使用多尺度扩散实现超分辨率的频域细化


题目: Frequency-Domain Refinement with Multiscale Diffusion for Super Resolution 作者: Xingjian Wang, Li Chai, Jiming Chen 论文链接: http://arxiv.org/abs/2405.10014 来源:arxiv 内容整理:周楚骎 单幅图像超分辨率的性能很大程度上取决于如何生成和补充低分辨率图像的高频细节。最近,基于扩散的模型在为超分辨率任务生成高质量图像方面显示出巨大的潜力。然而,现有的模型仅利用高分辨率原始图像作为所有采样时间步长的目标,难以直接预测宽频带的高频信息。为了解决这个问题并实现更高质量的超分辨率,本文提出了一种新颖的频域引导多尺度扩散模型(FDDiff),该模型将高频信息互补过程分解为更细粒度的步骤。特别是,本文开发了一种基于小波包的频率补码链,为反向扩散过程提供频带变宽的多尺度中间目标。然后,FDDiff 引导反向扩散过程,以在时间步长内逐步补充缺失的高频细节。此外,本文设计了一个多尺度频率细化网络,以在一个统一网络内以多个尺度预测所需的高频分量。对流行的基准进行了全面评估,并证明FDDiff在更高保真度的超分辨率结果方面优于以前的生成方法。
简介
单张图像的超分辨率(SR)是一项至关重要的任务,并吸引了持续的研究兴趣,这对于提高各种下游任务的低分辨率(LR)图像的质量起着至关重要的作用。从频域的角度来看,导致LR图像的自然或人为退化过程可以看作是对相应高分辨率(HR)图像的广泛低通滤波,导致高频细节的显著损失。因此,重建高质量HR图像的主要难点在于对缺失的高频信息的恢复。近年来,随着深度学习技术的不断创新,出现了各种超分辨率方法。这些方法可以分为两类,即基于回归的方法和生成方法。
其中,基于回归的方法直接学习LR到HR的映射。虽然实现了相对较小的像素误差,但基于回归的方法存在感知质量低和高频细节不足的问题。相反,生成方法在生成逼真的细节方面取得了成功,这些细节利用了从训练数据集中学到的先验分布来实现超分辨率。但是,它们也有各种限制。例如,基于 GAN 的 SR 方法容易出现不稳定的训练和模式崩溃,而基于归一化流程的和基于 VAE 的 SR 方法的 SR 结果在视觉上不太令人满意。作为生成方法的最新成员,基于扩散的SR方法在生成高质量SR图像方面取得了令人鼓舞的进展。
虽然对超分辨率有不同的解释,但本文关于超分辨率的频域视角涉及对LR图像缺失的高频信息的补充。现有的基于扩散的SR方法主要将HR地面实况设置为整个反向扩散过程中的唯一目标,没有任何中间目标或指导。因此,这些方法很难同时在相对较宽的带宽内直接预测高频信息,特别是对于较大的升频因子。如DDIM 所示,只要潜在变量在时间t处的条件分布与DDPM 中的条件分布相同,扩散正向过程就可以是非马尔可夫过程。因此,建议构建一个非马尔可夫正向过程,为反向扩散SR过程提供先验频域指导。
为了解决这个问题,本文提出了一种新的频域引导多尺度扩散模型(FDDiff),以逐步补充LR图像中缺失的高频分量。为了避免前人从简单高斯分布直接过渡到复杂HR图像分布的困难,本文提出了一种基于小波包的频率补码链,以在扩散反向过程中引入易于访问的分布。这些中间分布可以看作是时间变化的中间目标,具有逐渐细化的高频信息和层次尺度。基于频率补码链,提出了相应的多尺度频率细化扩散方法,以LR图像为条件,逐步预测小局部带宽内缺失的高频信息。此外,设计了一种具有软参数共享的多尺度频率细化网络,用于在一个网络内同时处理多尺度扩散过程中多种大小的潜在变量。本文在从人脸图像到一般图像的各种超分辨率任务上评估FDDiff。实验结果表明,FDDiff优于其他最先进的生成方法,在回归导向和感知导向指标上都实现了高超分辨率质量。
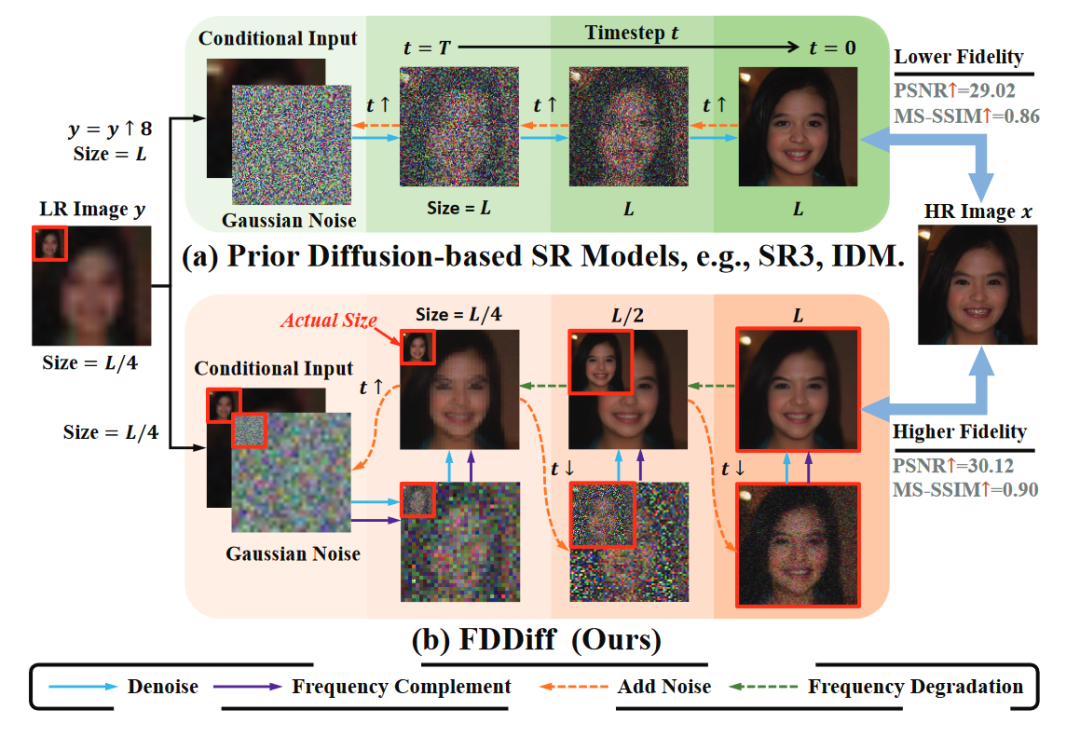
图 1 示意图,描述了先前基于扩散的SR模型和FDDiff之间的差异,其中红色框代表图像的真实大小
方法
频率补全链
本文设计了一种基于小波包的高频补码链。首先,将HR图像转换为不同带宽的子图像;然后通过非线性插值将这些子图像分配给不同的时间步长提供高频目标。因此,扩散模型被引导在较小的局部带宽内逐步预测缺失的高频细节。
频率分量提取
为了设计频率补码链,本文首先从图像中提取了不同带宽的频率分量。设 是给定的 HR-LR 图像对,其中 表示预期的高分辨率输出图像, 表示低分辨率图像, 表示放大因子。首先,将 x 与小波包变换(Wavelet Packet Transform, WPT)的基向量进行迭代卷积,以递增阶段s投射到频域上,从而得到沿信道维数具有更细粒度频率分量的子图像;具体来说,给定前台子图像,它利用一组四个固定且大小均匀的卷积核,步幅为2,将图像的频带分为四个部分,即低频部分分别由、水平高频部分由、垂直高频部分由和对角高频部分由组成。本文将Haar小波核选为K。因此,与相比,所获得的子图像具有双倍的下采样尺度和更窄带宽的频率分量,这种四树子带分解过程可以定义如下:
其中 表示分解操作, 表示沿通道维度的串联操作。 的反向过程 可以写成,
其中 且。 表示 PixelShuffle,上采样因子为2。K′ 是四个固定逆核的集合。
多尺度频率退化金字塔
基于p-times分解得到的子图像,首先构建了级联2×升尺度的多尺度退化金字塔。 的通道被分成不同频率系数的 部分,并按其频率排序,结果 ,频率沿索引下降。其中, 表示 的低频部分,而其余的则表示中间目标。定义低通操作 以滤除以给定 i 和 j 为条件的高频分量,其中 i 和 j 都从整数集 中给出频率索引。当 i ≤ j 时, 等于 ,否则等于零。然后,x 的 态多尺度子图像衰减金字塔定义如下:
其中 表示上限函数, 。这样,金字塔在第 1 种状态下将 降解为 LR 图像 在第 种状态下。
此外,上述的 状态应分配给 时间步长。由于低j保留较大能量的低频部分较难恢复,因此建议引导扩散模型对较低指数j进行更多时间步长的采样。因此,本文设计了基于幂函数的时间步长分配时间表,可以表示为:
然后,可以从子图像金字塔推导出 T 时间步长上的频率衰减金字塔,如下所示:
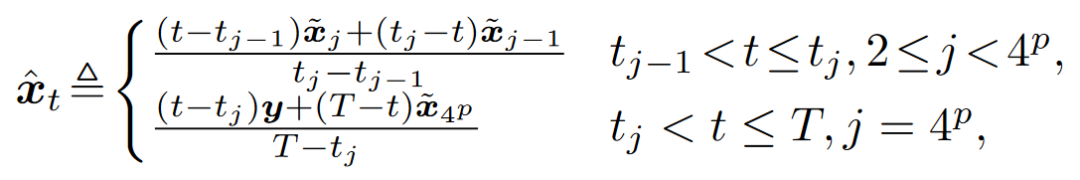
其中,对应于从 到 的状态转换的关键时间步长 设置为 。尽管 y 的 LR 退化仍然未知,但 y 的频率分量包含在的低频部分。因此,所提出的链首先将y的频率带宽转换为相同的频率带宽。值得注意的是,对于 ,当 时, 的尺度从 变为 。因此,所有时间步长的 形成一个多尺度金字塔,而不是一个固定大小的链,这将有效地降低内存和计算成本。因此,从y到x的频率补码链由该频率衰减金字塔的反向过程给出,其中缺失的高频分量, 作为扩散模型的附加目标。
多尺度频率细化扩散
在频率补码链的指导下,提出了具有多尺度潜在变量的非马尔可夫扩散过程,以生成LR图像缺失的高频细节。
前向过程
受DDIM和f-DM的启发,本文设计了一个具有的噪声潜在变量,其条件分布符合DDPM中定义的分布。 在 附近直接采样
其中噪声超参数 遵循余弦时间表。, 随时间单调降低到零。显然, 和 。为了满足边际分布,非马尔可夫扩散正向过程由下式给出,
其中 和 表示每向前一步增加的高斯噪声。为了在不同尺度的时间步长之间平滑过渡,在尺度变化时间步之间添加了整数因子= 的下采样运算。也就是说,如果 且 , ,则 等于 2,否则 等于 1。对于Haar小波,选择平均下采样,等于以F为单位的卷积。由于平均下采样, 的方差在当前尺度变化时减小。因此, 从 采样,而。

图 2 训练过程
反向过程
由于本文的正向过程是非马尔可夫过程,并且的条件分布符合DDPM中的条件分布,因此设计了基于DDIM 的反向过程,以借助UNet风格的多尺度网络从ut预测ut−1。具体而言,采用参数为的网络,同时估计了缺失的频率分量和的附加噪声。对于控制 DDIM 中随机幅度的超参数 ,根据正向过程, 设置为 。因此,多尺度扩散过程的反向过程可以推导出为:
其中 θ 表示使用条件输入 y 和 t 从 预测 和 的网络。θ 具有具有 q 尺度的 q 状态,q 定义为对于相应的 t。利用网络传导的函数,对至的局部窄带宽的高频分量进行降噪和恢复。与正向过程中的下采样操作对称,上采样操作 的系数为 也被添加到反向过程中。根据 Haar 小波的 ,选择最接近的上采样。

图 3 推理过程
训练目标
对于第 j 个状态的时间步长 ,从 生成无噪声前态 被视为训练目标。,L1 损失函数 定义如下:
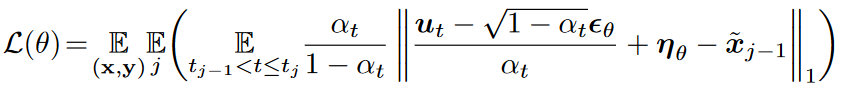
其中 表示 SNR 加权系数。算法1和算法2分别给出了上述正向和反向过程的相应训练和采样算法。
多尺度频率细化网络
由于所提出的基于小波包的频率补码链能够实现多尺度扩散过程,因此相应的频率细化网络有望在一个网络内同时预测不同尺度的 和 ,条件输入y和t。受f-DM 的启发,DDPM 中的U-Net架构固有地揭示了网络的多尺度特征只对应于多尺度潜在变量。因此,本文提出了具有p + 1状态的超分辨率的多尺度频率细化网络,该网络利用软参数共享在不同状态之间切换,从而同时处理不同尺度的扩散输入和输出。
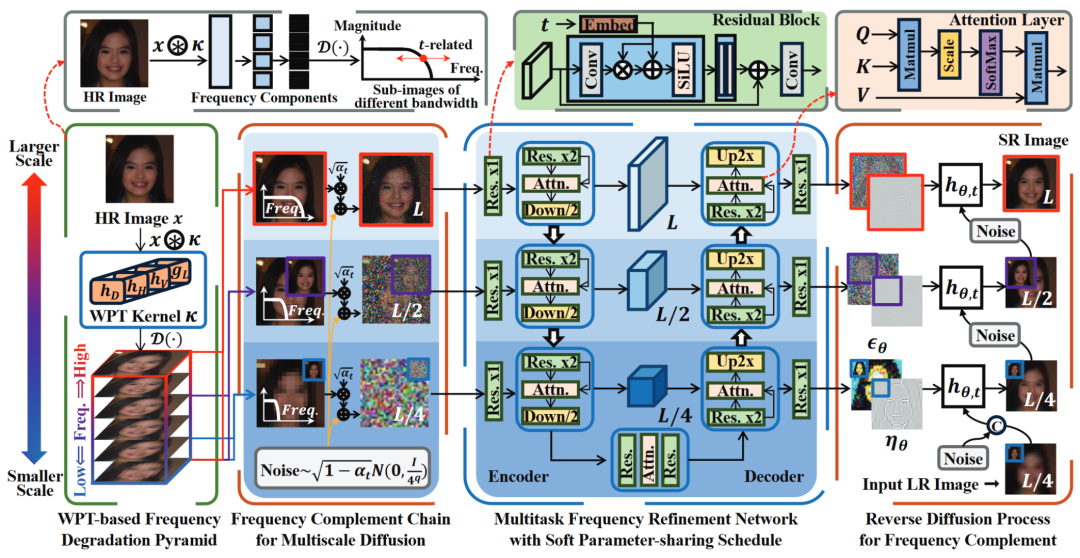
图 4 FDDiff 框架
具体来说,在编码器中,每个模块由三个部分组成,包括两个残差模块、一个自注意力层和一个2×下采样层。至于解码器,下采样层被 2× 上采样层取代。编码器和解码器的最后一个块除外,其下采样层或上采样层将被移除。PixelShuffle方法用于下采样和上采样图层。对于不同比例的输入和输出图像,分别在编码器和解码器块之前或之后添加相应的输入层和输出层。这些输入层和输出层都由一个残差块和一个自注意力层堆叠而成。对于条件输入,LR图像y与信道维输入噪声图像连接,时间步长t通过线性层投影,对后面的残差块特征进行仿射变换。
软参数共享调度可以描述为 的不同状态共享一部分网络参数。具体来说,假设的编码器和解码器都由p+1块组成,则第i个状态的将解冻从编码器的第i个块到解码器的第(p+2−i)块的参数,并保持冻结其他块的参数。这样,第i种状态下输入ut和输出的(p + 1)个尺度对应于频率补码链中的和扩散过程中的。
实验
数据集
采用两种常用的实验设置对超分辨率任务进行性能评估,分别涉及人脸图像和一般图像。
人脸图像: 对于大尺度的人脸图像,FDDiff在Flickr-FaceHQ(FFHQ)上进行训练,并在CelebA-HQ上进行评估。FFHQ 和 CelebA-HQ 的图像分辨率均为 1024 × 1024,作为固定输入大小调整为 128 × 128。对人脸图像进行了放大比为8×的超分辨率实验,这意味着人脸超分辨率为16×16→128×128。为了在 CelebA-HQ 上进行评估,为了与 SR3 和 IDM 的代码实现保持一致,随机抽取了 CelebA-HQ 的一小部分,即本文中的 1,000 张图像。
一般图像: 对于一般图像的超分辨率,FDDiff在DIV2K的训练集上进行训练,并在DIV2K验证集、BSDS100、General100和Urban100等四个数据集上进行评估。由于 DIV2K 的图像具有可变大小,从 DIV2K 训练集中提取 48 × 48 → 192 × 192 个 192 个 192 个补丁对,用于 4× SR 任务的训练。对于推理过程,由于 FDDiff 的网络是在没有固定位置编码或时间编码的情况下构建的,因此 FDDiff 可以在将这些图像拉伸到可被 整除的最接近的平方大小后推断全尺寸图像。
实现细节
训练细节: 建议的 FDDiff 在 RTX3090 上从头开始训练,在 SR3 之后,人脸图像约为 1M 步长,一般图像为 0.5M 步长。根据最大内存使用量限制,输入大小 128×128 的批大小设置为 64,输入大小 256×256 的批大小设置为 32。采用AdamW作为优化器,初始学习率为5×10−4,权重衰减为10−2。人脸图像的总采样时间步长设置为1,000,常规图像的总采样时间步长设置为640,超参数α遵循中的余弦调度器。对于训练过程中的预处理,调整大小的图像或补丁被归一化为 ,然后随机水平和垂直翻转以进行数据增强。本文利用U-Net架构,嵌入式残差块和自注意力层作为FDDiff的网络框架。当升频因子为 时, 编码器块的通道尺寸为 。 的 编码器块的通道维数为 ,,。该代码将在论文接受后发布。
验证指标: 采用峰值信噪比(PSNR)、结构相似性指数测量(SSIM)和学习感知图像贴片相似度(LPIPS)来评估超分辨率质量。其中,PSNR直接用于评估SR和HR图像对像素值之间的均方误差(MSE)。SSIM不依赖于数值比较,而是专注于人类的视觉感知,从而同时考虑亮度、对比度和结构的相似性。作为一种基于感知的指标,LPIPS利用预训练网络来计算HR和SR图像对激活之间的相似性,为此,本文采用了在ImageNet数据集上预训练的SqueezeNet。
比较
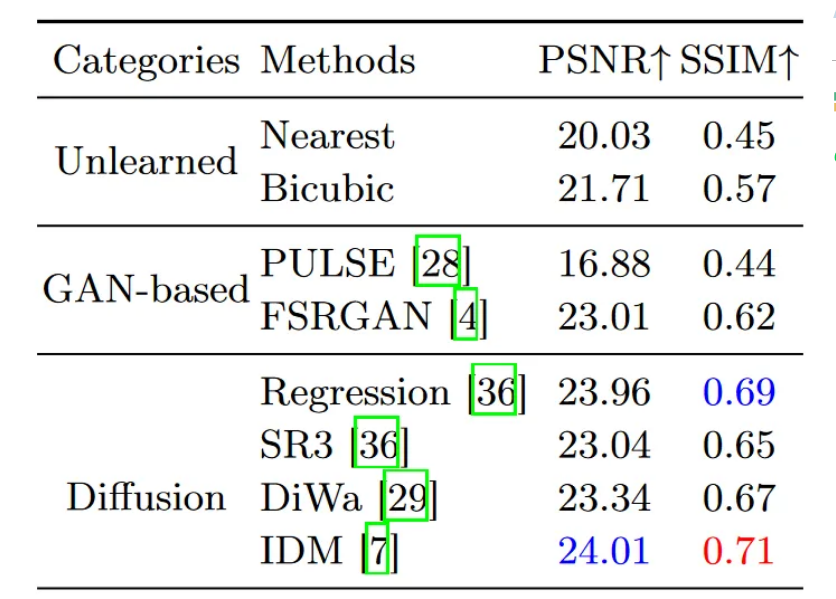
表1:CelebA-HQ上16×16→128×128超分辨率生成模型的定量比较.红蓝颜色分别表示最佳和第二最佳性能。
大尺度人脸超分辨率
在SR3之后,本文首先评估FDDiff,并通过对70,000张FFHQ图像的训练和CelebA-HQ的评估,与其他技术阶段的生成方法进行比较,如表1所示。涉及的生成方法包括基于 GAN 的模型、FSRGAN、PULSE 和最近基于扩散的模型,例如 SR3、DiWa 和 IDM。从表1中可以看出,FDDiff在基于数值比较的度量PSNR和感知度量SSIM方面都优于以前的生成方法。在这些基于扩散的方法中,DiWa还利用生成高频信息来执行超分辨率任务。然而,它既没有明确地将高频补码过程与扩散过程结合起来,也没有将高频分量划分为较窄频带的分量。结果,FDDiff 大幅超过它,即 PSNR 为 5.06%,SSIM 为 5.97%。与最新的基于扩散的IDM相比,FDDiff在PSNR中高出0.51dB,获得了更好的结果。本文还与基于扩散的方法 SR3 和 IDM 进行了进一步的比较,以获得额外的感知指标 ManIQA 和 MUSIQ 。ManIQA 和 MUSIQ 的冻结网络分别在 PIPAL 和 AVA 数据集上进行预训练。表 2 中的结果表明 FDDiff 在感知质量方面具有优越性。
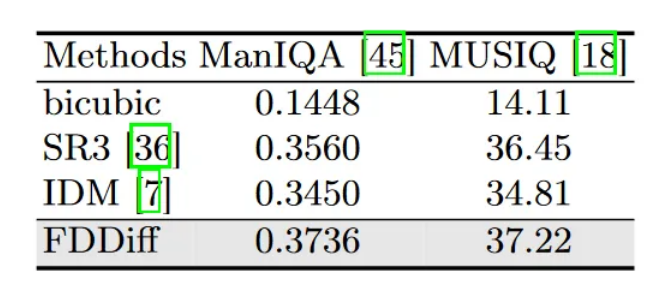
表2:与先前扩散方法的额外感知比较。在CelebA-HQ数据集上,对ManIQA和MUSIQ进行了8倍超分辨率(8xSR)的评估。
为了进行定性比较,如下图所示,根据 LR 图像生成的 FDDiff 人脸包含更逼真的面部特征,例如眼睛、牙齿、耳朵和鼻子。虽然可能不如 SR3 和 IDM,FDDiff 的结果包含面部细粒度细节,对地面真实值的保真度更高。特别是对于眼睛、耳朵和牙齿,SR3/IDM 图像和 HR 图像的结果之间存在较大差异,而 FDDiff 与 HR 图像保持了更高的一致性。

图 5 定性比较
一般图像超分辨率
为了证明 FDDiff 对一般图像的超分辨率质量,在 DIV2K 训练集上训练的 FDDiff 在 DIV2K 验证集上进行评估。通过PSNR和SSIM评估超分辨率质量,并与各种模型进行比较,包括:基于回归的模型EDSR和LIIF;基于VAE的型号LAR-SR ;基于 GAN 的模型 ESRGAN 和 RankSRGAN;基于流量的模型SRFlow和HCFlow;基于扩散的模型SRDiff、DiWa 和IDM。如表3所示,FDDiff实现了具有竞争力的数值SR质量和出色的感知SR质量,比之前至少PSNR高出0.14dB, SSIM 为 11.4%。它揭示了FDDiff优先考虑人类的感知质量,这是通过对LR图像中缺失的高频信息的逐步细化来实现的。
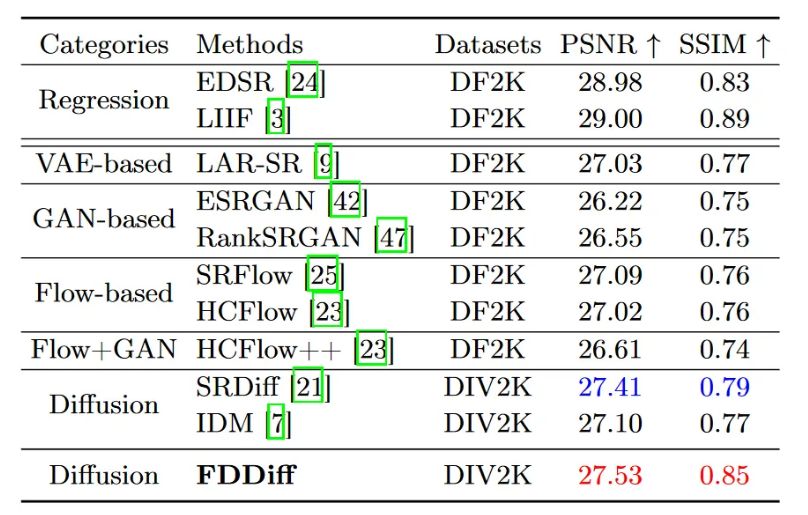
表3:在DIV2K验证集上对4倍自然超分辨率的定量比较。第三列中指出了使用的训练集,其中DF2k表示同时在DIV2K和Flickr2K上进行训练。回归模型位于双水平线上方,而生成模型位于下方。在生成模型中,最佳性能分别用红色突出显示为第一好,用蓝色突出显示为第二好。
消融实验
频域细化过程的影响
如表4所示,本文构建并评估了具有不同尺度设置、目标数量和扩散过程目标的四种变体。与先前基于扩散的SR方法类似,模型1将FDDiff的输入层和输出层调整为单尺度,即与输入图像相同的尺度,并且仅通过去除频率补码链来预测噪声εt。模型 2 进行多级扩散并将 FDDiff 的目标数更改为 p + 1,这意味着为目标 ηt 选择了 j 的子集 。模型 2 的 SR 质量高于模型 1,证明了本文提出的频率补码链和相应的多尺度频率细化扩散模型的有效性。灰色行中的Model 3,即FDDiff,由于其细粒度的频率分配,实现了更高的SR质量。对于模型4,它去除了扩散过程,仅预测频率补码链的,并获得较低的PSNR和SSIM。这证明了扩散过程中高斯噪声的随机性引导对于高质量的SR是必不可少的。
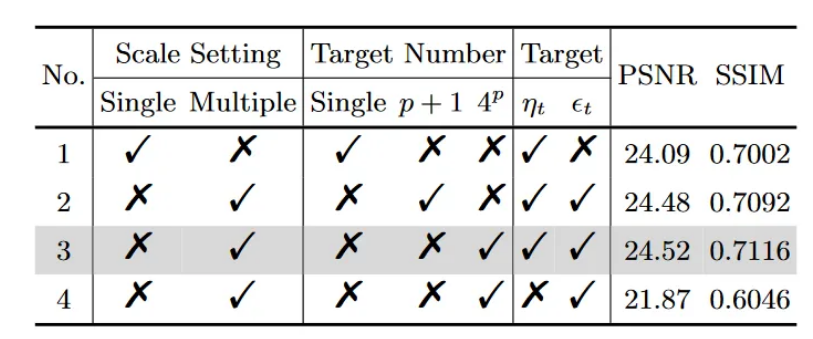
表4:对FDDiff的不同变体进行消融研究,包括不同的尺度设置、目标数量以及扩散过程中预测的目标。所有模型均在FFHQ上进行8倍超分辨率训练,并在CelebA-HQ上进行评估。
扩散步数
由于FDDiff配备了DDIM的时间步长跳跃采样程序,以便进行更有效的推理,因此本文评估了采样时间步长对SR质量的相应影响。在 FFHQ 上以 T = 1000 个总时间步长进行 SR 训练,升频比为 ,选择不同的采样时间步长进行推理。下图显示了生成速度和质量之间的权衡,这表明 FDDiff 只需 64 个时间步长即可实现不错的性能,并被选为 FDDiff。本文注意到,FDDiff的SR质量在100个时间步长下达到最佳状态,并且在所有时间步长内趋于稳定,这可能与之前基于扩散的SR模型不同。原因可能在于本文的模型训练有素,并且扩散过程的随机性受到额外中间目标的限制,因此相对不容易受到总采样时间步长数量的影响。
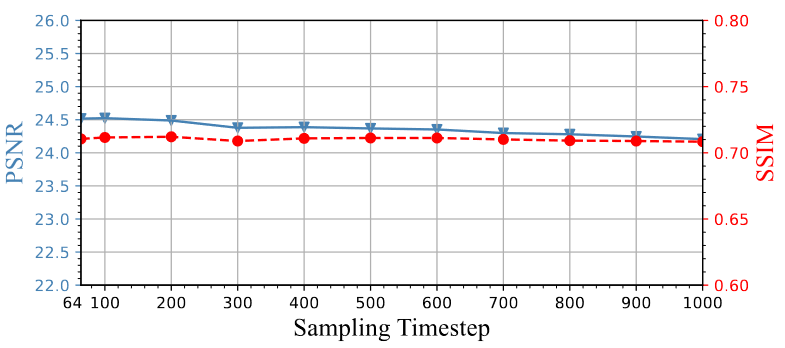
图 6 扩散步数
总结
本文提出了一个频域引导的多尺度扩散模型(FDDiff),该模型旨在逐步补充缺失的高频信息到低分辨率图像,并实现更高质量的超分辨率。通过所提出的频率补码链,FDDiff将生成所有高频细节的困难过程分解为多大小。本文进一步设计了一个多尺度频率细化网络,以在一个统一的网络中处理多尺度频率补码过程。对一般和面部图像的大量实验表明,FDDiff 的性能优于以前的生成模型。在未来的工作中,本文将开发频域采样计划,以加快推理速度。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-06-24,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号