开放表格式的历史和演变 - 第一部分

开放表格式的历史和演变 - 第一部分

ApacheHudi
发布于 2024-11-23 13:03:15
发布于 2024-11-23 13:03:15
如果在过去几年中一直在关注数据工程领域的趋势,那么肯定已经听说过很多关于 Open Table Formats 和 Data Lakehouse 的信息。
在这篇博文中,我们将深入探讨数据环境中开放表格式的历史和演变。我们将探讨导致它们成立的挑战、定义它们的关键创新以及它们对行业的影响。
通过了解从传统数据库管理系统到现代开放表格格式的旅程,我们可以更好地了解数据技术的现状并预测未来趋势。
在第 I 部分中,我们将讨论以表格格式存储和管理数据的起源和历史,以及第一代开放表格式的出现。
在第 II 部分中[1],将讨论第二代和第三代 Open Table 格式。
表格格式的起源
以二维表格格式呈现信息一直是显示结构化数据的最基本和通用的方法,其根源可以追溯到 3500 多年的古巴比伦时期,当时最古老的表格数据[2]被记录在泥板上。
数据库表的现代概念随着关系数据库的发明而出现,受到 E.F. Codd[3]于 1970 年发表的关于关系模型的论文的启发。
从那时起,表格格式一直是关系数据库管理系统(如开创性的 System R)中管理和处理结构化数据的主要抽象。因此,存储系统中表格格式的概念并不新鲜,在过去半个世纪中一直是主要内容。
表格格式抽象
数据表是逻辑数据集,是存储在磁盘上的物理数据文件的抽象层,提供统一的二维记录表格视图。存储引擎将来自数据集的各种对象的记录组合在一起,并将它们作为一个或多个逻辑表呈现给最终用户。
这种逻辑表表示提供了解耦和隐藏数据的物理特性的优势,从而允许在不影响用户的情况下发展、优化和修改物理实现细节。
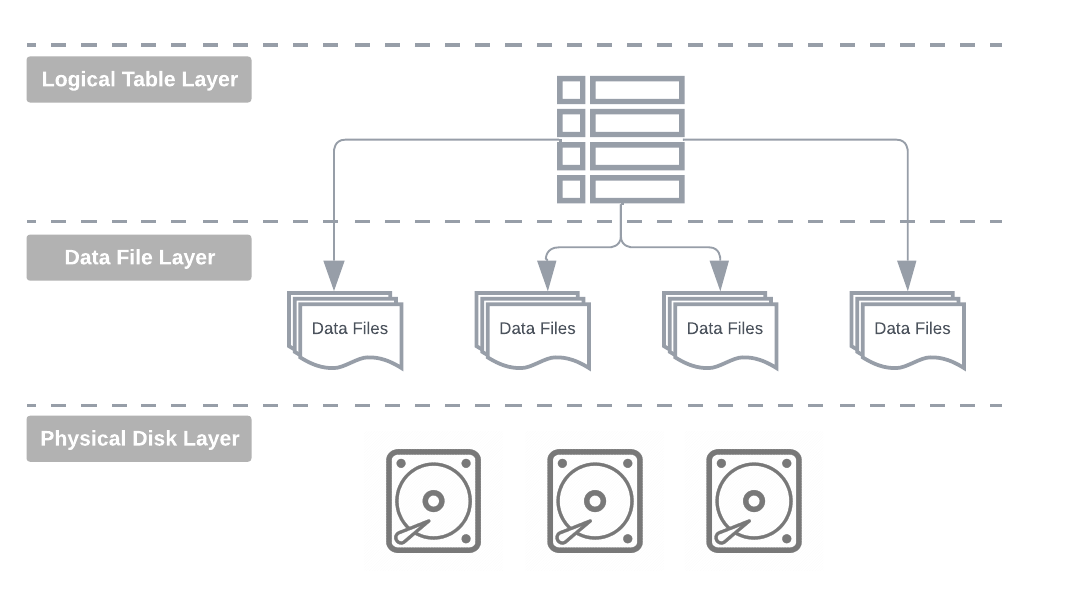
所以我们最近听到了很多关于开放表格式的信息,开放和非开放或封闭格式之间有什么区别呢?为了弄清楚这一点,让我们深入了解一下如何实现通用数据库管理系统。
关系表格式
在大数据时代和 2000 年代中期 Apache Hadoop 出现之前,传统的数据库管理系统 (DBMS) 坚持整体架构设计。
此体系结构由多个高度互连和紧密耦合的层组成,每个层专用于数据库运行所必需的特定功能,但所有组件都组合在一起以形成一个统一的系统。特别是存储层,它管理数据持久性的物理方面。
此结构的核心是 Storage Engine。此组件充当最低抽象级别,监督磁盘上数据的物理组织和管理。事务管理、并发控制、索引管理和恢复等关键任务也由存储引擎处理。
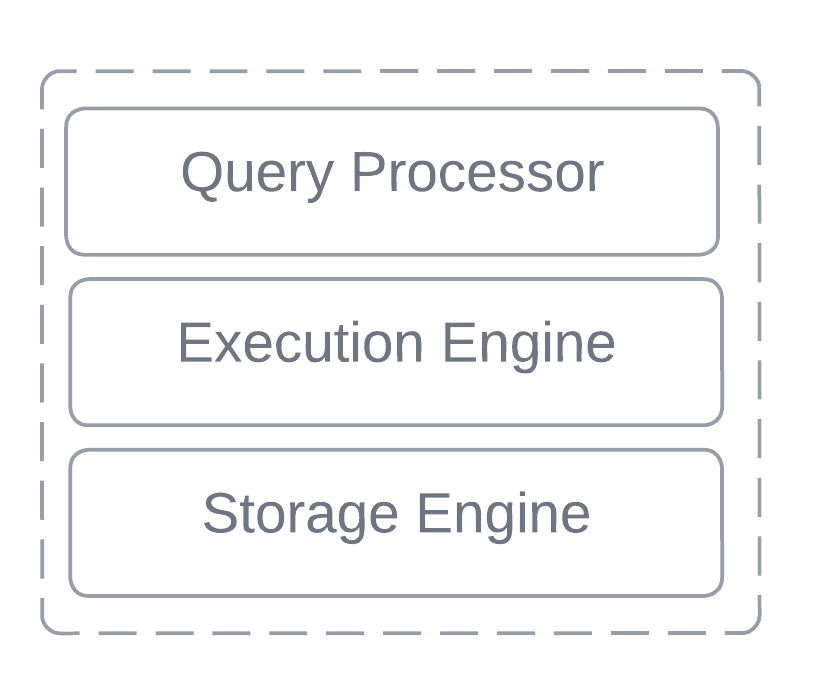
高级 DBMS 架构
至关重要的是,查询层和表示层与复杂的存储层隔离运行。数据在读取和写入操作期间遍历这些层,每个层都有自己的抽象。这种封装意味着数据的物理布局和存储格式对外部系统保持隐藏。
这意味着什么?
这意味着,不可能像我们现在那样使用其他系统或 Python 等编程语言直接访问或操作数据库的物理数据文件。
此外它缺乏互操作性,因为它不能只是将数据库文件复制到另一个系统,或者简单地将通用查询引擎指向操作系统上的数据库文件并与数据交互。
鉴于这些限制,我们今天所理解的开放表格格式 (OTF) 的概念是不存在的。传统数据库采用与其特定实施紧密集成的专有存储格式。
传统 DBMS 架构存在缺陷吗!?
许多人会争辩说,这实际上根本不是一个糟糕的设计。毕竟,普通用户不应该关心、了解甚至改变底层物理层的实现方式,因为他们可能会做出灾难性的事情!此外,还应用了大量的技术专长,将互连组件集成到复杂系统中。
考虑到软件设计最佳实践,这是一个有效的论点,因为该设计完全概括了管理它的复杂性,但权衡是这种封闭和紧密耦合的设计阻碍了互操作性、可移植性和开放协作,无法基于开放标准构建可扩展的创新系统。
但是是否有可能两全其美呢?也就是说,拥有高度可互操作、可移植、开放和可扩展的数据系统,并且仍然能够封装管理低级任务的复杂性
Hadoop 和大数据革命
让我们从 1970 年代快进到 2006 年,当时发生了大数据革命,当 Apache Hadoop 项目从 Yahoo 诞生时,数据环境发生了翻天覆地的变化,导致数据库系统的汇编[4]。
我不会讨论 Apache Hadoop 的内部结构及其架构,因为如果不熟悉它,有很多可参考的材料。但一个重大的架构突破是存储和计算的解耦。
这种基本的架构变化允许在部署在经济实惠的商用硬件上的 HDFS 分布式文件系统上以常见的半结构化文本格式(如 CSV 和 JSON)或二进制格式(如 Avro、Parquet 和 ORC)存储大量数据。
数据可以像文件一样存储在本地文件系统上,并使用所选的分布式处理框架(如 MapReduce、Pig、Hive、Impala 和 Presto)进行处理。
企业第一次可以以他们喜欢的开放格式存储大量数据,并针对各种工作负载利用不同的计算引擎,从而实现大规模分析。对于那些习惯于不灵活、昂贵、整体式存储系统和专有数据仓库的人来说,这是一个游戏规则改变者。
但正如 AMPLab 联合总监 Michael Franklin 所说[5],真正的突破是通过新的解耦架构 实现数据独立性:
真正的突破是对数据的逻辑视图和如何使用数据与实际存储数据的物理现实分开。
这就是为什么大数据在当时如此大肆宣传,从而引起如此大的兴奋——如今,围绕生成式 AI 的类似炒作[6]水平,给一些人带来了一种似曾相识的感觉。尽管如此,大数据是一场真正的革命,它摆脱了传统系统的束缚,为开放数据生态系统[7]接下来的许多创新奠定了基础。
第一代 Open Table Format 的诞生
Apache Hadoop 的初始版本给数据工程师带来了重大挑战。
使用 Java 在 MapReduce 逻辑中表达数据分析和处理工作负载 既复杂又耗时。此外,Hadoop 缺乏在其文件系统上存储和管理数据集架构的机制。
虽然工程师们很欣赏 Hadoop 的灵活性,但他们渴望熟悉的 SQL 和关系数据库固有的二维表格式。
为了弥合这一差距,Facebook(现为 Meta)发起了 Hive 项目,Facebook 是早期且有影响力的 Hadoop 采用者 。目标是将传统关系数据库中熟悉的 SQL 和表格结构引入 Hadoop 和 HDFS 生态系统。
然而一个关键的区别是它的新架构方法:
构建在解耦的物理层之上,利用存储在 HDFS 分布式文件系统上的开放数据格式。
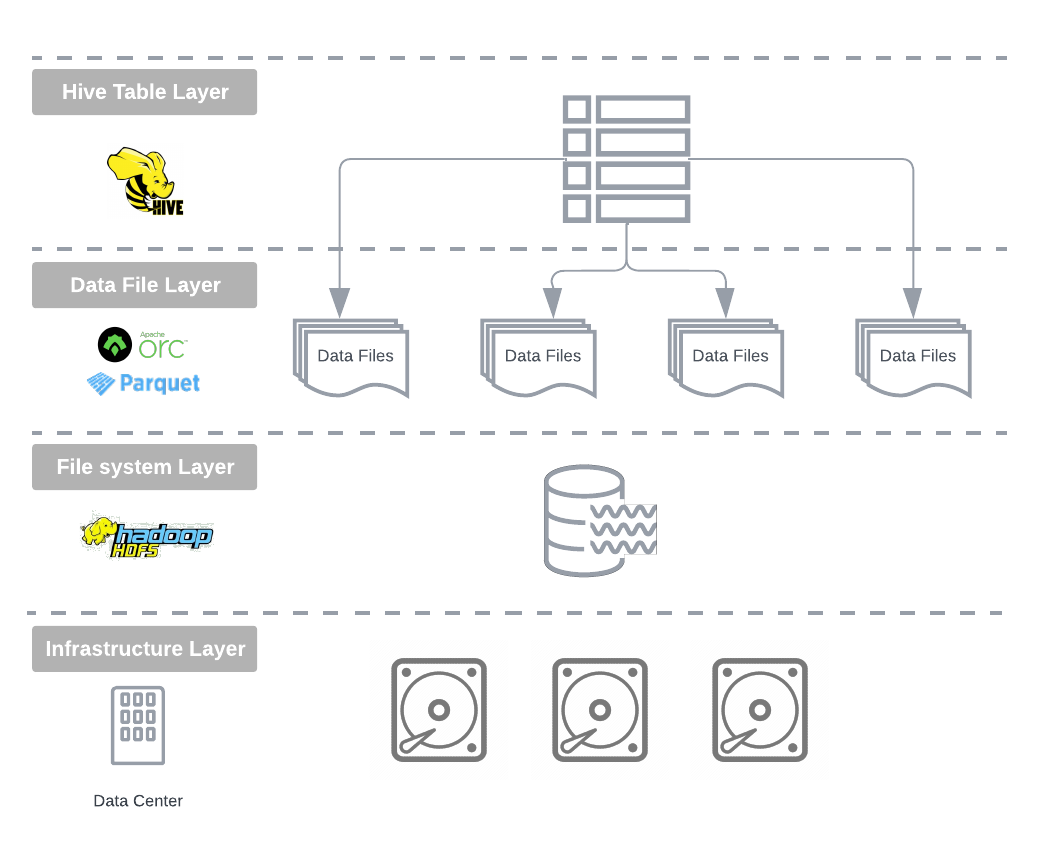
Hadoop 上的 Open Table Architecture
Apache Hive 的影响
Facebook 在 2008 年开源了 Hive,使其可供更广泛的社区使用。几年后著名的 Hadoop 供应商 Cloudera 开发了 Apache Impala。
与 Hive 类似,Impala 在 HDFS 上提供表管理,结合了架构管理以及自动文件格式转换和压缩等功能。
将 Apache Hive 和 Impala 引入 Hadoop 堆栈后,基于开放文件格式构建的开放表格式的概念诞生了。托管表和外部表以及基于目录的分区成为 Hadoop 生态系统中数据摄取、数据建模和管理的主要抽象。
这种新的数据架构使数据集成和处理管道能够独立运行,以适当的格式将数据文件加载到 HDFS 中,而无需了解数据将如何以及由哪个查询引擎使用。
列式二进制文件格式的演变
另一个关键的进步是开发了高效的列式开放文件格式。这始于 RCFiles,这是 Apache Hive 项目的第一代列式二进制序列化框架。
随后的创新包括 Apache ORC 作为 RCFile 的改进版本(于 2013 年发布)和 Apache Parquet(Twitter 和 Cloudera 的联合成果,也于 2013 年发布)。
这些新的开放文件格式极大地增强了 Hadoop 上基于 OLAP 的分析工作负载的性能,为直接在数据湖上构建 OLAP 存储引擎奠定了基础。
从那时起,ORC 和 Parquet 已成为管理数据湖上静态数据的事实标准开放文件格式,Parquet 越来越受欢迎,并在生态系统中得到更广泛的采用和支持。
接下来,我们将更深入地研究 Hive 表格式的结构,但在此之前,让我们概括一下引擎(如 Hive 和 Impala)使用的物理设计,该引擎严重依赖于文件系统目录层次结构。我们称它为面向目录的表格格式。
面向目录的表格格式
将数据视为分布式文件系统(如 HDFS,即数据湖)中的表的最基本方法涉及将表投影到包含不可变数据文件和可能的子目录以进行分区的目录中。
核心原则是在目录树中组织数据文件。从本质上讲,表只是在目录级别跟踪的文件集合,可由各种工具和计算引擎访问。
需要注意的重要因素是,这种架构本质上与物理文件系统布局相关联,依靠文件和目录操作进行数据管理。自 Hadoop 诞生以来,这一直是在数据湖中存储数据的标准做法。
基于目录的分区允许根据事件或处理日期等属性来组织文件。Schema 信息可以嵌入到数据文件中,也可以由 Schema 注册表在外部进行管理。
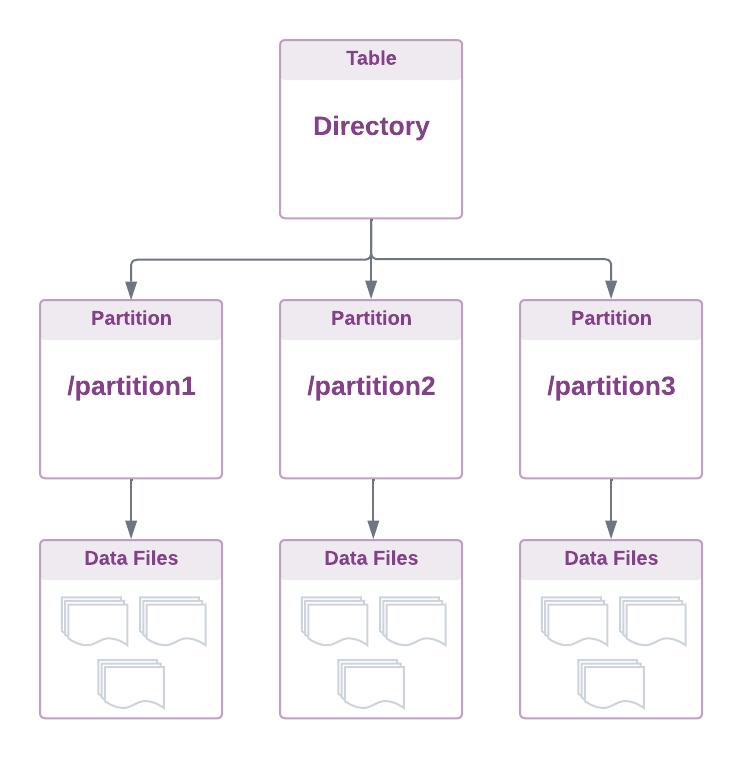
面向目录的表格格式
由于表分区表示为子目录,因此查询引擎有责任解析和扫描表示为子目录的每个分区,以便在查询规划阶段识别相关数据文件。
这意味着物理分区与表级别的逻辑分区紧密耦合,具有自己的约束,这将在后面讨论。
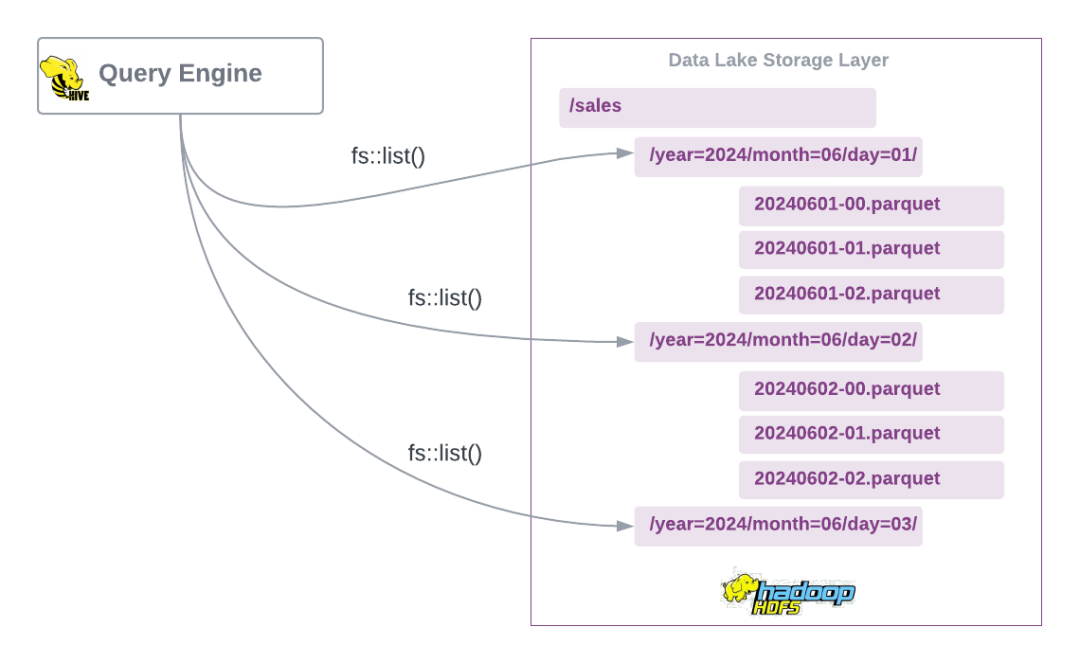
现在我们已经介绍了基于目录的表的外观,让我们看看 Hive 表格式。
Hive 表格式
对于所提供的存储模型,可以说 Apache Hive 是一种面向目录的表格式,它依赖于底层文件系统的 API 将文件映射到表和分区。因此,Hive 在很大程度上受到分布式文件系统中数据的物理布局的影响。
Hive 使用自己的分区方案,使用字段名称和值创建分区目录。它在称为 Metastore 的关系数据库中管理架构、分区和其他元数据。
到目前为止,Hive + Hadoop 的重大转变 是:
与传统的整体式数据库不同,Hadoop 和 Hive 的解耦方法允许其他查询和处理引擎使用 Hive 引擎的元数据在 HDFS 上处理相同的数据。
以下示例显示了基于年、月和日的典型 Hive 临时分区。
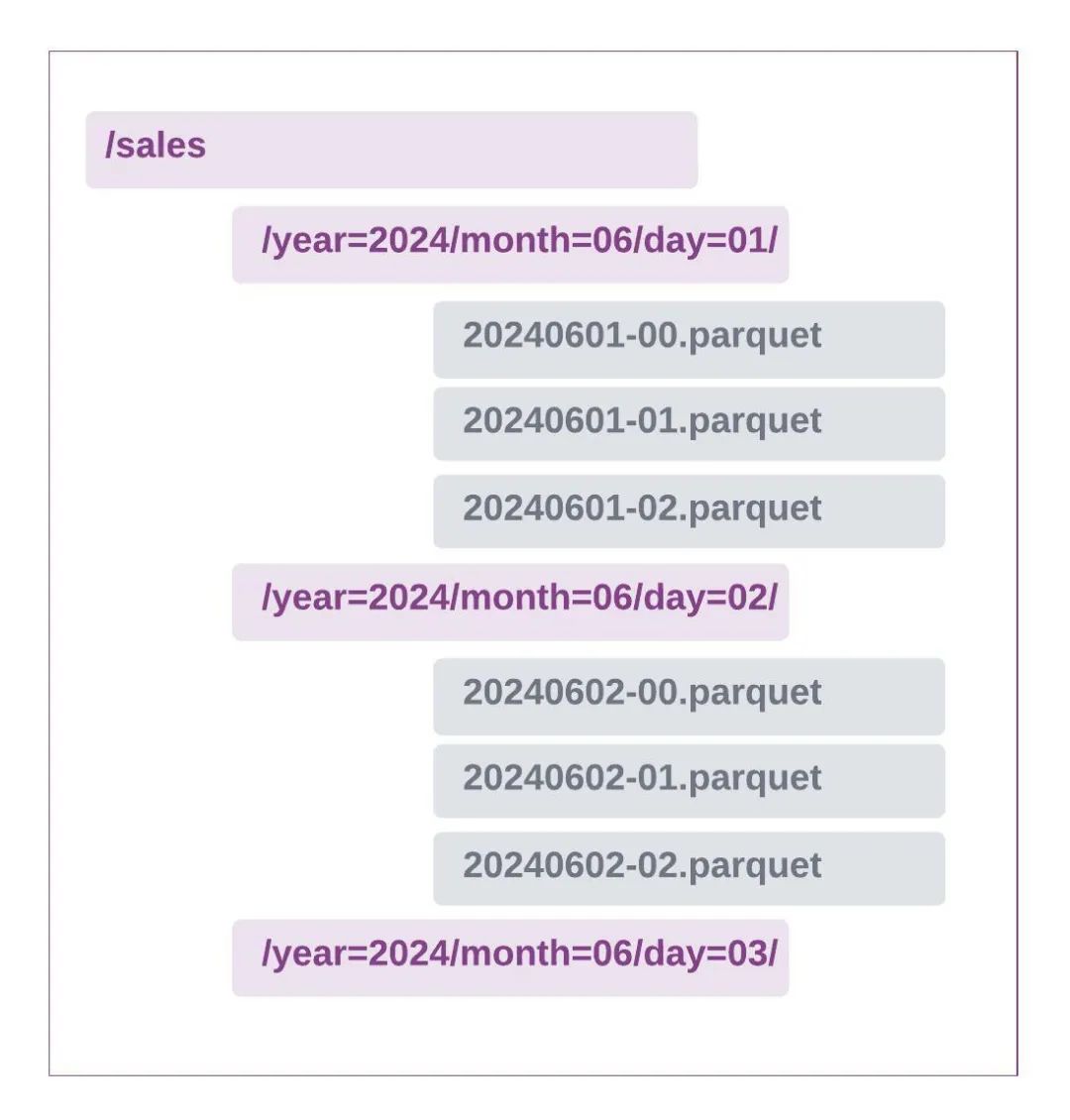
Hive 样式的分区方案
这导致了新数据架构与传统 DBMS 系统之间的另一个主要区别:传统系统将数据和元数据(如表定义)紧密绑定,而新范例将这些组件分开。
这种解耦提供了极大的灵活性。数据可以在没有元数据的情况下摄取到数据湖中,并且多个处理系统可以独立地将自己的元数据或表定义分配给相同的数据。
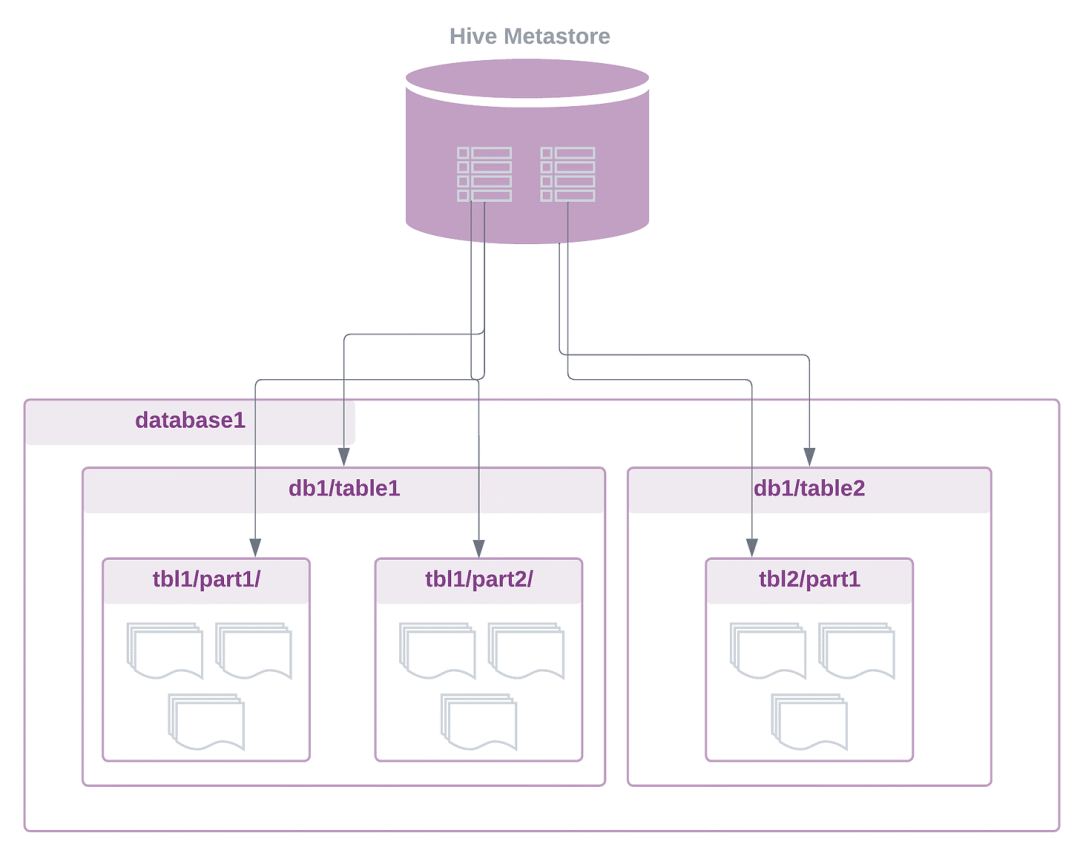
Hive 元数据存储
此外,集中式架构注册表(例如 Hive Metastore,它已成为事实上的标准)允许任何处理引擎使用熟悉的 SQL 或 python 语言以及 Spark、Presto 和 Trino 等其他计算框架,以结构化表格格式与数据进行交互。
通过访问注册表中的表元数据,查询引擎可以确定底层存储层上的文件位置,了解分区方案,并执行自己的读取和写入操作。
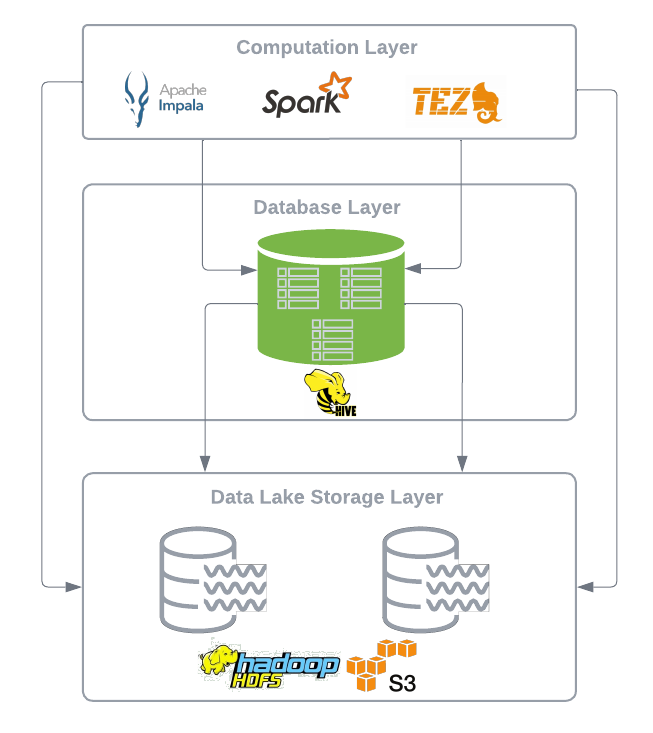
现在明白为什么我们将这种设计称为开放设计,并且可能开始与前几代数据库系统相比,它独具的灵活性和开放架构。
缺点和限制以及面向目录和 Hive 表格式
从 2006 年到 2016 年的近十年时间里,Hive 一直是 Hadoop 平台上最流行的表格格式。Uber、Facebook 和 Netflix 等科技巨头严重依赖 Hive 来管理他们的数据。
然而随着这些公司扩展其数据平台,他们遇到了 Hive 无法充分解决的重大可扩展性和数据管理挑战。
让我们深入研究一下面向目录的表格格式和 Hive 样式表格的缺点,这些缺点促使这家科技公司的工程师寻找替代方案。
首先,让我们看看面向目录的表格格式的挑战和缺点,这是开发 Hive 的基础:
- • 高度依赖底层文件系统 - 此架构严重依赖底层存储系统来提供基本保证,如原子性、并发控制和冲突解决。缺少这些属性的文件系统(例如 Amazon S3 缺少原子重命名)需要自定义解决方法。
- • 文件列表性能 - 目录和文件列表操作可能会成为性能瓶颈,尤其是在执行大规模查询时。像 S3 这样的云对象存储对目录样式的列表操作施加了很大的限制。每个 LIST 请求最多返回 1000 个对象,因此需要多个顺序请求,由于延迟和速率限制,这可能会很慢。这会显著影响处理大型数据集时的性能。
- • 查询规划开销 – 在 HDFS 等分布式文件系统上,由于需要详尽的文件和分区列表,因此查询规划可能非常耗时。这在处理大量文件和分区时尤其明显。
使用 Hive 样式分区的缺点和挑战
- • 分区爆炸 - 紧密耦合的物理和逻辑分区可能会导致过度分区,尤其是对于高基数分区列(如
year/month/day)。这会导致过多的小文件、增加的元数据开销以及由于需要扫描大量分区而导致的查询规划速度变慢。过度分区对 Hive、Spark 和 Presto 等 MPP 引擎尤其有害,因为它们难以进行查询规划和扫描大量小分区。 - • 云效应 - 由于 API 调用限制,云数据湖加剧了过度分区问题。扫描许多分区和文件的作业经常会遇到限制,从而导致性能严重下降。
- • 小文件太多 - 不正确的分区方案可能会创建大量小文件,对不同层[8]产生负面影响,减慢查询和作业规划速度,重新分区需要重写整个数据集,这是一个昂贵且耗时的过程。
- • 性能不佳 - 如果不为跳过数据指定分区键,对 Hive 样式的基于目录的分区的查询可能会很慢,尤其是在具有较深分区层次结构的情况下。意外的全表扫描变得很常见,导致查询执行效率低下且耗时长。
- • 意外的高成本查询 – 意外的全表扫描可能会导致启动大型查询和作业。在管理 Hadoop 平台的这些年里,不得不多次向最终用户解释为什么由于在查询规划阶段扫描大量分区,他们的简单 Hive 查询需要很长时间才能运行。
假设一个 Hive 表按 20 个省份分区,后跟 year=/month=/day=/hour= 分区。这样的表将在 6 年内累积超过 100 万个分区。
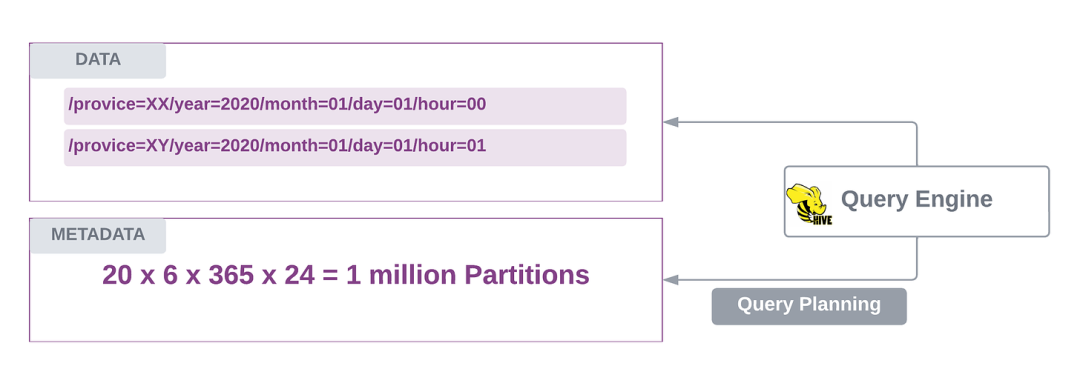
Hive 上的分区爆炸问题
使用 External Metastore 的缺点
除了上述缺点之外,使用外部 Metastore 的 Hive 样式表还带来了更多挑战:
- • 性能瓶颈 – Hive 和 Impala 都依赖于外部元数据存储(通常是 MySQL 或 PostgreSQL 等关系数据库),由于表操作的频繁通信,这可能会成为性能瓶颈。
- • 元数据性能可扩展性 – 随着数据量和分区数量的增长,Metastore 的负担越来越重,导致查询规划缓慢、负载增加和潜在的内存不足错误。社区已广泛记录和解决了这些问题。许多公司(如 Airbnb)在[9]升级平台之前都遇到了 Metastore 性能挑战。
- • 单点故障 - Metastore 表示单点故障。崩溃或不可用可能会导致大范围的查询失败。实施高可用性对于减少停机时间至关重要。
- • 网络延迟 - 查询引擎与外部 Metastore 以及底层关系数据库之间的网络延迟可能会影响整体性能。
- • 低效的统计信息管理 - Hive 依赖于存储在 Metastore 中的分区级列统计信息,随着时间的推移,性能可能会受到影响。具有大量列和分区的宽表会积累大量统计数据,从而减慢查询计划的速度并影响表重命名等 DDL 命令。
生产体验
多年来在生产中使用 Hive 时遇到了上述许多挑战。在最近的一个项目中,我们的开发团队不得不重命名一些具有大约 10k 个分区的大型托管 Hive 表,即使经过许多小时,重命名也会挂起并且无法完成。
经过调查,我发现每个表大约存储了 300k 条统计记录,Hive 正在尝试收集详细信息并更新这些记录。即使在 PostgreSQL 数据库中的 stats 表上重建索引后,问题也没有完全解决。
我相信已经对 Hive 表格式及其底层面向目录的体系结构提出了非常有力的理由。近十年来,Apache Hive 一直为大数据社区提供良好的服务,但现在是时候改进和开发更高效、更可扩展的东西了。
数据湖上的事务保障
在介绍表格式的下一步发展之前,我们还来了解一下在分布式文件系统(如 HDFS)或对象存储(如 S3)支持的数据湖上实施数据库管理系统相关的一些常见挑战。
这些挑战并非特定于 Hive 或任何其他数据管理工具,而是通常与传统 DBMS 系统的 ACID 和事务属性有关。
- • 缺少原子性 - 本机不支持在事务中同时写入多个对象,这会阻碍数据完整性。
- • 并发控制挑战 - 由于缺乏事务协调,对同一目录或分区中的文件进行并发修改可能会导致数据丢失或损坏。
- • 缺乏事务功能 - 基于 HDFS 或对象存储构建的数据湖缺乏内置的事务隔离和并发控制,需要组织放宽一致性要求或实施自定义解决方案。如果没有事务隔离,读取器可能会因并发写入而遇到不完整或损坏的数据。对于读写隔离,下游使用者必须实施自定义机制,以确保数据一致性,方法是在启动其作业之前等待上游批处理工作负载完成。
- • 支持记录级更改 - 底层存储系统的不可变性可防止在数据文件中的记录级别直接更新或删除。
- • 对象存储挑战 - 像 S3 这样的对象存储历来缺乏强大的先写后读一致性,这促使一些组织使用暂存集群(例如 HDFS)作为最终数据放置之前的中间步骤。此外,缺少原子重命名操作给 Spark 和 Hive 等分布式处理引擎带来了挑战,这些引擎在最终确定输出之前依赖临时目录进行数据暂存。
Hive 事务表
Hive ACID 功能是将结构化存储保证,特别是 ACID 事务(原子、一致、隔离、持久)引入不可变数据湖领域的首次尝试。
此功能在 Hive 版本 3 (2016) 中发布,通过提供更强大的一致性保证(如跨分区原子性和隔离),标志着重大飞跃。此外,它还通过 upsert 功能改进了对数据湖上可变数据的管理。
但是将 ACID 添加到 Hive 并没有解决根本问题,因为:
Hive ACID 表仍然植根于面向目录的方法,依靠单独的元数据存储来管理底层 Data Lake Storage 层中的表级信息。
人们曾多次尝试将 Hive ACID 集成到更广泛的数据生态系统中。Hortonworks 开发了 Hive Warehouse Connector,使 Spark 能够读取 Hive 事务表,最初依赖于 Hive LLAP 组件。
Cloudera 后来在 2020 年推出了 Spark Direct Reader 模式,允许在不依赖 Hive LLAP 的情况下直接访问文件系统。
尽管做出了这些努力,但Hive ACID 并没有引起社区的想象力,因为它的底层设计限制未能得到广泛采用。对读取和写入 Hive ACID 表的支持在整个生态系统中仍然不一致,许多著名的工具(如 Presto)提供的支持有限或没有支持。
引用链接
[1] 第 II 部分中: https://open.substack.com/pub/practicaldataengineering/p/the-history-and-evolution-of-open-14d?r=23jwn&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true
[2] 最古老的表格数据: https://www.datafix.com.au/BASHing/2020-08-12.html
[3] E.F. Codd: https://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
[4] 数据库系统的汇编: https://materializedview.io/p/databases-are-falling-apart
[5] AMPLab 联合总监 Michael Franklin 所说: https://medium.com/s-c-a-l-e/database-guru-on-why-nosql-matters-and-sql-still-matters-c64239fe84fd
[6] 围绕生成式 AI 的类似炒作: https://gradientflow.substack.com/p/learning-from-the-past-comparing
[7] 开放数据生态系统: https://practicaldataengineering.substack.com/p/open-source-data-engineering-landscape
[8] 对不同层: https://blog.cloudera.com/small-files-big-foils-addressing-the-associated-metadata-and-application-challenges/
[9] Airbnb)在: https://medium.com/airbnb-engineering/upgrading-data-warehouse-infrastructure-at-airbnb-a4e18f09b6d5
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号