Moonshine 用于实时转录和语音命令的语音识别 !

Moonshine 用于实时转录和语音命令的语音识别 !

AIGC 先锋科技
发布于 2024-11-11 19:48:21
发布于 2024-11-11 19:48:21

这篇论文介绍了一种名为Moonshine的语音识别模型系列,该模型针对实时转录和语音命令处理进行了优化。 Moonshine基于编码器-解码器 Transformer 架构,并采用旋转位置嵌入(RoPE)替代传统的绝对位置嵌入。 该模型在各种长度的语音片段上进行训练,但不需要使用零填充,从而在推理时间内提高了编码器的效率。 在与 OpenAI 的 Whisper tiny.en 进行基准测试时,Moonshine Tiny在转录10秒语音片段时,计算需求降低了5倍,同时在不增加标准评估数据集中的单词错误率。 这些结果突显了 Moonshine 在实时和资源受限应用中的潜力。
1 Introduction
实时自动语音识别(ASR)对于许多应用至关重要,包括在演讲中的实时转录、听力障碍人士的辅助工具以及智能设备和可穿戴设备中的语音命令处理。这些应用通常直接在低成本硬件上运行,严格的资源约束和缺乏互联网连接带来了其他ASR领域所不存在的独特技术挑战。
开源AI的Whisper的引入显著提高了通用ASR系统的准确性(Radford等人,2022年)。然而,在应用设备端ASR的一个主要挑战是,在不损失准确性的情况下,最小化延迟 —— 语音输入与对应文本出现之间的时延,例如在实时转录显示器上(例如)。在作者开发的一个这样的应用 —— 一个用于提供快速、准确、私下离线英语音频转录的Caption Box——的开发过程中,作者发现现有模型不适合这个任务。在低成本的基于ARM的处理器上部署时,作者注意到,即使是Whisper tiny.en模型,其最小延迟下限也达到了500毫秒,与音频持续时间无关。用户反馈表明,这种延迟水平无法提供平滑和响应的用户体验,这促使作者深入调查。
Whisper,这是一种基于编码器-解码器 Transformer 架构的系统,会以30秒为一组处理固定长度的音频序列,无论音频的实际内容是什么。这意味着较短的音频序列需要用零填充以满足长度要求,导致编码器中存在恒定的计算开销。虽然解码器的处理时间与语句长度成正比,但固定长度编码的恒定开销对延迟产生了明确的下限,例如作者在自己的测试中确定的500毫秒(以Caption Box的测试结果为准)。
作者最初的尝试是通过微调和解耦1个Whisper模型来处理编码器中的可变长度序列,利用开放的音频数据集。然而,这些开放的音频数据集证明不足以超越Whisper的单词错误率(WER)。认识到现有数据的限制和利用模型架构的最新进展的机会,作者决定从头开始开发和训练新的模型。
作者的第一个任务是更好地量化Whisper固定长度编码器带来的 Bottleneck 。在实证测试中,作者将处理30秒零填充音频所需的GFLOPS(即十亿浮点运算)与处理同样音频的30秒子集所需的GFLOPS进行了比较(即,作者测量了如果Whisper有一个可变长度编码器而不是固定长度编码器,速度可以提升多少)。作者的结果(图1)显示了在最佳情况下有35倍的速度提升潜力,总体上几乎有5倍的速度提升。显然,改进Whisper架构可以产生轻量级、低延迟的语音转文本模型,这些模型更适合资源受限的应用。
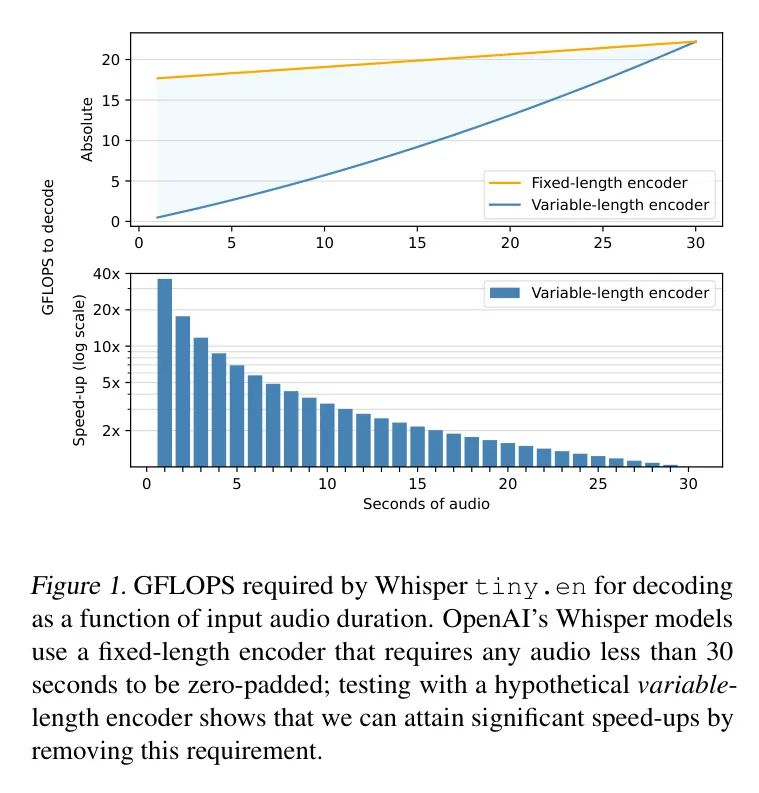
针对设备上的低延迟ASR应用面临的挑战,本文介绍了Moonshine系列ASR模型。Moonshine模型旨在同时匹配Whisper的准确性并优化计算效率,通过消除填充要求,而是按比例扩展处理需求,而不是依赖零填充。
作者描述了Moonshine的架构和训练过程,并详细分析了与Whisper模型相比的性能优势。第2部分通过量化为变长音频调整Whisper的WER来阐明作者开发Moonshine的原因。第3部分描述了Moonshine的架构、数据集准备和训练过程,而第4部分在标准语音识别数据集上提供了结果的评估。第5部分得出结论。
2 Issues with fixed sequence length encoder
whispered 模型在编码器和解码器中都使用了绝对位置嵌入。特别是,编码器使用了形状为[1500, dim]的余弦位置嵌入,其中dim是 Transformer 编码器的维度。OpenAI 提供的标准推理代码在将输入音频填充到精确的30秒段后传递给模型。音频特征生成和2个卷积层将这个音频段转换为一个[1500, dim]的向量序列,该序列被添加到余弦位置嵌入中。图2的左边一列说明了这一机制。
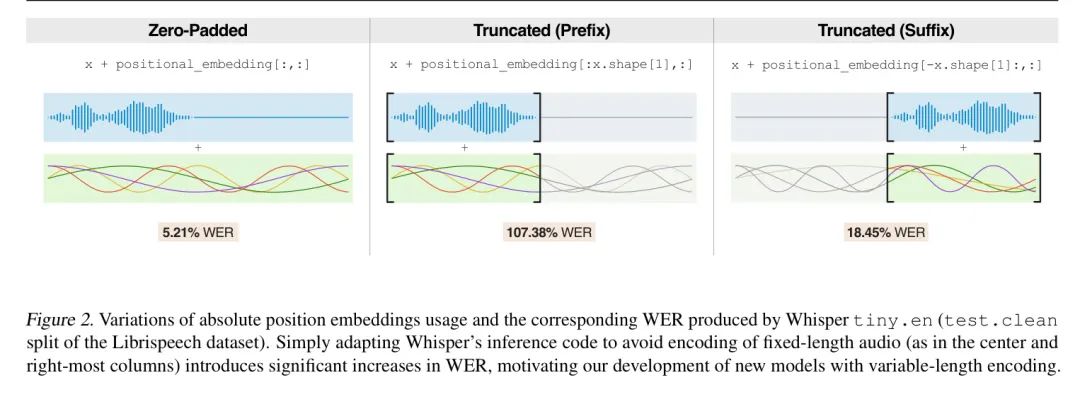
需要一个精确的30秒片段会导致编码器承担固定的计算成本,无论音频片段的实际持续时间。然而,由于Whisper的模型架构是一个即用即弃的、可变长度的序列到序列 Transformer ,填充并不严格必要。实际上,一个短于30秒的音频片段可以通过模型的前端处理,得到一个[seq_length, dim]的向量序列,其中seq_length <= 1500。
有多种方法可以将位置嵌入添加到可变长度的音频输入中。作者比较了OpenAI Whisper推理代码中的默认实现(即使用零填充形成30秒片段)以及另外两种方法,如图2的中心和右上角所示——即使用位置嵌入的前缀和后缀。作者在Librispeech数据集的测试.clean分割上使用这两个选项计算了WER。
这个分割有2620个示例,其中9个超过30秒的长度。作者在这次评估中忽略这9个示例。作者使用束搜索大小为5,以避免贪婪解码的陷阱,如重复。使用OpenAI提供的标准推理代码,作者得到了5.21%的WER。然而,如果不进行零填充,作者得到的结果会更差。
当只使用位置嵌入的前缀时,tiny.en模型具有107.38%的WER。作者注意到在转录的末尾出现了大量的重复,即使使用束搜索也是如此。当使用位置嵌入的后缀时,准确率下降并不像使用前缀那样剧烈,得到了18.45%的WER——仍然比 Baseline 差三倍多。
这些结果表明,OpenAI Whisper模型都是用完全为30秒的示例进行训练的。这些模型确实可以生成高质量的转录,对于长音频来说效果很好。
然而,为了他们的编码器,需要固定的计算预算,这使得它们在低延迟应用(如实时转录)中效率低下。由于这些应用中的音频片段往往较短且/或长度不同,因此作者努力训练针对可变长度序列的模型是很有必要的。
3 Approach
本节描述了Moonshine模型架构,随后详细介绍了作者的数据收集、预处理和模型训练过程。
Model architecture
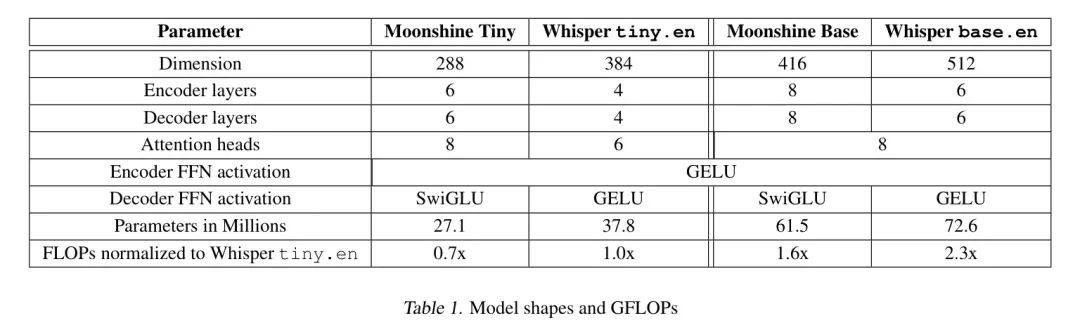
月光是一种开源的编码器-解码器Transformer模型。输入是一个以16,000 Hz采样的音频信号。作者没有使用任何手工设计(例如,Mel频谱图)来提取音频特征。相反,输入通过一个由3个卷积层组成的小主干处理,其中步长分别为64、3和2。卷积核宽度、通道数和激活函数如图3所示。这些步长将输入压缩了384倍。
请注意,在Whisper模型中,输入通过320倍压缩 - 首先在Mel频谱图计算中压缩160倍,然后在卷积主干中进一步压缩2倍。作者在编码器和解码器的每个层中使用旋转 Transformer 位置嵌入(RoPE)(Su等人,2023年)。表1将Moonshine的架构与OpenAI的Whisper模型进行了比较。
作者使用与Llama 1和2中相同的字节级BPE文本分词器对英语文本进行分词。原始词汇大小为32000;作者添加了768个特殊 Token 以供未来扩展。
Training data collection & preprocessing
作者在公开的ASR数据集(约90000小时)和自建的超过100000小时的数据集(总计约200000小时)上训练Moonshine。从公开数据集中,作者使用Common Voice 16.1,AMI语料库 ,GigaSpeech,LibriSpeech ,多语言LibriSpeech的英语子集,以及People's Speech。然后,作者用从公开可获取的来源收集的数据增强这个训练语料库。关于作者自建数据的准备方法,将在以下内容中讨论。
许多在线语音资源有字幕或 captions 可用,这些可以作为标签。但是, captions 通常很嘈杂它们可能是人工生成的,因此可能包含与音频内容正交的文本,或者包含发言人的名字或非语言内容的口头描述。
在可能存在人工生成但可能不可靠的 captions 的情况下,作者使用启发式过程来过滤低质量的实例。首先,作者将 captions 文本转换为小写并规范化,删除或替换例如歧义性的 unicode 字符、 emoji 和标点符号。然后,作者使用 Whisper large v3 来生成音频内容的伪标签,并对这个伪标签应用与作者对 captions 应用的相同的文本规范化。
最后,作者计算规范化后的 captions 和伪标签之间的 Levenshtein 距离(在 之间,其中 相同而 正交),过滤掉距离高于阈值的标签。这使作者能够将人类生成的 captions 中的标签视为真实值,同时避免引入过多的噪声。在过滤掉嘈杂的标签后,作者通过应用标准化的标点和大小写来准备剩余的文本。
预处理无标签语音。 在网络上可用的语音中,大部分是无标签的。在这些情况下,作者利用Whisper large v3模型为作者的轻量级Moonshine模型生成训练标签。训练一个模型在另一个模型的输出上的风险是新模型学习到旧模型的错误。通过检查,作者发现Whisper large v3产生的大多数幻觉输出出现在平均对数概率的可预测值以下。
因此,作者通过过滤平均对数概率低于这个阈值的实例来减少引入幻觉和其他噪声的风险。在此过程中,作者从WhisperX实现(Bain等,2023)的批处理推理中受益。
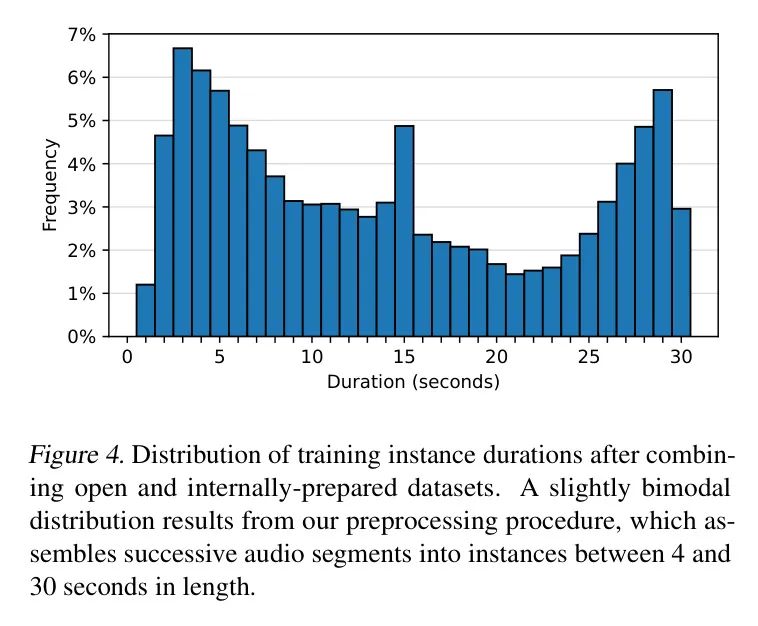
控制实例持续时间。作者将连续的语音段组装成更长的训练实例,使得实例的持续时间在[4,30]秒之间,且连续段之间的时间不超过2秒。对于作者手动的标注数据来源,作者使用字幕文件(例如,an.srt文件)提供的定时段;
对于作者的伪标签音频,作者使用Whisper生成的时标。将此数据与开源数据集结合后,作者的汇总训练实例中的实例持续时间遵循图4所示的略微双峰分布。
Training
作者在32x H100 GPU集群上进行了训练,使用了Huggingface的Accelerate库提供的GPU数据并行(Gugger等人,2022年)。
作者使用了Accelerate的BF16混合精度优化。作者在每个GPU上训练了250K步,批处理量为32(1024个全局批处理量)。
作者使用了无计划调度优化器的AdamW变体(Defazio等人,2024年);在8192步后,梯度范数剪裁和初始学习率升温到1.4e-3。
4 Evaluations
作者在OpenAI的Whisper模型(尤其是Whisper tiny.en和base.en)上衡量Moonshine的性能。这两者是最适合在低成本边缘设备上运行的,因为它们的内存和计算要求较低。作者在OpenASR领导者排行榜(Srivastava等人,2023)上的数据集上测量了WER。作者使用贪心解码,每个音频秒输出的启发式限制为6个输出 Token ,以避免重复输出序列。
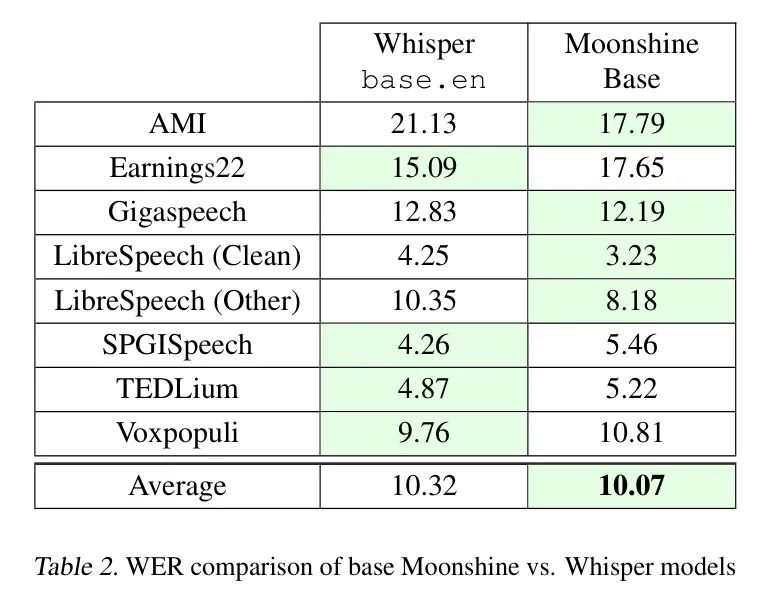
月光之子和基础模型在平均WER方面优于其Whisper对应模型(分别为tiny.en和base.en),如表2和表3所示。Earnings22是Moonshine在Whisper方面表现最差的的数据集。Earnings22中的8%的示例长度不到1秒,相应的转录是诸如"So.","Yes.","Okay."等简短语句。Moonshine模型在这样例子输出中往往产生重复的 Token ,导致WER大于100%。在作者训练集中,不到0.5%的示例短于1秒。作者推测这可能减弱了Moonshine模型对Earnings22数据集的泛化能力。
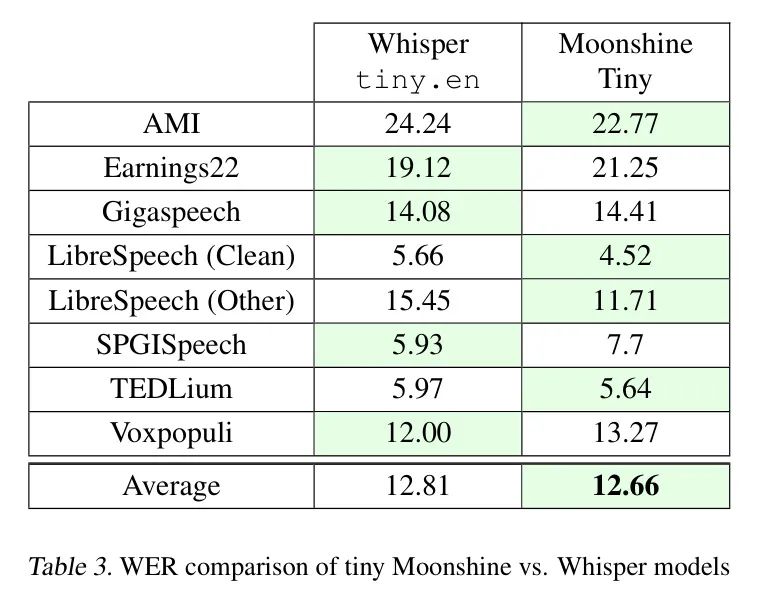
Accuracy vs. Input Length
月光模型展示了将不同长度的音频片段转录的能力。然而,作者假设较短的输入可能会由于缺乏足够的上下文信息而导致更高的WER。相反,对于较长的剪辑(尤其是超过训练期间观察到的序列长度),由于虚构,转录错误显著增加。为了评估这种行为,作者在TEDLium数据集的不同音频片段中测量了WER,这些片段的长度在10秒到55秒之间变化。
为了评估不同剪辑长度下的推理速度,作者在GPU(H100)上比较了Moonshine和Whisper。结果如图5所示。
速度比较仅限于Whisper的30秒最大剪辑,因为更长的剪辑需要多次Whisper运行,引入了开销,并且不公平地偏向Whisper的结果。Moonshine在编码器中支持可变序列长度,因此在较短序列上表现优越,性能优于Whisper。
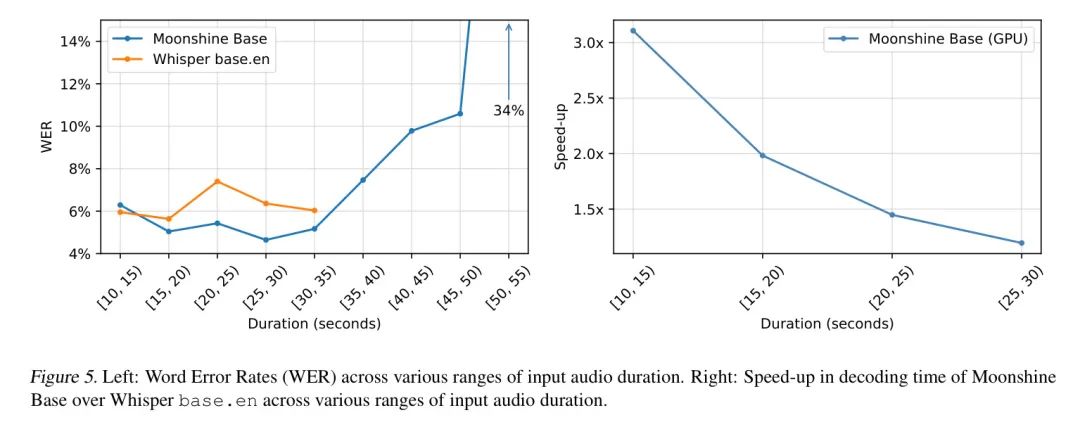
Robustness to Input Speech Signal Level
在这项工作中,作者观察到Whisper模型的鲁棒性取决于输入语音信号的 Level 。为了衡量输入 Level (即线性增益)对Moonshine的影响,作者测试了模型在不同增益下对数据集中的音频样本的鲁棒性。
如图6左部分所示,Moonshine Base在大部分这个范围内保持了优越的WER,直到输入语音信号非常衰减。在这个点(即增益低于-40 dB,即输入音频非常安静)时,WER超过了Whisper模型。对于在系统设计中可以避免高语音衰减的实际应用,Moonshine Base对输入 Level 的变化具有鲁棒性。
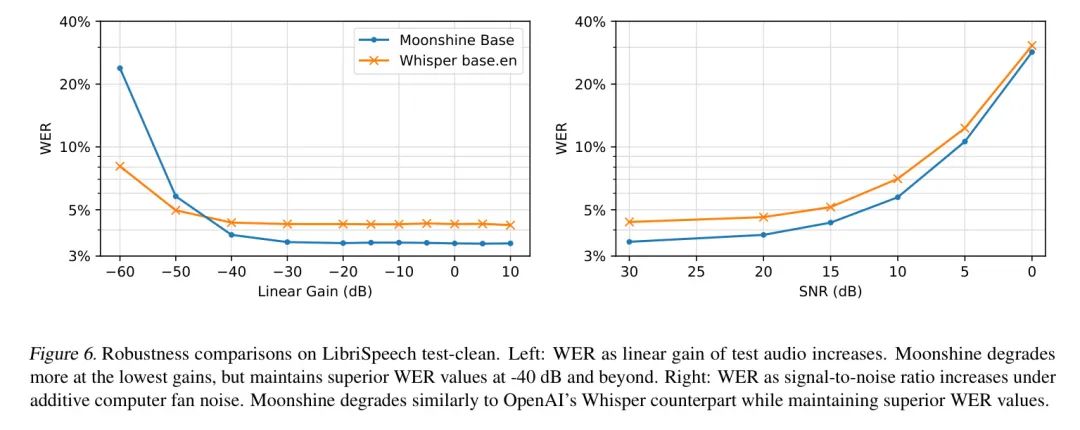
Robustness to Additive Noise
作者通过在平板电脑应用负载下测量风扇噪声的WER来测试Moonshine Base模型的抗噪声性能。在用户研究中,作者根据发言人的不同,在[9, 17] dB的范围内量化了该应用的信号噪声比(SNR)。
作者根据单个数据集示例的平均信号功率(去掉安静部分)计算出对应给定SNR的加性噪声 Level 。图6的右侧部分展示了风扇噪声增加时性能如何降低。Whisper的抗噪声能力已知;而Moonshine Base在保持这种抗噪声能力的同时,提供了更优越的WER。
5 Discussion & Conclusion
架构和优化器:正如任何此类研究一样,可以探索多种模型架构的变体。同样,在优化器方面,最近的研究取得了进步,尤其是Shampoo(Gupta等人,2018年)和SOAP(Vyas等人,2024年)在提高作者的架构的WER方面具有前景。对这些模型架构和训练方法进行消融研究,将显著增强社区对模型限制的了解。然而,由于资源限制,特别是GPU的有限可用性,这些研究超出了本文的范围。因此,作者根据作者的经验和对相关文献的全面审查,选择了作者的架构和优化器。
扩展到较短的音频片段. 在Earnings22数据集上观察到的相对较低的性能,激励了收集更具代表性的数据,并研究训练技术以在模型中引入更多的上下文信息。这可能会在不改变架构的情况下提高模型性能。
在本文中,作者介绍了Moonshine,这是一个为低延迟、设备上的语音转文字应用优化的轻量级ASR模型家族。作者概述了作者的模型架构、数据收集和预处理过程以及训练。
作者将 Moonshine 与两个 OpenAI Whisper 模型 tiny.en 和 base.en 进行了比较,结果显示它们的 Moonshine 对应模型在输入音频持续时间上提供了高达3倍的延迟减少。作者的工作为实时ASR在实时转录、无障碍技术和智能设备中的应用开辟了新的大门。
参考文献
[0]. Moonshine: Speech Recognition for Live Transcription and Voice Commands.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-11-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号