YoloV8实战:使用YoloV8实现OBB框检测


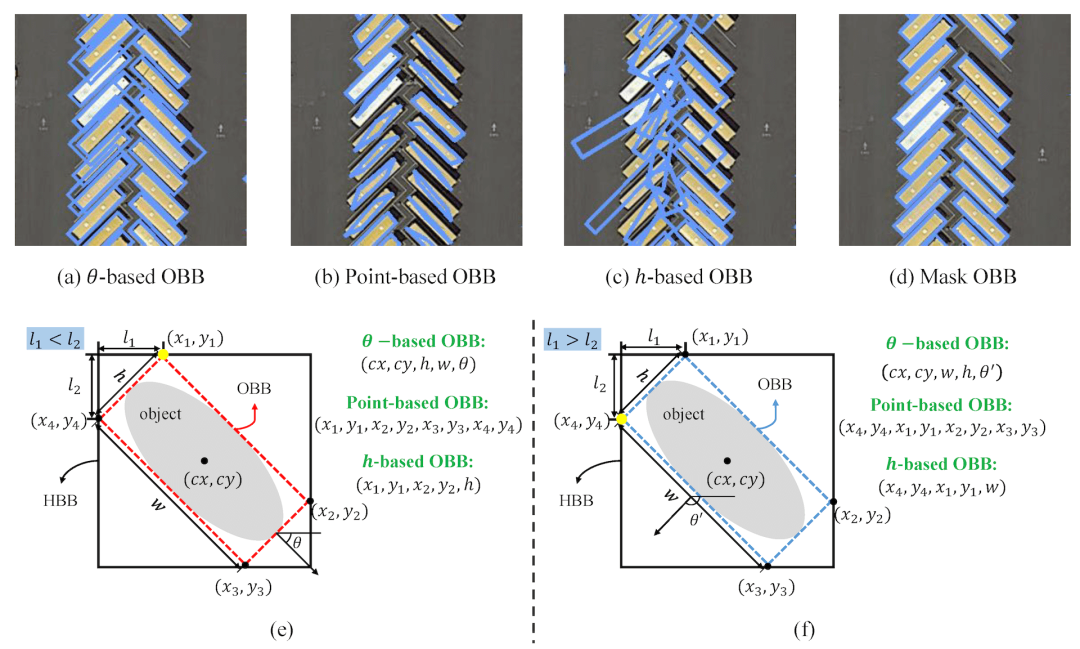
定向边框(OBB)数据集概述
使用定向边界框(OBB)训练精确的物体检测模型需要一个全面的数据集。本文解释了与Ultralytics YOLO 模型兼容的各种 OBB 数据集格式,深入介绍了这些格式的结构、应用和格式转换方法。数据集使用DOTA。
完整链接:
https://blog.csdn.net/m0_47867638/article/details/141654750?spm=1001.2014.3001.5501YOLO支持的 OBB 格式
在Ultralytics YOLO 模型中,OBB 由YOLO OBB 格式中的四个角点表示。这样可以更准确地检测到物体,因为边界框可以旋转以更好地适应物体。其坐标在 0 和 1 之间归一化:
class_index x1 y1 x2 y2 x3 y3 x4 y4
YOLO 在内部处理损失和输出是xywhr 格式,xy表示边界框的中心点、whr表示宽度、高度和旋转角度。
OBB 格式示例
例如:
0 0.780811 0.743961 0.782371 0.74686 0.777691 0.752174 0.776131 0.749758
YoloV8实现OBB训练、测试
YOLOv8 这里显示的是在DOTAv1数据集上预训练的 OBB 模型。
首次使用时,模型会自动从最新的Ultralytics 版本下载。
模型 | 尺寸 (像素) | mAPtest50 | 速度CPU ONNX (毫秒) | 速度 A100 TensorRT (毫秒) | params(M) | FLOPs(B) |
|---|---|---|---|---|---|---|
YOLOv8n-obb | 1024 | 78.0 | 204.77 | 3.57 | 3.1 | 23.3 |
YOLOv8s-obb | 1024 | 79.5 | 424.88 | 4.07 | 11.4 | 76.3 |
YOLOv8m-obb | 1024 | 80.5 | 763.48 | 7.61 | 26.4 | 208.6 |
YOLOv8l-obb | 1024 | 80.7 | 1278.42 | 11.83 | 44.5 | 433.8 |
YOLOv8x-obb | 1024 | 81.36 | 1759.10 | 13.23 | 69.5 | 676.7 |
训练
yolo已经有自己配置好的脚本文件,直接调用就可以实现,代码如下:
from ultralytics import YOLO
import os
if __name__ == '__main__':
model = YOLO(model="ultralytics/cfg/models/v8/yolov8l-obb.yaml") # 从头开始构建新模型
print(model)
# Use the model
results = model.train(data="DOTAv1.5.yaml", patience=0, epochs=300, device='0', batch=8, seed=42) # 训练模
如果想加载预训练模型,则使用:
model = YOLO("ultralytics/cfg/models/v8/yolov8l-obb.yaml").load("yolov8l-obb.pt") # build from YAML and transfer weights
或者直接加载预训练模型,如下:
model = YOLO("yolov8l-obb.pt") # load a pretrained model (recommended for training)
验证
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n-obb.pt") # load an official model
model = YOLO("path/to/best.pt") # load a custom model
# Validate the model
metrics = model.val(data="dota8.yaml") # no arguments needed, dataset and settings remembered
print(metrics.box.map) # map50-95(B)
print(metrics.box.map50) # map50(B)
print(metrics.box.map75) # map75(B)
print(metrics.box.maps) # a list contains map50-95(B) of each category
这样做虽然简单,但是有个问题,就是DOTA的图片太大了,直接ReSize比较小的图片,那些比较小的物体就没有了!所以,还有一种常用的做法就是裁切。接下来我先介绍DOTA数据集,然后详细讲解如何裁切。
DOTA数据集
DOTA是一个专门的数据集,侧重于航空图像中的物体检测。该数据集源于 DOTA 系列数据集,提供了用定向边框(OBB)捕捉的各种航空场景的注释图像。

主要功能
收集来自不同传感器和平台的图像,图像大小从 800 × 800 到 20,000 × 20,000 像素不等。 提供超过 170 万个定向边框,涵盖 18 个类别。 包含多尺度物体检测。 专家使用任意(8 d.o.f.)四边形对实例进行标注,捕捉不同比例、方向和形状的物体。
数据集版本
DOTA-v1.0
包含 15 个常见类别。类别:'plane', 'baseball-diamond', 'bridge', 'ground-track-field', 'small-vehicle', 'large-vehicle', 'ship', 'tennis-court', 'basketball-court', 'storage-tank', 'soccer-ball-field', 'roundabout', 'harbor', 'swimming-pool', 'helicopter' 包括 2 806 幅图像,188 282 个实例。 分割比例:1/2用于训练,1/6用于验证,1/3用于测试。
DOTA-v1.5
包含与 DOTA-v1.0 相同的图像。 非常小的实例(小于 10 像素)也有注释。 增加一个新类别:"集装箱起重机"。类别:'plane', 'baseball-diamond', 'bridge', 'ground-track-field', 'small-vehicle', 'large-vehicle', 'ship', 'tennis-court', 'basketball-court', 'storage-tank', 'soccer-ball-field', 'roundabout', 'harbor', 'swimming-pool', 'helicopter','container crane' 共计 403 318 次。 为 "2019 年航空图像中的物体检测 DOAI 挑战赛 "发布。
DOTA-v2.0
收集自Google 地球、GF-2 卫星和其他航空图像。 包含 18 个常见类别。类别:'plane', 'baseball-diamond', 'bridge', 'ground-track-field', 'small-vehicle', 'large-vehicle', 'ship', 'tennis-court', 'basketball-court', 'storage-tank', 'soccer-ball-field', 'roundabout', 'harbor', 'swimming-pool', 'helicopter','container crane','airport','helipad' 包括 11,268 幅图像和多达 1,793,658 个实例。 引入新类别:"机场 "和 "直升机停机坪"。 图像分割: 训练:1,830 幅图像,268,627 个实例。 验证:593 幅图像,81 048 个实例。 Test-dev:2 792 幅图像,353 346 个实例。 测试挑战:6,053 幅图像,1,090,637 个实例。
到这里你是不是对DOTA数据集有了一定的了解。接下来讲解如何裁切? 官方链接:https://captain-whu.github.io/DOTA/
1.5-2.0版本下载链接:https://hyper.ai/datasets/15632,这个下载快!
图像裁剪
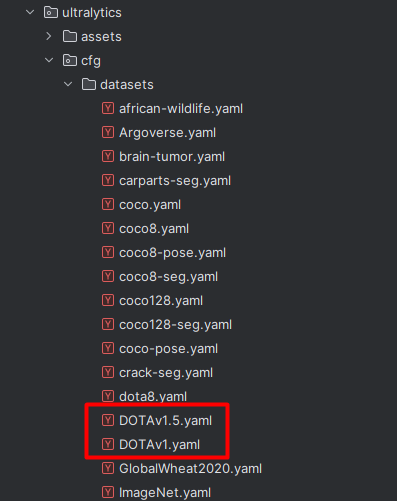
第一种裁剪方法:直接使用YoloV8自己带的裁剪方法
这里用1.5版本的,链接如下:https://github.com/ultralytics/assets/releases/download/v0.0.0/DOTAv1.5.zip。YoloV8自带的数据集是将png转为jpg了,所以很小。这一点大家自行对比! 下载后的数据集是这样的,在datasets文件夹下面,如下图:
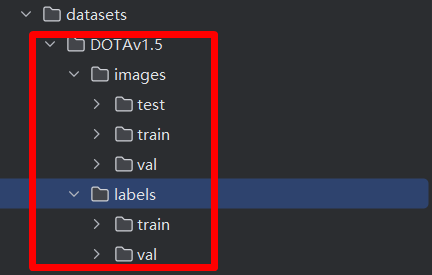
在项目的根目录新建脚本split.py,代码如下:
from ultralytics.data.split_dota import split_test, split_trainval
# split train and val set, with labels.
split_trainval(
data_root="./datasets/DOTAv1.5/",
save_dir="./datasets/DOTAv1.5-split/",
rates=[0.5, 1.0, 1.5], # multiscale
gap=500,
)
# split test set, without labels.
split_test(
data_root="./datasets/DOTAv1.5/",
save_dir="./datasets/DOTAv1.5-split/",
rates=[0.5, 1.0, 1.5], # multiscale
gap=500,
)
裁切成1024×1024大小的图片,如下图:
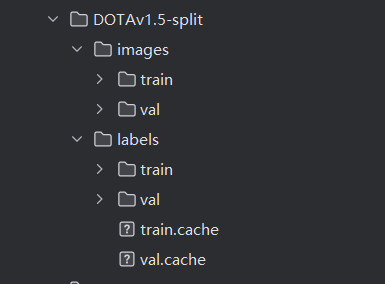
我看到有人说,labels里面的文件和images里面的对不上,那是因为有的txt没有物体,所以省略了。
修改配置文件DOTAv1.5.yaml,如下图:
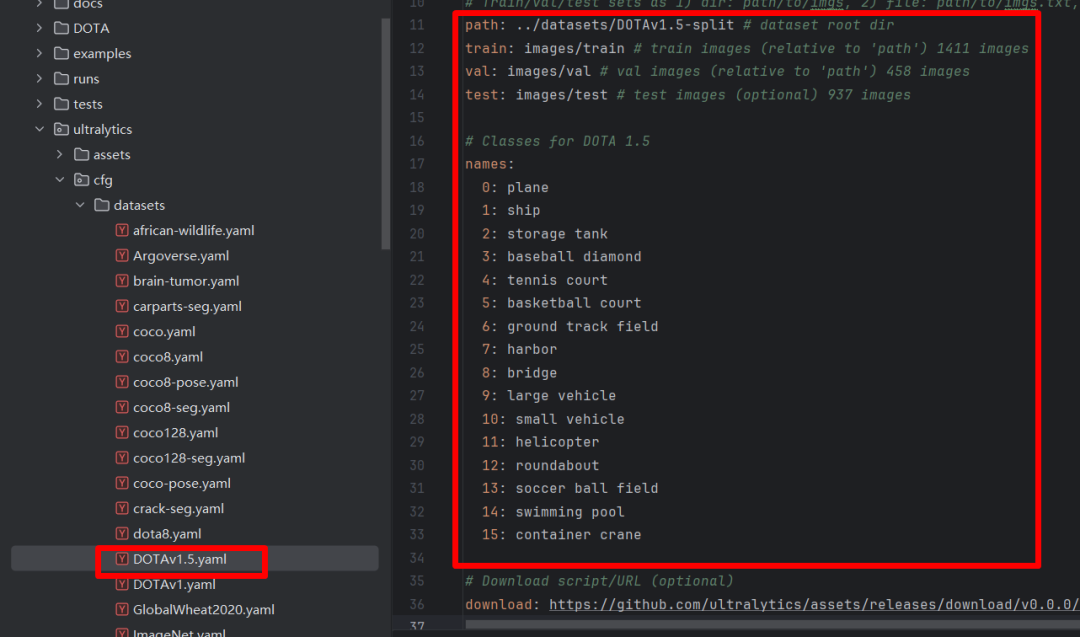
代码:
path: ../datasets/DOTAv1.5-split # dataset root dir
train: images/train # train images (relative to 'path') 1411 images
val: images/val # val images (relative to 'path') 458 images
test: images/test # test images (optional) 937 images
# Classes for DOTA 1.5
names:
0: plane
1: ship
2: storage tank
3: baseball diamond
4: tennis court
5: basketball court
6: ground track field
7: harbor
8: bridge
9: large vehicle
10: small vehicle
11: helicopter
12: roundabout
13: soccer ball field
14: swimming pool
15: container crane
# Download script/URL (optional)
download: https://github.com/ultralytics/assets/releases/download/v0.0.0/DOTAv1.5.zip
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-08-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号