一步一步理解ES搜索
原创

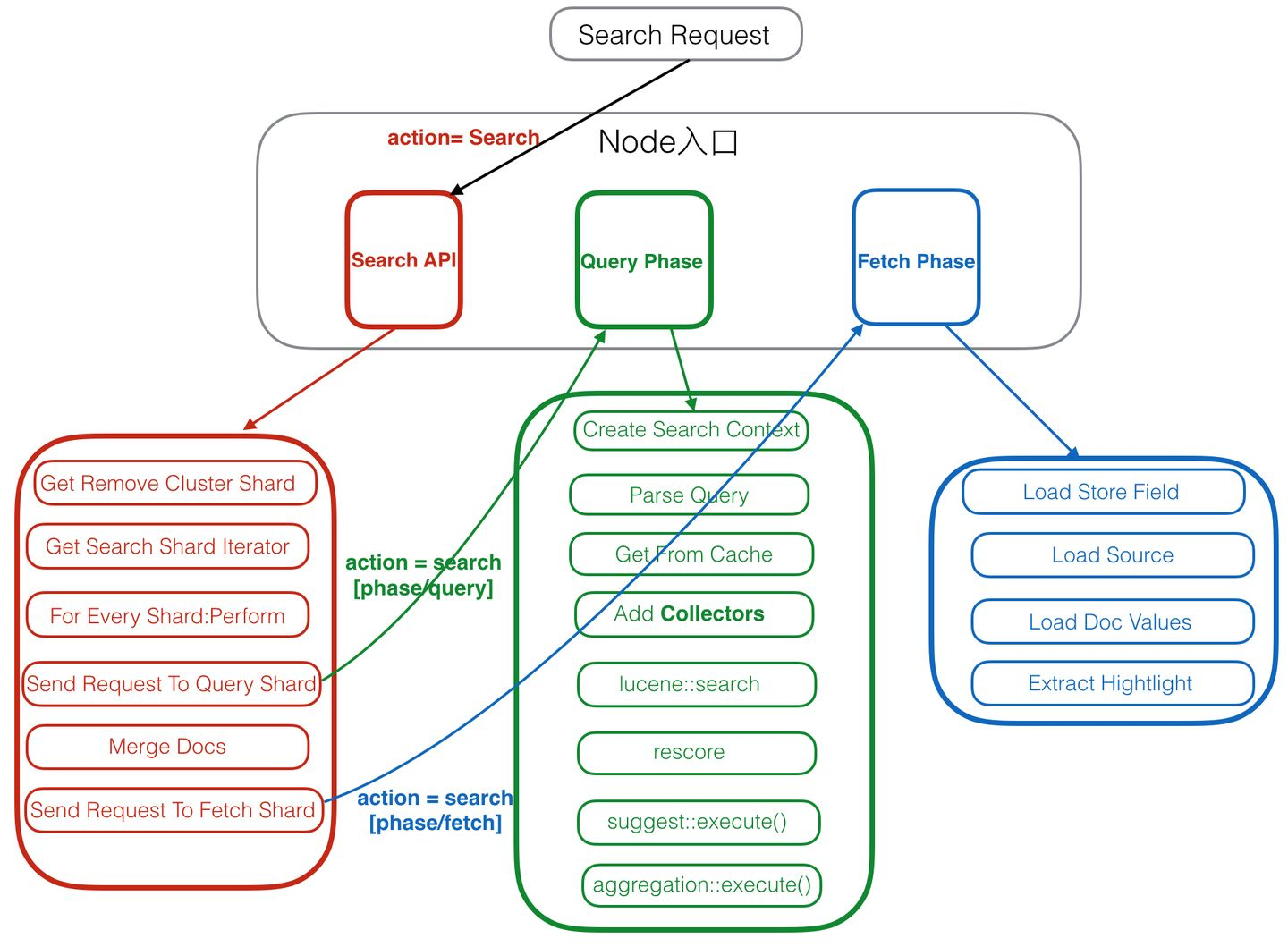
一、ES搜索分为三个大的阶段:
- Search API
- Query Phase
- Fetch Phase
二、Search API
1、Get Remove Cluster Shard
2、Get Search Shard Iterator
3、For Every Shard:perform
4、Send Request to Query Shard
5、Merge Docs
6、Send Request To Fetch Shard
这些步骤是 Elasticsearch 查询处理的关键部分,它们描述了从查询请求到返回结果的整个流程
1. Get Remove Cluster Shard
原理分析:
- 目的:
Get Remove Cluster Shard过程是 Elasticsearch 查询过程中涉及的一个步骤,旨在从集群中获取或移除分片的信息。 - 过程:当节点需要处理查询时,它首先确定需要查询的分片(shard)。分片可以是主分片或副本分片。
Get Remove Cluster Shard的作用是从集群状态中获取相关分片的元数据(如分片位置、状态等),以便后续处理。 - 具体操作:在集群中,每个节点都会持有集群状态的副本。节点通过与集群状态协调,决定哪些分片参与查询。这一过程涉及从集群状态中获取分片的元数据,并根据需要移除或更新分片信息。
2. Get Search Shard Iterator
原理分析:
- 目的:
Get Search Shard Iterator是确定分片迭代器的步骤,分片迭代器用于遍历分片中的文档。 - 过程:在 Elasticsearch 中,查询被分解到各个分片上。每个分片上都有自己的数据结构,称为分片迭代器(Shard Iterator),用于遍历分片中的文档。
Get Search Shard Iterator的过程是为每个分片创建或获取一个迭代器。 - 具体操作:节点会为每个参与查询的分片创建一个迭代器,这些迭代器负责按顺序访问分片中的文档。这个过程通常涉及初始化与文档相关的查询上下文,并准备迭代器以便执行查询。
3. For Every Shard: perform
原理分析:
- 目的:
For Every Shard: perform是指在每个分片上执行查询的步骤。 - 过程:查询被分解成多个子查询,每个子查询针对特定的分片执行。在这一阶段,Elasticsearch 对每个参与的分片执行实际的查询操作。
- 具体操作:对于每个分片,节点会利用之前获取的分片迭代器,执行查询并检索匹配的文档。这一过程可能包括应用查询条件、执行过滤和排序操作。每个分片返回的结果都是部分查询结果。
4. Send Request to Query Shard
原理分析:
- 目的:
Send Request to Query Shard是将查询请求发送到分片的步骤。 - 过程:在 Elasticsearch 中,查询请求会被发送到所有参与的分片(包括主分片和副本分片)。
Send Request to Query Shard是将查询请求实际发到每个分片的过程。 - 具体操作:节点会根据查询的分片列表,将查询请求通过网络发送到分片所在的节点。这个请求会被分片节点处理,执行查询操作,并返回结果给请求发起者。
5. Merge Docs
原理分析:
- 目的:
Merge Docs是将来自多个分片的结果合并的步骤。 - 过程:每个分片独立执行查询,并返回部分结果。在查询结束后,所有这些部分结果需要被合并成一个完整的结果集。
Merge Docs是负责这一合并过程的步骤。 - 具体操作:节点会收集所有分片返回的文档,并根据排序、聚合等要求将这些文档进行合并。合并过程可能包括排序文档、去重、合并聚合结果等。最终的结果集将是所有分片结果的综合。
6. Send Request To Fetch Shard
原理分析:
- 目的:
Send Request To Fetch Shard是获取实际文档内容的步骤,通常在查询中需要获取详细的文档数据时使用。 - 过程:在 Elasticsearch 中,查询可能会先返回文档的匹配信息(如文档 ID),但实际文档的详细内容通常需要额外的请求来获取。
Send Request To Fetch Shard是实际获取这些文档内容的步骤。 - 具体操作:节点会将获取详细文档内容的请求发送到存储这些文档的分片。分片节点会从存储中读取文档内容,并将其返回给查询的发起者。这个过程可能涉及从磁盘或缓存中读取数据,并处理请求中的字段选择和文档格式化等操作。
Search API 总结
这些过程描述了 Elasticsearch 查询的核心步骤,从确定查询分片到获取和合并查询结果。具体来说:
Get Remove Cluster Shard:确定和管理分片的元数据。Get Search Shard Iterator:初始化用于遍历分片文档的迭代器。For Every Shard: perform:在每个分片上执行查询。Send Request to Query Shard:将查询请求发送到各个分片。Merge Docs:合并来自不同分片的查询结果。Send Request To Fetch Shard:获取详细的文档内容。
三、For Every Shard: perform 内部关系概述
For Every Shard: perform是一个顶层操作,它涉及对每个参与查询的分片执行一系列操作。这些操作的目标是获取和合并查询结果。Send Request to Query Shard是在每个分片上执行查询的步骤,它负责将查询请求发送到每个分片并执行查询操作。Merge Docs是在所有分片返回结果后,将这些结果合并成一个统一结果集的步骤。Send Request To Fetch Shard是在需要获取详细文档内容时,将请求发送到分片以获取实际文档的步骤。
详细关系分析
1. Send Request to Query Shard
操作描述:
- 目的:将查询请求发送到每个参与的分片,以便在这些分片上执行查询。
- 过程:在
For Every Shard: perform的过程中,首先需要对每个分片执行实际的查询操作。Send Request to Query Shard是将查询请求实际发送到每个分片的步骤。每个分片会根据请求执行查询,并返回查询结果(通常包括匹配的文档的 ID 和相关信息)。
与其他步骤的关系:
- 前置条件:需要确定所有参与查询的分片,并为每个分片生成查询请求。
- 后续步骤:查询结果需要进一步处理,包括文档内容的获取和结果的合并。
2. Merge Docs
操作描述:
- 目的:将来自不同分片的查询结果合并成一个最终结果集。
- 过程:在所有分片完成查询并返回结果后,
Merge Docs将这些结果合并成一个统一的结果。合并过程可能包括对文档进行排序、去重、合并聚合结果等操作。
与其他步骤的关系:
- 前置条件:必须在所有分片上执行查询并收集返回的结果。
- 后续步骤:合并后的结果将是最终的查询响应。如果需要获取详细文档内容,可能还需要发送额外的请求。
3. Send Request To Fetch Shard
操作描述:
- 目的:从分片中获取详细的文档内容,通常是在查询响应中只返回了文档 ID 的情况下使用。
- 过程:在查询结果中,可能只返回了文档的基本信息(如 ID),详细的文档内容需要通过
Send Request To Fetch Shard进一步获取。这涉及到向分片发送请求,以检索文档的完整内容。
与其他步骤的关系:
- 前置条件:需要
Send Request to Query Shard完成,得到的查询结果通常包含文档 ID,需要进一步获取详细内容。 - 后续步骤:获取详细文档内容后,将这些内容合并到最终的查询响应中,完成完整的查询结果返回。
总结
For Every Shard: perform是一个汇总操作,包含多个子操作,负责对每个分片执行查询处理。Send Request to Query Shard:实际将查询请求发送到分片,执行查询操作。Merge Docs:将所有分片返回的查询结果合并成一个完整的结果集。Send Request To Fetch Shard:获取详细文档内容,通常在初步查询中只返回文档 ID 的情况下使用。
四、Query Phase
Send Request to Query Shard 步骤涉及多个操作,这些操作共同工作以执行查询并返回结果。
1. Create Search Context
操作描述:
- 目的:为每个查询请求创建一个搜索上下文(Search Context)。搜索上下文包含查询的所有必要信息,并用于在分片上执行查询。
- 过程:搜索上下文包括查询请求的解析结果、相关的索引信息、文档数据和查询上下文等。创建搜索上下文是为了确保查询的执行环境能够支持后续的查询处理步骤。
- 详细信息:搜索上下文的创建包括设置查询的范围、相关的文档字段、排序方式等。它为后续的查询执行提供了必要的环境和元数据。
与其他步骤的关系:
- 前置条件:需要查询请求已经准备好,包括解析的查询语法。
- 后续步骤:创建搜索上下文后,查询可以在这个上下文中进行解析和执行。
2. Parse Query
操作描述:
- 目的:解析查询请求中的查询语法,以便将其转化为 Elasticsearch 能够处理的格式。
- 过程:查询请求通常包括各种查询条件,如匹配查询、范围查询、布尔查询等。
Parse Query步骤将这些条件解析成适合 Lucene 搜索引擎的数据结构和查询语法。 - 详细信息:查询解析涉及将查询语法转化为 Lucene 能够理解的形式,如布尔查询树、词条查询等。
与其他步骤的关系:
- 前置条件:需要查询请求已发送至分片,并且需要创建搜索上下文。
- 后续步骤:解析查询后,查询条件会被应用到搜索上下文中,进一步进行缓存检查和查询执行。
3. Get From Cache
操作描述:
- 目的:从缓存中获取查询结果,以加快查询响应速度。
- 过程:Elasticsearch 在执行查询之前,会检查缓存中是否已经存在相同的查询结果。
Get From Cache步骤会尝试从缓存中获取匹配的结果,以避免重复计算。 - 详细信息:缓存机制包括查询缓存(如过滤器缓存)和结果缓存。对于常见的查询,可以显著减少执行时间。
与其他步骤的关系:
- 前置条件:查询请求需要经过解析并生成查询条件。
- 后续步骤:如果缓存命中,查询结果将从缓存中获取,不需要进一步的执行步骤。如果未命中,则需要继续执行查询。
4. Add Collectors
操作描述:
- 目的:将不同的收集器(Collector)添加到查询执行过程中,用于收集和排序文档。
- 过程:Elasticsearch 使用不同的收集器来处理查询结果,比如
TopDocsCollector用于排序和返回最匹配的文档,FacetsCollector用于聚合。Add Collectors步骤将这些收集器添加到搜索上下文中。 - 详细信息:收集器会根据查询的要求收集匹配的文档,进行排序、分页等操作。
与其他步骤的关系:
- 前置条件:查询条件已经解析并准备好执行。
- 后续步骤:收集器将处理查询结果,并生成排序后的文档集。
5. lucene::search
操作描述:
- 目的:在 Lucene 索引中实际执行查询操作。
- 过程:
lucene::search是查询处理的核心步骤,实际执行搜索操作。Lucene 引擎会根据解析后的查询条件扫描索引,找到匹配的文档,并按照收集器的要求进行排序和过滤。 - 详细信息:Lucene 在索引中进行高效的搜索操作,包括倒排索引扫描、评分计算、排序等。
与其他步骤的关系:
- 前置条件:查询条件已经解析,搜索上下文已创建,并且收集器已添加。
- 后续步骤:Lucene 搜索完成后,查询结果会返回给 Elasticsearch,用于进一步处理。
6. rescore
操作描述:
- 目的:对初步查询结果进行重新评分。
- 过程:
rescore步骤用于在初步查询结果的基础上执行额外的评分计算,以提高查询的精确度。常用于需要更高准确度的查询场景,例如在初步排序后进行精细的评分调整。 - 详细信息:重新评分通常涉及额外的评分模型或算法,以优化结果的排名。
与其他步骤的关系:
- 前置条件:查询结果已经从 Lucene 中检索出来,并且可能已经排序。
- 后续步骤:重新评分后的结果会合并到最终的查询结果中。
7. suggest::execute()
操作描述:
- 目的:执行建议(Suggestions)操作,如自动补全或拼写建议。
- 过程:如果查询请求中包含建议功能(如搜索建议或拼写修正),
suggest::execute()步骤会执行这些建议操作,生成相关的建议结果。 - 详细信息:建议功能通常用于提升用户体验,提供自动补全、拼写纠错等功能。
与其他步骤的关系:
- 前置条件:建议功能在查询请求中被定义。
- 后续步骤:建议结果会与查询结果一起返回,提供更丰富的用户反馈。
8. aggregation::execute()
操作描述:
- 目的:执行聚合(Aggregations)操作。
- 过程:如果查询请求中包含聚合操作(如统计分析、分组等),
aggregation::execute()步骤会计算聚合结果。聚合可以包括计数、平均值、最大值、最小值等统计信息。 - 详细信息:聚合操作在查询执行过程中并行计算,以便生成分析数据和统计结果。
与其他步骤的关系:
- 前置条件:查询条件和聚合请求已经解析和处理。
- 后续步骤:聚合结果会与查询结果一起返回,用于数据分析和报告。
总结
Send Request to Query Shard是一个包含多个子操作的步骤,它负责将查询请求实际发到分片上执行。这个步骤的子操作包括:Create Search Context:创建搜索上下文。Parse Query:解析查询请求。Get From Cache:检查并获取缓存中的结果。Add Collectors:添加用于处理结果的收集器。lucene::search:在 Lucene 索引中执行查询。rescore:对结果进行重新评分。suggest::execute():执行建议功能。aggregation::execute():执行聚合操作。
这些操作共同工作,以确保查询能够高效地执行,并返回准确的结果。每个步骤都是查询处理流程中的关键部分,确保从查询请求到最终结果的整个过程顺利进行。
五、Fetch phase
是查询的第二阶段,用于从分片中获取匹配文档的详细内容。这个阶段通常是在查询阶段(query phase)之后执行的,它的目标是获取所需的文档数据,以满足查询请求中的详细内容需求。
1. Load Stored Fields
操作描述:
- 目的:从磁盘中加载存储的字段。
- 过程:在 Elasticsearch 中,字段可以被标记为“stored”(存储的),即它们的原始值会被存储在索引中。
Load Stored Fields操作用于加载这些字段的值,并返回给用户或用于进一步处理。 - 详细信息:存储字段通常用于存储那些在查询结果中需要直接返回的原始字段数据。加载存储字段时,Elasticsearch 会从磁盘上的 Lucene 索引中读取这些字段的值。
与其他步骤的关系:
- 前置条件:查询已经定位到需要提取的文档,并且这些文档包含存储的字段。
- 后续步骤:加载的字段数据可以直接返回或用于进一步处理,如高亮显示(Highlighting)。
2. Load Source
操作描述:
- 目的:从
_source字段中加载文档的原始 JSON 数据。 - 过程:
_source是 Elasticsearch 自动存储的一个字段,包含文档的原始 JSON 内容。Load Source操作用于从_source字段中读取并加载整个文档的原始数据。 - 详细信息:这个操作通常用于在查询返回中包含完整的文档内容,或在处理需要访问文档完整结构的请求(如脚本字段或聚合操作)时使用。
与其他步骤的关系:
- 前置条件:文档已经被识别,需要提取其完整的 JSON 数据。
- 后续步骤:
_source数据可以用于返回给用户、进行字段提取、或执行高亮处理。
3. Load Doc Values
操作描述:
- 目的:加载用于排序、聚合和脚本计算的文档值(Doc Values)。
- 过程:
Doc Values是 Elasticsearch 中的一种结构化数据存储格式,用于高效地支持排序、聚合、和脚本操作。Load Doc Values操作会从磁盘中加载这些值,用于执行查询请求中的排序、聚合等操作。 - 详细信息:
Doc Values是一个面向列的存储格式,每个字段的数据都单独存储,以便快速访问。对于需要排序或聚合的查询,这个操作是必需的。
与其他步骤的关系:
- 前置条件:查询请求需要对文档进行排序、聚合或其他基于文档值的计算。
- 后续步骤:加载的
Doc Values可以用于执行排序、聚合操作,或者在脚本字段中进行计算。
4. Extract Highlight
操作描述:
- 目的:从文档内容中提取高亮信息,以显示查询匹配的部分。
- 过程:
Extract Highlight操作用于在查询结果中标记和提取那些与查询条件匹配的字段或文本片段,并应用高亮显示。这个操作通常用于在搜索结果中突出显示用户查询匹配的部分,以提高可读性。 - 详细信息:高亮提取通常会涉及对
_source数据进行分析,将匹配的词条或字段用特定的标记包围起来。Elasticsearch 提供了多种高亮方式,如plain、fast-vector-highlighter和unified。
与其他步骤的关系:
- 前置条件:文档内容已经被加载,通常包括
_source数据。 - 后续步骤:高亮信息将被合并到最终的查询结果中,以返回给用户。
关系总结
这些步骤在 Fetch Phase 中共同工作,以确保从分片中提取的文档包含用户查询所需的所有信息。它们之间的关系可以概括如下:
Load Stored Fields:先从磁盘中加载存储的字段数据。如果查询只需要特定的存储字段,这一步可能是唯一需要的步骤。Load Source:加载文档的完整_source数据,用于需要返回整个文档或执行基于文档完整内容的操作(如高亮或脚本字段计算)。Load Doc Values:针对需要排序、聚合或其他基于文档值的计算的查询,从磁盘加载Doc Values。这是确保查询结果按预期排序和聚合的关键步骤。Extract Highlight:从加载的文档数据中提取匹配查询条件的高亮信息,提供更友好的用户搜索体验。
总体流程
- 查询到达
Fetch Phase后,首先确定需要提取的文档字段和内容。 - 根据需求执行
Load Stored Fields、Load Source、和Load Doc Values。 - 最后,执行
Extract Highlight,提取高亮信息,将所有数据汇总,形成最终返回给用户的查询结果。
六、搜索流程图
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号