华为发布diffusion图像新模型PIXART-Σ,图片成品清晰度4K,对比Dall3、MJ V6效果突出!

华为发布diffusion图像新模型PIXART-Σ,图片成品清晰度4K,对比Dall3、MJ V6效果突出!

开源星探
发布于 2024-03-18 17:31:02
发布于 2024-03-18 17:31:02
前言
这两年,文本到图像生成模型 的需求不断增长,但高质量图像的生成往往面临资源密集型训练和慢推理的挑战,制约了其实际应用。
在年前,华为就发布了一款图像生成新框架PIXART-δ,引入ControlNet,加速文本生成图像生成,可以在 8GB GPU 上合成 1024px 图像,大大增强了其可用性和可访问性!
PIXART-δ 为SD模型系列提供了一种有前途的替代方案,而这不到2个月的时间华为诺亚方舟实验室又发布新一代图形生成模型PIXART-Σ。
不得不说华为真的是取名鬼才,把数学符号用到极致了。
PIXART-Σ 新模型更是可以生成 4K 图像。

项目介绍
PIXART-Σ 是华为诺亚方舟实验室联合香港大学、大连理工等共同研发的一款用于 4K 文本到图像生成的新模型。
相较于前身PixArt-α,它提供了更高的图像保真度和与文本提示更好的对齐。
PIXART-Σ的关键特性包括高效的训练过程,它通过结合更高质量的数据,从“较弱”的基线模型进化到“更强”的模型,这一过程被称为“弱到强训练”。
PIXART-Σ的改进包括使用更高质量的训练数据和高效的标记压缩。
介绍地址:https://pixart-alpha.github.io/PixArt-sigma-project/
论文地址:https://arxiv.org/abs/2403.04692
体验地址:https://huggingface.co/spaces/PixArt-alpha/PixArt-LCM
主要功能:
- • 4K文本到图像生成:直接生成4K分辨率的高质量图像。
- • 弱到强训练过程:通过高质量数据训练,将模型从“较弱”进化为“更强”。
- • 高效的标记压缩:采用高效的标记压缩技术,提升训练效果。
效果展示
1.乐高模型,未来火箭站,复杂的细节,高分辨率,虚幻引擎,超高清

2.一个华丽的珊瑚礁纸艺世界,充满了色彩缤纷的鱼类和海洋生物。

3.浮世绘,宇航员骑着独角兽,背景是日本古代建筑。

4.越肩游戏视角,暗黑破坏神4的游戏画面,华丽的宫殿内是湿漉漉的地面,死灵法师跪在国王面前,他召唤的一大群骷髅站在他身边,电影般的光芒。

5.扎哈·哈迪德 (Zaha Hadid) 设计的一座靠近大海的弯曲木屋,代表着冰冷的现代建筑形象,夜晚,白色灯光,细节丰富。

更多
并且与目前主流的绘画工具做了,同样Prompt的成品对比。效果显著。
细节凸显,画质4K。
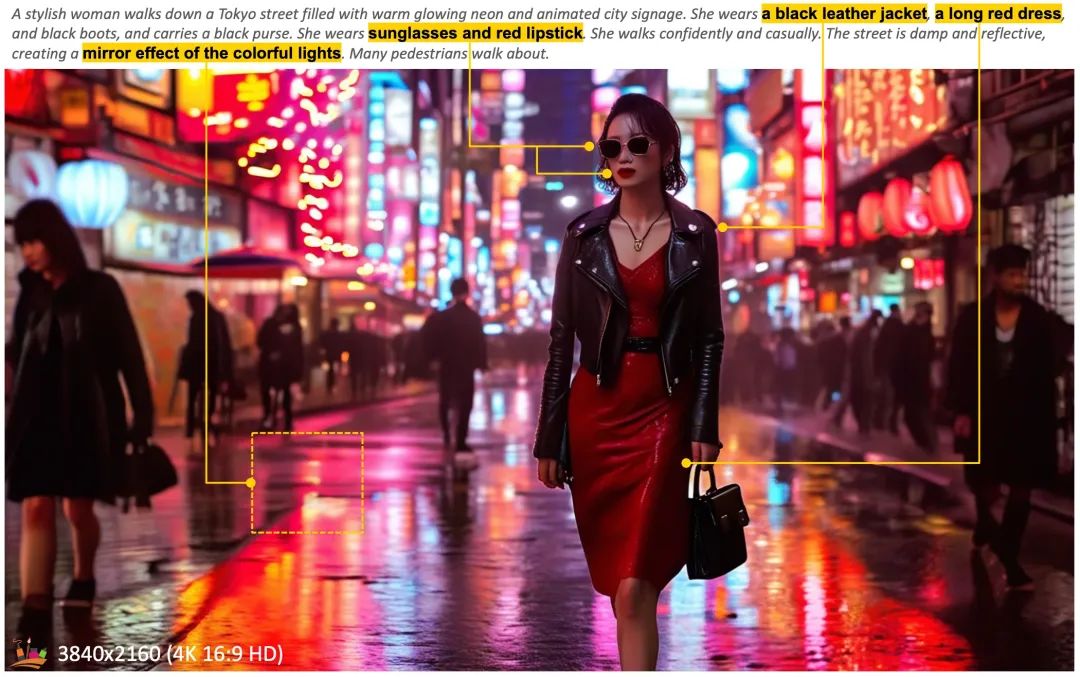
多产品维度对比

总结
PixArt- Σ 实现了卓越的图像质量和用户提示功能,同时模型大小(0.6B 参数)明显小于现有的文本到图像扩散模型,如 SDXL(2.6B 参数)和 SD Cascade(5.1B 参数)。
此外,PixArt- Σ 能够生成 4K 图像,支持制作高分辨率海报和壁纸,可有效促进电影和游戏等行业高质量视觉内容的生产。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号