[并行训练]Context Parallelism的原理与代码浅析

[并行训练]Context Parallelism的原理与代码浅析

BBuf
发布于 2024-06-03 21:20:25
发布于 2024-06-03 21:20:25
作者丨kaiyuan
来源丨https://zhuanlan.zhihu.com/p/698447429
编辑丨GiantPandaCV
Context Parallelism/Context Parallel简称'CP' 是序列(sequence)并行的一种方式,针对Self-attention模块计算在sequence维度并行的功能。在Megtron-LM框架中,CP实现主要思想有两点:
- 用Flash-attention2方式进行分块运算, 最后对分块结果进行修正。
- 设备之间用ring的方式传递KV值来获得分块运算的结果,原理类似ring-attention;
从公开资料和代码(截止2024.4.30)来看CP功能可能还需要进行一些迭代来完善,这里不讨论其性能的优劣,主要介绍其原理(主要是forward过程),供大家参考。其主要步骤如下如下图所示,包括:
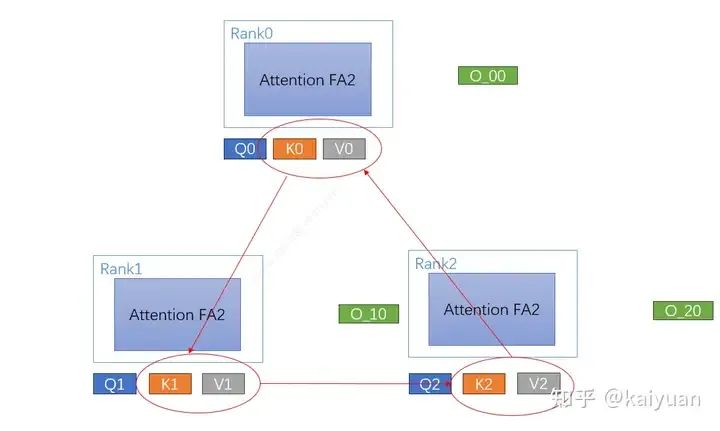
- 数据切分:根据cp_size(示例=3)大小,将数据切分,每个rank拿到对应分片数据;
- 分块attention计算:计算分块数据的self-attention值(图中用FA2计算),获得单步数据;
- KV数据交换:rank之间搭建ring网络结构,每个rank与相邻rank交换KV数据;
- 单步计算修正:计算完attention后,需要对输出中间值L进行修正,保证输出正确;
- 计算最终输出:算完所有的分块attention后,对最终结果O进行修正、合并。
每个rank拿到分块结果O_与不采用CP并行的结果O对应部分相等;步骤2与3可以同时进行。
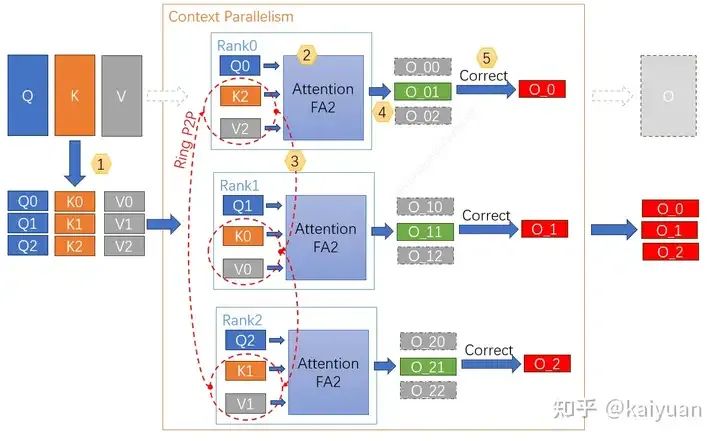
CP计算流程
相关问题:
- Attention内部KV数据交换采用的通信的方式?通过P2P完成,参看:3.3
- 如何实现负载均衡?数据对称重组,并移除causal masking中不必要的计算,参看:2.1
- 分块FA计算为何需要修正?分块计算与原结果不相等,需要单步修正,参看:2.2
- 计算与通信如何掩盖?设置两个stream交替工作,参看:3.1
1 基本原理
先回顾一下Megtron的SP(Sequence Parallelism)操作,SP完成sequence维度的并行,覆盖操作包括LayerNorm、Dropout、FC,但不能切分self-attention模块。如下图所示在SP/TP的组合中案例中,self-attention计算前聚合(all-gather)了sequence的内容。
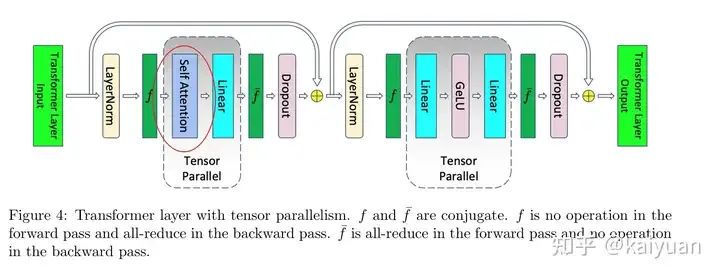
Self-attention的计算里面为什么需要完整的序列?Attention中QKV的计算需要用到一个完整sequence信息,计算上的耦合使得该模块不能先运算后进行简单拼接。
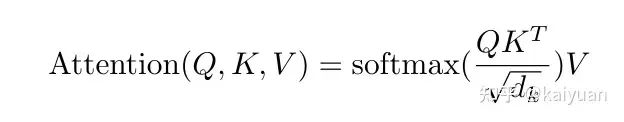
attention计算公式
Context Parallelism解决SP中未完成的self-attention序列并行问题。
整体计算的self-attention的输入为:Q(query)、K(key)、V(value)、以及Mask值,如下所示,数据经过FA2计算后得到输出O。
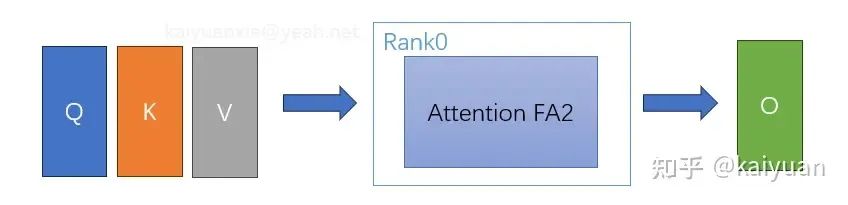
未使用cp的计算
开启cp并行,首先需要对输入QKV进行切分。QKV在sequence维度上,均需要除以cp_size值。这里以"bshd"数据类型举例,Q/K/V的输入shape由
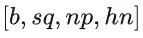
变为[b, sq/cp_size, np, hn] 。下面以cp_size=3举例,CP的运算主要步骤:
数据切分:Q/K/V拆分成数据
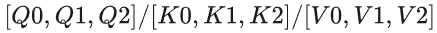
,CP设备组分为rank0、rank1、rank2,每个rank拿到固定[b, sq/3, np, hd]大小数据Q;
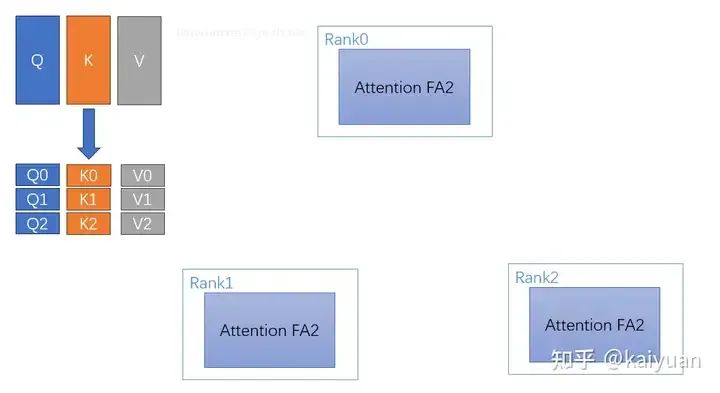
Attention计算:第一次计算时,rank拿一份K、V数据,比如rank0拿到K0,V0。计算通过FA(FlashAttention)2模块完成获得第一个输出O_00。除第一次外,后续的QKV计算中,单步计算后需要进行一次对说L值的修正(FA计算中的L logsumexp值)。
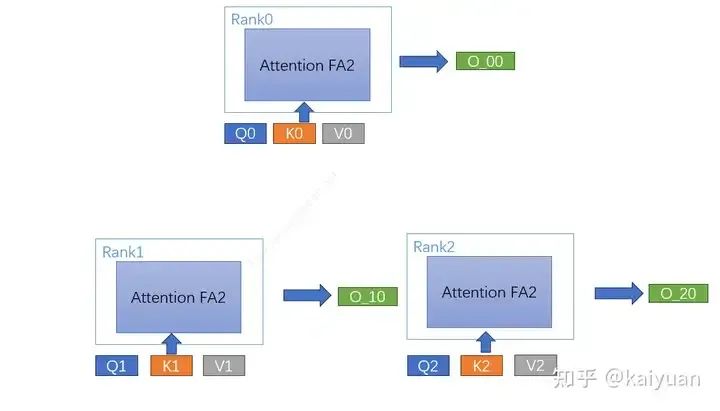
KV数据交换:计算的同时,可以进行数据交换。每个rank与相邻的rank进行环形P2P通信,传出自己的KV值,同时拿到下一次需要运算的数据,一共需要完成 CP-1 次通信。如rank0,算完K0,V0后下次需要运算的数据为K2, V2,从rank2获取;同时,rank0将K0V0数据传递给rank1。
单步计算修正:每一个分块的QKV计算后进行一次结果修正(FA计算中的L logsumexp值);
计算最终输出:每个rank的Q与KV匹配计算完后获得三个输出值,然后进行结果修正得到[O_X0, O_X1, O_X2],X值为rank序号。最后每个rank将自己的分块结果进行聚合(加法)运算得到结果O_X。
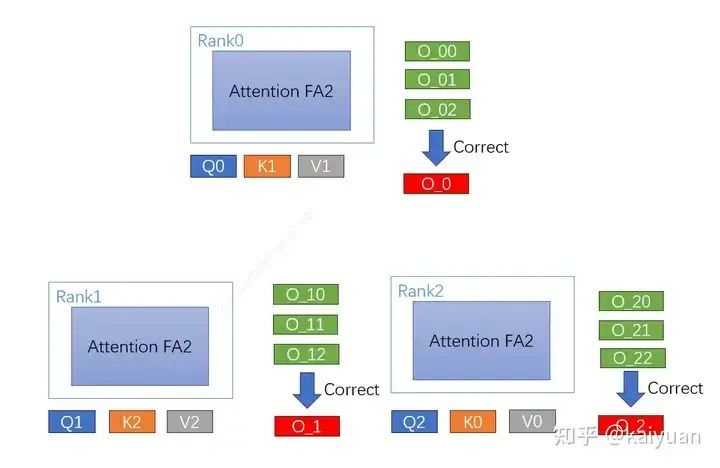
CP运算分部在每个rank上的[O_0, O_1, O_2],与不使用CP获得的结果[O] 数学相等。整体的运算过程如下图所示,每个设备rank的attention结果值的大小为
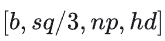
。
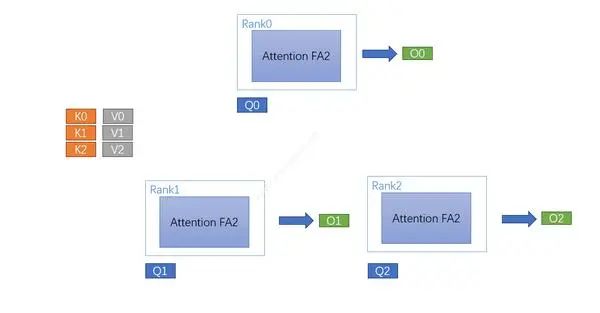
简单看一下CP对前向运算的计算量、内存、通信的影响:
计算量:CP切分的attention计算与整体的attention计算的计算量近乎一样,但多了 2CP-1 次修改操作;
通信量:增加了p2p通信,通信总量为
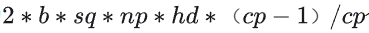
个单位
内存:假设每个rank只有一个buffer大小,QKV输入的显存变为
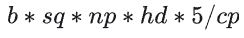
个单位
注意:实际Megatron代码中设置了cp数目个buffer用于操作KV值。buffer可以提升计算利用率,但也会增加显存量。
2 计算的变化
2.1 Casual Mask优化
对于casual mask的优化,cp里面采用一种数据对称重组的操作,然后运算时丢弃mask中的无效运算。
2.1.1 数据对称重组
Q/K/V在计算attention前需要进行seq/cp_size的等分操作,causal计算优化的时候多一步,就是将Q/K/V进行cp_size * 2的等分操作然后组合。还是以=3 举例,如下图所示,这里只需要看score的计算。
步骤1:将Q和K沿sequence维度等分成3 * 2 份,这样Q和K都有6份,序号[0, 1, 2, 3, 4, 5];
步骤2:然后对称取数据组合。比如Q0拿到数据块[0, 5]、Q1拿到数据[1, 4],K也是同样的处理,子块的数据大小依然为:seq/cp_size。
步骤3:由于要与计算数据映射,mask需要切成3*2 x 3*2 的形状,当不同子块Q与不同的子块K进行计算后要掩膜操作时,拿取的mask块是根据idx进行寻找,比如Q0 与K1的sub mask,需要的子块mask:01、51、04、54。mask子块的idx是Q与K的数据idx两两组合得到。
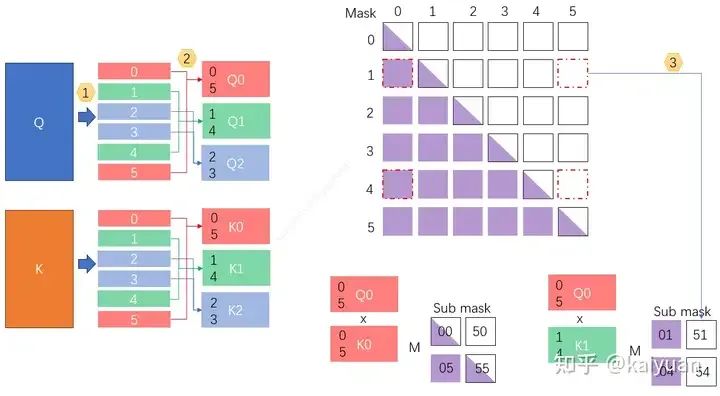
2.1.2 丢弃mask中的无效运算
在子mask的重组中,mask的形状只有三种如下图所示。而且根据对称数据组合的规律,在FA2内层循环计算中,sub mask第一个永远是a,接着是b,然后是c。
a依然是一个causal mask,b是左半部分需要计算,c是下半部分需要计算。这样在Q和K计算时,我们直接可以简化运算:将空白块丢弃,非空白块用无mask的运算。b和c的切换的分界判断是计算块索引i是否大于Q的rank id。
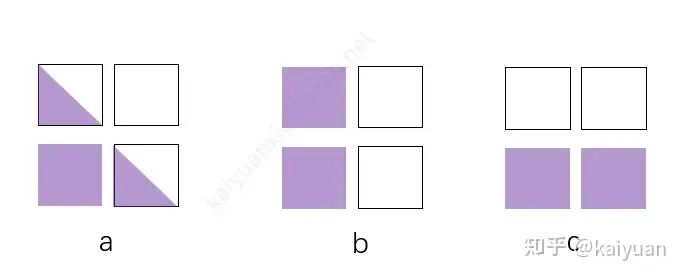
sub mask的类型
通过移除causal_mask非必要运算,具体操作是:
- 当QKV分块进行第一次运算时,按照causal模式的FA2计算;
- 当QKV分块计算循环次数i<= rank_idx时,KV丢弃sequence后半部分内容,进行“no_mask”的FA2运算;
- 当循环次数i>rank_idx时,Q值丢弃sequence前半部分内容,进行“no_mask”的FA2运算;
还是以CP=3的例子帮助理解,QKV切分
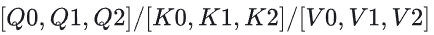
当rank 为1的设备进行FA2求解时,其计算具体步骤:
- 计算
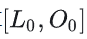
时,输入的Query的shape:[b, sq_cp, np, hn] , K和V的shape:[b, sq_cp, np, hn],FA2的mask=“casual”
- 计算
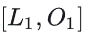
时,输入的Query的shape:[b, sq_cp, np, hn] , K和V的shape:[b, sq_cp// 2, np, hn],FA2的mask=“None”
- 计算
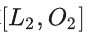
时,输入的Query的shape:[b, sq_cp//2, np, hn] , K和V的shape:[b, sq_cp, np, hn],FA2的mask=“None”
2.2 FA的修正计算
在Megatron的self-attention计算用的FA2原理,计算的步骤如下(Forward部分):





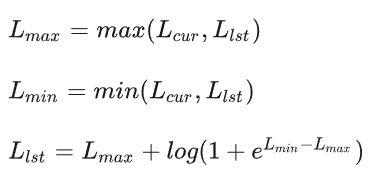


3 代码主逻辑的分析
这里分析的Megatron中CP的代码,位置:https://github.com/NVIDIA/TransformerEngine/blob/main/transformer_engine/pytorch/attention.py
版本V1.6,commit:c81733f1032a56a817b594c8971a738108ded7d0
CP的实现主要是用一个class AttnFuncWithCP(torch.autograd.Function)完成,在L514(代码质量写得比较冗余,可以自己抽取函数提升阅读性)
分块循环计算主要的逻辑如下:
# 主体循环在L587行, 完成cp_size+1操作,
for i in range(cp_size+1):
if i < cp_size: # L588 进行attention计算操作
# 选择双流中的一个,根据i交替使用。
# 完成P2P通信,使得rank之间的KV进行交换
# 根据数据类型处理数据 完成fused_attn_fwd计算
if i > 0: # L784 进行lse修改正操作,循环(1, cp_size+1)比计算步骤推迟一步
# 对fused_attn_fwd的结果lse进行修正
# 等待所有计算结束,对Out进行修正
for i in range(cp_size):
# 通过flash_attn_fwd_out_correction进行结果修正下面对代码里面一些关键逻辑进行分析。
3.1 双流交替运算
为了提升计算效率,代码里面创建了两个stream:
# create two streams to resolve wave quantization issue of Flash Attn in each stepflash_attn_streams = [torch.cuda.current_stream(), cp_stream]通过CP块索引的基偶数来切换stream:
with torch.cuda.stream(flash_attn_streams[i%2]) # 其中i为当前的计算快索引由于有双流,代码中建立的QKV都有双份,目的应该就是保证不同的流能够匹配到一份buffer,使得计算与P2P通信重叠操作。
# 输入buffer:# Flash Attn inputs
q_inputs = [None, None]
kv_inputs = [None, None]
attn_bias_inputs = [None, None]# 索引计算:
kv_inputs[i%2] # 其中i为当前的计算快索引3.2 FA代码的修改正计算
FA的修正运算,即实现了2.1中提到的公式内容,代码如下:
def flash_attn_fwd_out_correction(out, out_per_step, seq_dim,
softmax_lse, softmax_lse_per_step):
"""Merge partial outputs of each step in Attention with context parallelism"""
softmax_lse_corrected_exp = torch.exp(softmax_lse_per_step - softmax_lse).movedim(2, seq_dim)
softmax_lse_corrected_exp = softmax_lse_corrected_exp.unsqueeze(-1)
out_corrected = out_per_step*softmax_lse_corrected_exp
out.add_(out_corrected)def flash_attn_fwd_softmax_lse_correction(softmax_lse, softmax_lse_per_step):
"""Merge softmax stats of each step in Attention with context parallelism"""
max_scale = torch.max(softmax_lse, softmax_lse_per_step)
min_scale = torch.min(softmax_lse, softmax_lse_per_step)
new_scale = max_scale + torch.log(1 + torch.exp(min_scale - max_scale))
softmax_lse.copy_(new_scale3.3 P2P通信
P2P通信,每个rank与相邻的rank之间进行数据交换,传出自己的KV值,同时拿到下一次需要运算的数据,代码如下:
if i < (cp_size-1):
p2p_comm_buffers[i+1] = torch.empty_like(p2p_comm_buffers[i])
send_recv_reqs[i%2] = flash_attn_p2p_communicate(rank,
p2p_comm_buffers[i],
send_dst,
p2p_comm_buffers[i+1],
recv_src,
cp_group,
batch_p2p_comm)Rring:recv_dst(接受的目标设备) ----> rank ----> send_src(发送的目标设备)
p2p_comm_buffers[i]:存储当前计算KV
p2p_comm_buffers[i+1]:接收下一步需要计算的KV
3.4 Causal_mask计算量优化
Causal_mask计算优化主要是在第一个block算完后的计算中。首先,我们对输入的QKV格式进行调整,以“bshd”为例,在sequence维度进行对拆:
[s, b, np, hn] -> [2, s//2, b, np, hn]
这样原有sequence分为了[0, :, :, :, :] 和[1, :, :, :, :]
1、当对索引 0 < i <= rank时,以“bshd”为例,QKV变化:
# [b, 2, sq//2, np, hn] -> [b, sq, np, hn]q_inputs[i%2] = q.view(q.shape[0], -1, *q.shape[-2:])# [2, b, 2, sk//2, np, hn] -> [2, b, sk//2, np, hn]kv_inputs[i%2] = kv_inputs[i%2][:, :, 0, ...].contiguous() # 丢弃了[:, :, 1, ...]FA2的运算变为:
fused_attn_fwd(
is_training, max_seqlen_q, max_seqlen_k//2, cu_seqlens_q,
cu_seqlens_k//2, q_inputs[i%2], kv_inputs[i%2][0],
kv_inputs[i%2][1], TE_DType[q.dtype],
tex.NVTE_Fused_Attn_Backend.NVTE_F16_arbitrary_seqlen,
attn_scale=softmax_scale, dropout=dropout_p,
qkv_layout=qkv_layout, attn_mask_type="no_mask",
attn_bias_type=attn_bias_type, attn_bias=attn_bias_inputs[i%2],
)主要变化点是max_seqlen_k进行整除2的操作;
2、当对索引 rank < i 时,以“bshd”为例,QKV变化:
# [b, 2, sq//2, np, hn] -> [b, sq//2, np, hn]q_inputs[i%2] = q[:, 1, ...].contiguous() # 丢弃[:, 0, ...]
# [2, b, 2, sk//2, np, hn] -> [2, b, sk, np, hn]
kv_inputs[i%2] = kv_inputs[i%2].view(2, k.shape[0], -1, *k.shape[-2:])FA2的运算变为:
fused_attn_fwd(
is_training, max_seqlen_q//2, max_seqlen_k, cu_seqlens_q//2,
cu_seqlens_k, q_inputs[i%2], kv_inputs[i%2][0],
kv_inputs[i%2][1], TE_DType[q.dtype],
tex.NVTE_Fused_Attn_Backend.NVTE_F16_arbitrary_seqlen,
attn_scale=softmax_scale, dropout=dropout_p,
qkv_layout=qkv_layout, attn_mask_type="no_mask",
attn_bias_type=attn_bias_type, attn_bias=attn_bias_inputs[i%2],
)主要变化点是max_seqlen_q进行整除2的操作;
本文以forward运算讲CP内容,反向运算的code在#L890 。
参考内容:
- 代码参考:TransformerEngine(https://github.com/NVIDIA/TransformerEngine)
- Blog:context_parallel.rst NVIDIA/Megatron-LM(https://github.com/NVIDIA/Megatron-LM/blob/c3677e09aa4e2eec37048307bd795928b8f8324a/docs/source/api-guide/context_parallel.rst)
- [2205.05198] Reducing Activation Recomputation in Large Transformer Models (arxiv.org)(https://arxiv.org/abs/2205.05198
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 GiantPandaCV 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号