KDD'24 | MMBee:多模态融合和行为兴趣扩展在快手直播礼物推荐中的应用

KDD'24 | MMBee:多模态融合和行为兴趣扩展在快手直播礼物推荐中的应用

秋枫学习笔记
发布于 2024-07-12 14:21:54
发布于 2024-07-12 14:21:54
1. 导读
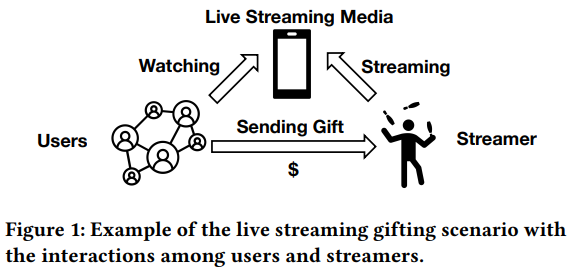
本文主要针对直播中的用户行为(评论,礼物等)建模中的问题提出解决方案,以往关于直播礼物预测的研究将这项任务视为一个传统的推荐问题,并使用分类数据和观察到的历史行为对用户的偏好进行建模。但是,由于用户行为很稀疏,尤其是送礼物这类付费行为,想要捕捉用户的偏好和意图相当困难。本文提出了基于实时多模态融合和行为扩展的MMBee方法。
- 首先提出了一个具有可学习查询的多模式融合模块(MFQ),用于感知流媒体片段的动态内容,并处理复杂的多模式交互,包括图像、文本评论和语音。
- 为了缓解送礼行为的稀疏性问题,提出了一种新的graph引导的兴趣扩展(GIE)方法,该方法学习具有多模态属性的大规模送礼graph上的用户和流媒体表征。主要包含两部分:图节点表征预训练和基于元路径的行为扩展,有助于模型跳出特定的历史赠与行为进行探索,丰富行为表示。
2.方法
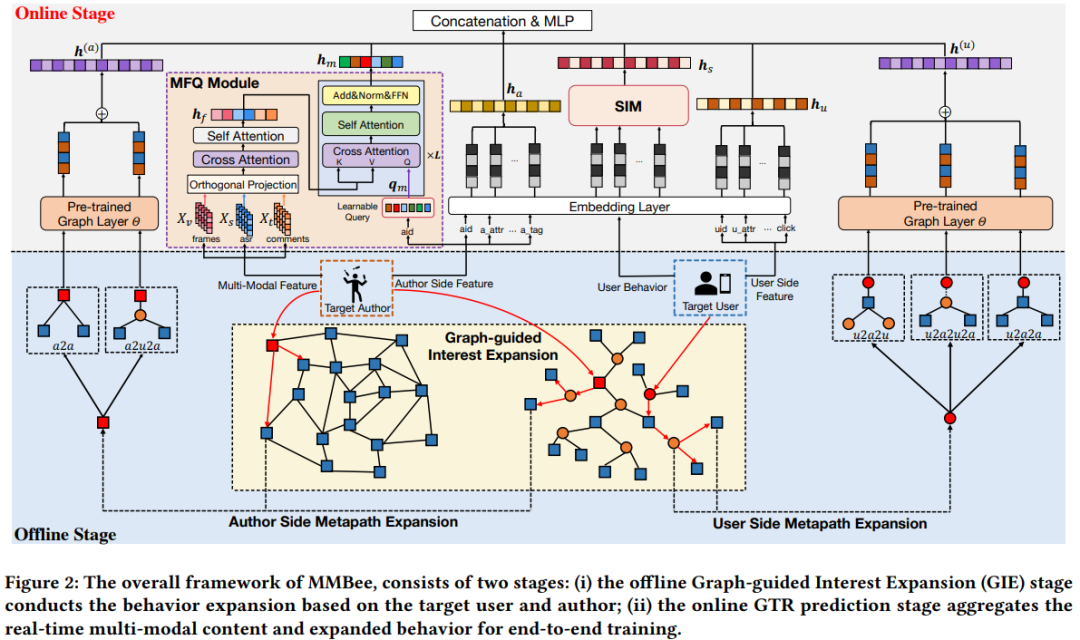
alt text
2.1 多模态融合模块
对于每个直播片段,从每个片段中均匀地采样三帧,并对收集的ASR(自动语音识别)和评论文本进行过滤。然后,用快手内部预训练的8B多模态模型K7-8B提取原始数据的多模态特征,包括视觉、语音和评论的多模态序列元组分别是。
得到不同模态的表征之后,使用不相关的部分进行表征补充。如,以视觉模态作为目标模态,计算视觉模态与另外两种模态之间的相关分数,
视觉模态的融合特征为下式,即用和当前识别表征不相关的部分对其进行补充,因为相关的部分相当于是冗余信息了。
然后,将原表征和采用op补充后的表征执行注意力机制(cross attn),将对应结果进行拼接输入自注意力层,这里就是去做不同表征的融合
然而,融合特征只能反映内容层面的表征,缺乏与不同类型作者(主播)的特征的联系。为了解决这个问题,引入了几个可学习的查询token来提取流媒体感知的内容模式。每个作者都保留了一组随机初始化的可学习查询emb。N表示每个作者的查询token数。可学习查询首先通过cross attention与融合的多模态特征交互然后输入自注意力层
2.2 graph引导的兴趣扩展
2.2.1 user-to-author graph和author-to-author graph
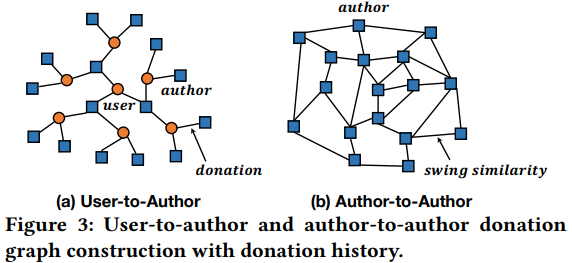
基于用户的打赏历史,构建一个用户-作者(U2A)图表示用户和作者之间的相关性,V是用户和作者对应的集合,E是打赏关系。边的权重是打赏的金额,作者节点具有聚合多模态特征的属性。
构建作者-作者(A2A)的图来表示作者之间的相互依赖性,边表示作者之间Swing相似性的关系。swing相似性计算方式如下,U是给作者打上过的用户集合,所以分母这里计算的是同时打上过i,j两个作者的用户总共打上过多少作者,打赏过的作者越同质化(多样性低),相似性越低,用来防止除0。
A2U图是通过用户和作者之间的打赏关系建立起来的,但也有一些新的或冷启动的作者,他们基本就没有被打赏过。但是可以通过A2A图给这些打赏稀疏的用户找到相似的用户,缓解冷启动问题。在构建U2A和A2A图之后,首先利用图节点表示学习方法来训练图嵌入层。然后使用基于元路径的行为扩展方法,丰富稀疏行为序列。首先了解一些元路径的定义,
- 定义1:元路径为一个关系序列,用于捕捉对象之间的特定结构关系。在A2U和A2A图中,作者定义了五个元路径:从目标用户开始的三个元路径,两个从作者出发的路径
- 定义2:元路径引导的邻居节点,给定图中的一个节点o和一个从o开始的元路径,表示从o出发沿着元路径访问的第i步(阶)邻居节点的集合。
2.2.2 使用graphcl进行节点表征预训练
为了利用整个图的连通性信息,应用图对比学习(GraphCL)框架来训练图嵌入层。为了将相似的节点聚类在一起,同时推开不相似的节点,循环遍历图G1中的所有节点,通过元路径引导的邻居得到正样本节点,负样本节点是随机采样的。通过交叉熵损失函数和infoNCE进行训练,infoNCE比较好理解,常用的对比学习损失函数,不过没理解这里说的交叉熵损失的作用,这里不是应该是自监督学习吗?(有了解的小伙伴可以评论下,感觉这里的CE应该是下面兴趣扩展中的预测是否分类的任务的损失)

alt text
2.2.3 兴趣扩展
用户的打赏行为一般是比较稀疏的,因此这里对用户兴趣进行扩展。考虑计算成本,作者在U2A和A2A图上执行最多3跳,得到邻居。列举了所有可能的元路径,最后选出最重要的五个集合,
- ,表示的是与当前用户相似的用户,他们都喜欢相同的作者(主播)
- 剩下的有,这里不一一介绍了,毕竟不同业务场景找到的路径可能不同,感兴趣的可以看原文。
基于此丰富了用户的行为,在离线兴趣扩展阶段,将扩展邻居的聚合emb存储到数据库中,在线训练阶段进行使用。为了消除预训练的节点表示与在线推荐模型之间的差距,在端到端训练的推荐模型中通过预测是否会打赏的二分类任务对其进行优化。扩展的用户emb和作者emb分别表示为下式,分别表示图节点emb层(对于用户)和多模态属性(对于作者)
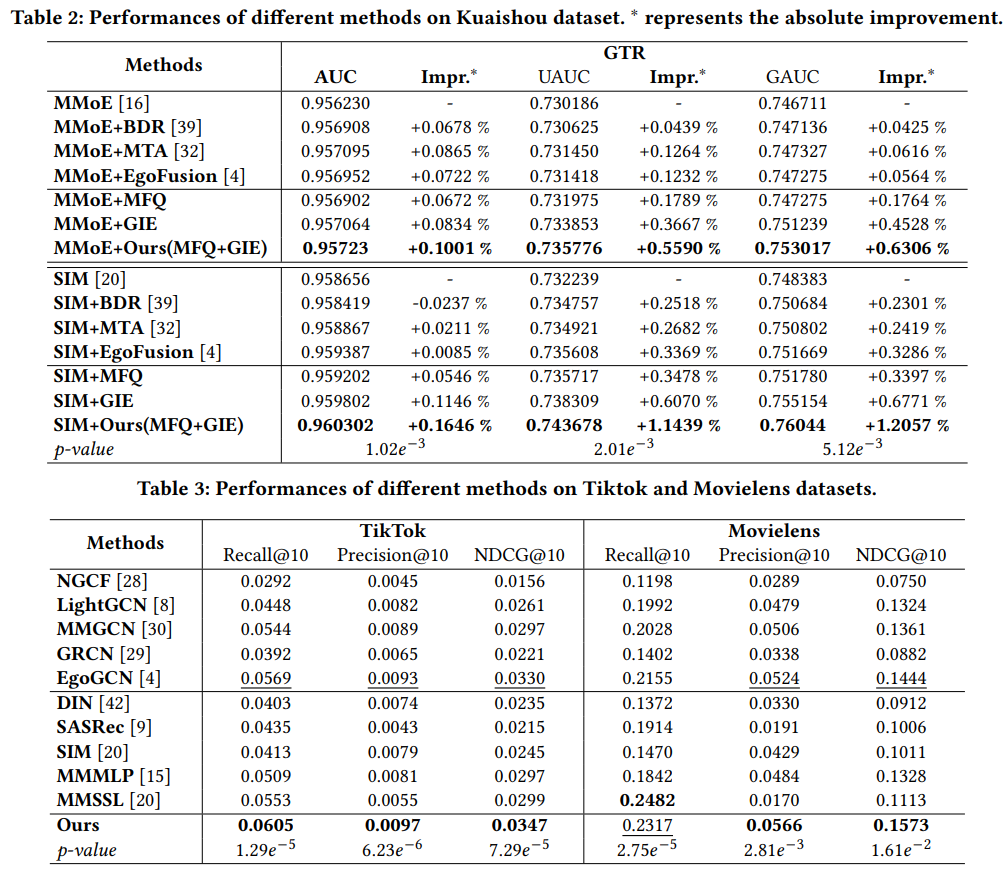
3 实验
alt text
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-07-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号