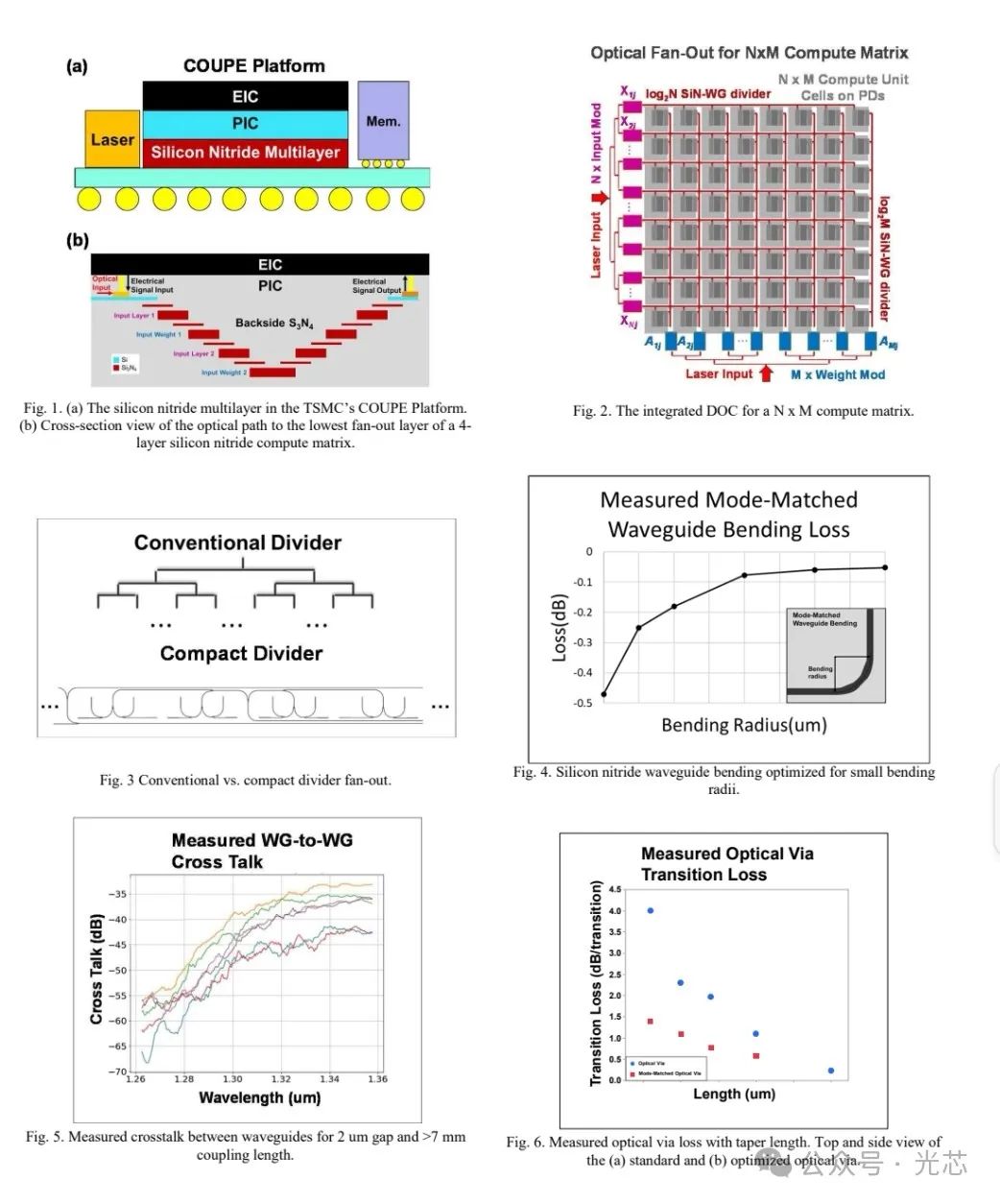
IEDM 2024:台积电的硅光(高性能工艺平台、CPO、光计算) 进展(三)

IEDM 2024:台积电的硅光(高性能工艺平台、CPO、光计算) 进展(三)

光芯
发布于 2025-04-08 20:59:38
发布于 2025-04-08 20:59:38
三、台积电光计算芯片
◆ 用于生成式人工智能的新型并行数字光计算系统
摘要
生成式人工智能(GAI)的普及使得基于光子学的计算成为一种有吸引力的方法,因为它有可能满足对更高能效性能(EEP)的需求。然而,先前用于乘累加(MAC)操作的光学解决方案要么侧重于模拟架构,其受精度和数据转换的限制,要么侧重于可扩展性有限的自由空间光学架构。本文报道了世界上首个用于GAI训练的片上大规模数字光计算系统(DOC)。
DOC采用一种新颖的基于晶圆的系统集成技术,具有多层低损耗光子互连扇出(PIFO)和利用台积电SoIC®的EIC/PIC堆叠架构。它减少了数据移动和存储层级,从而改善了关键路径延迟和系统能效(EE)。与传统的电子设计相比,DOC可以扩展到更大的相干网络,并以更高的速度运行,每次MAC操作的能耗更低。在8位操作下,对于512x512 MAC大规模操作,实现了0.08 pJ/MAC的低能耗,与最先进的GPU相比,EEP提高了20倍。由于相对最小的扇出能量,EEP在更高精度下进一步提高。这种架构在未来几代中具有持续EEP扩展的全部潜力。
随着GAI使用的增加,对更高计算能力和更低能耗的需求持续存在。光学平台,特别是模拟架构,已被提议作为一种有竞争力且高能效的解决方案,包括Reck架构、相干衍射光学和LightMatter的推理Mars光子学核心。尽管在过去十年中对光学模拟架构进行了深入研究,但由于相干问题、器件损耗以及数模和模数转换设计,它仅适用于低精度应用和小规模应用。
为了克服这一限制,麻省理工学院先前提出了一种使用自由空间光学执行高能效复用技术以“无源传输和复制数据”的数字架构。与电子学相比,使用光学的一个显著优势是其能够直接以与路径无关的方式执行低损耗大规模扇出,减少数据移动和延迟。此外,通过减少中间存储层级简化了存储层级,降低了内存访问的总体能耗。这有可能在大规模MAC操作中显著提高能效(EE)。然而,自由空间光学难以扩展,受到衍射、光学元件的物理尺寸和对准要求的限制。这在所有光学自由空间架构中很明显,其中每个光学元件的对准变得至关重要,并且物理尺寸将始终受到衍射极限的限制。
因此,为了实现高效率、高性能和大规模MAC操作的优势,需要高密度集成低损耗光子扇出电路。本工作类似于台积电InFO的电子扇出,设计了一种新颖的多层光子扇出DOC以实现上述优势。DOC的集成流程遵循前边的EPIC流程。 EPIC - DOC首先在PIC上使用台积电SoIC®进行EIC堆叠。然后去除PIC的背面硅。之后,将多层PIFO结构集成到PIC的背面,如图1所示。展示了一个用于512x512计算矩阵的大规模且紧凑的封闭光学扇出电路,光路径损耗为 - 35 dB,允许EEP改进和可扩展性。与最先进的GPU相比,在相同逻辑区域下计算EEP,在8位操作下提高了20倍。此外,展示了计算单元尺寸的可调谐性,允许与各种应用兼容。
◆ 集成数字光计算
对于NxM DOC,N个输入和M个权重电信号首先由光子集成电路(PIC)上的光子调制器转换为光信号,如图2所示。然后输入和权重信号在多层氮化硅中均匀分布,对于512x512计算矩阵,它被分为2层。信号然后通过设计的1 - to - 512扇出电路并传输到PIC上的光电探测器进行电信号转换。电信号然后直接连接到电子集成电路(EIC),在那里MAC操作由位串行乘法器依次进行输出固定累加。
为了实现复用所需的大规模、低损耗、紧凑和路径长度受控的扇出属性,设计了2组封闭的1 - to - 512扇出。由于输入和权重信号的方向性,这2组可以通过“水平”和“垂直”来区分。通过利用多层,封闭的扇出输出允许计算单元尺寸在不牺牲其EE的情况下针对各种应用进行可调谐,这与先前的树状扇出不同。通过半对称扩展扇出来实现路径长度控制。
为了构建计算单元尺寸为25 um x 25 um的512x512计算矩阵,设计了一个紧凑的6 um² 1 - to - 2分配器,损耗为 - 3.25 dB,作为扇出的最基本构建块,如图3所示。为了连接封闭扇出电路中的每个1 - to - 2分配器,设计了半径为15 um到8 um的模式匹配波导弯曲,损耗分别为 - 0.05 dB/弯曲和 - 0.25 dB/弯曲,如图4所示。这是至关重要的,因为在螺旋图案封闭扇出中波导弯曲的使用率很高,是计算单元尺寸的主要限制构建块。
此外,控制波导宽度和间距以防止串扰噪声,如图5所示。最后,设计了一个60 um²的光通孔,每层过渡损耗为 - 0.5 dB,防止各层之间的显著功率差异,如图6所示。通过优化工艺和设计,预计每层过渡损耗可进一步改善- 0.1 dB,尺寸减少3倍。
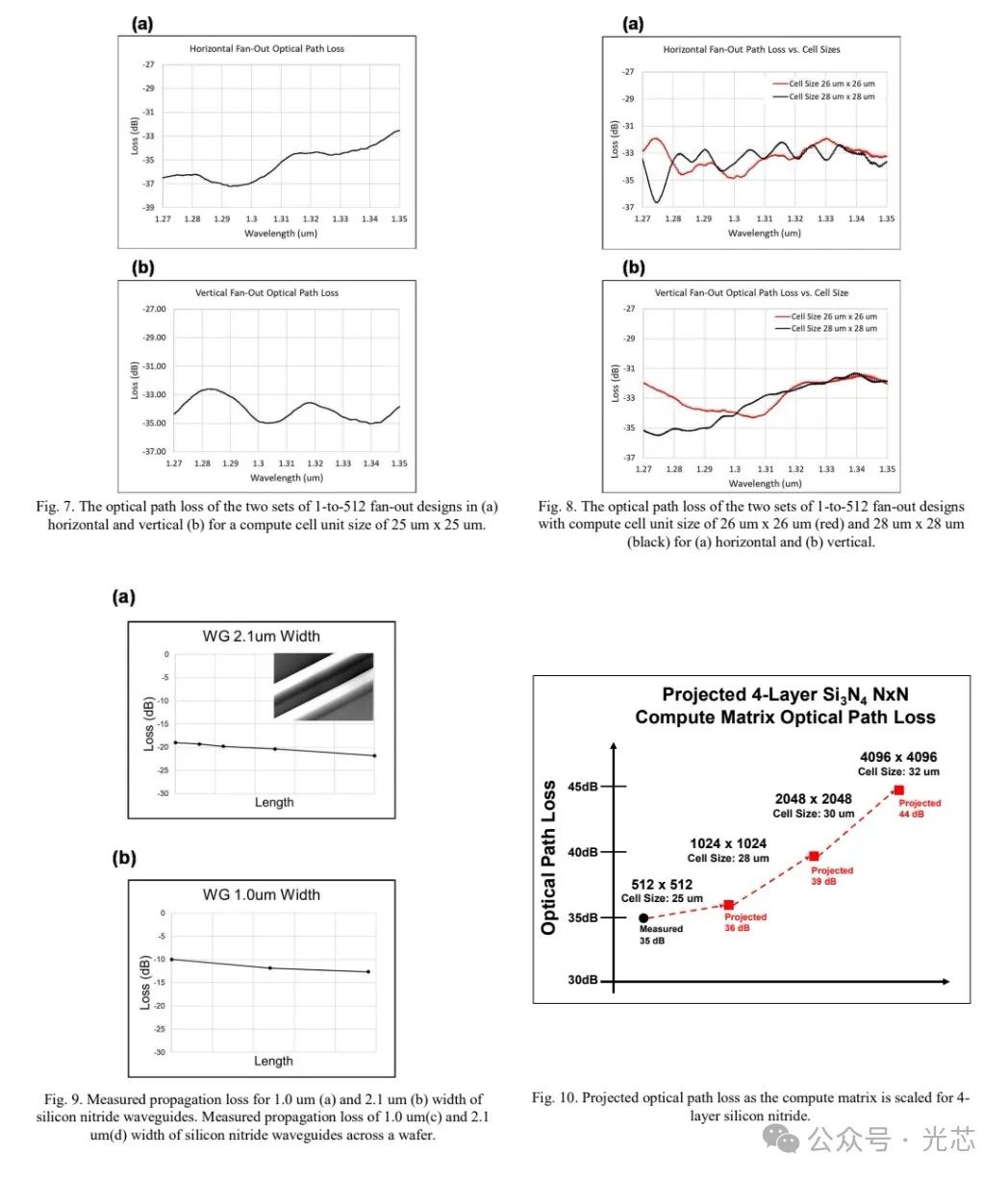
通过控制扇出电路中每个构建块的损耗和面积,制造了大规模的1-to-N/M扇出。1 - to - 512扇出原型的测量总光路径损耗约为 - 35 dB,其中仅测量用的波导交叉损耗为 - 1.6 dB,使用常规弯曲波导和当前工艺的损耗为 - 3.3 dB,如图7和图8所示。这允许实现最小可调谐计算单元尺寸为20 um x 20 um,但光损耗较高。
◆ 背面氮化硅耦合
与正面相比,EIC/PIC堆叠的背面为扩展设计的高效扇出网络提供了一个平台。多层氮化硅允许减少扇出的占地面积和损耗。氮化硅波导在1 um和2.1 um宽度下的低传播损耗分别为 - 0.1 dB/cm和 - 0.02 dB/cm,如图9所示。这是至关重要的,因为传播损耗与计算矩阵和单元尺寸的大小成正比。PIC/EIC受益于扇出位于背面,简化了整体设计复杂性。这允许在每层上实现专门功能,从扩展中扩大潜在的EEP改进。此外,通过利用COUPE平台在最小化PIC - EIC接口之间寄生损耗方面的优势,增强了EEP。
◆ 能效性能计算
在这种DOC架构中,总EE将随着精度的提高而显著改善。在低精度MAC操作中,扇出能量占功耗的很大一部分。在更高精度下,与MAC操作中大幅增加的功耗相比,扇出能量将保持相对最小。因此,基于测量的损耗和从优化工艺估计的改进,可以预测光路径损耗,如图10所示。
假设激光wall-plug效率为20%, - 2 dB调制器插入损耗,以及光纤到PIC连接损耗为 - 1 dB。从这种损耗性能可以实现预计的4096x4096 MAC操作。当前工艺的DOC在8位时的计算EE约为0.15 pJ/MAC,与最先进的GPU相比,EEP提高了10倍。通过优化工艺,估计在8位时EE 为 0.08 pJ/MAC,EEP提高20倍。这是通过使用优化工艺后的光路径损耗,并假设调制器每比特能耗为0.2 pJ,每次SRAM访问每比特能耗为0.1 pJ,光电探测器响应度约为1 A/W,EIC每MAC能耗0.025 pJ计算得出的。由于不断发展的系统集成和EIC/PIC,预计所提出的DOC在未来扩展到超过4096x4096 MAC操作时,EEP将有更显著的提高。
(个人观点:台积电的这个工作能搞定的最大来源还是他强大的制造能力,4层的低损氮化硅的平台可不是一般fab能做的,未来也许光波导平台也会像PCB板一样演进成多层结构的平台。感觉台积电搞定了这么大规模的矩阵以后,其实它也可以随手把片上的OCS给做了)
另外两篇论文分享请移步公众号继续阅读
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号