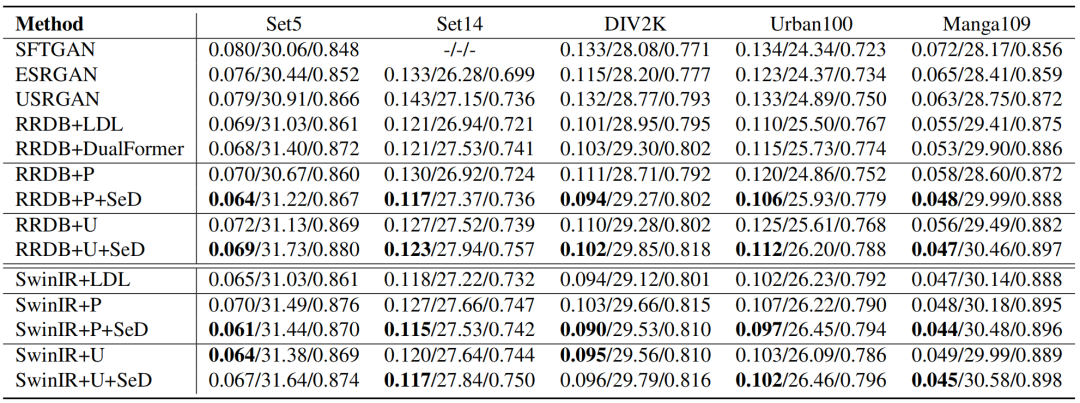
本文实验



本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号