OFC 2025前瞻:Lightmatter的硅光互连+光交换实现机柜级通信速度/训练吞吐量提升

OFC 2025前瞻:Lightmatter的硅光互连+光交换实现机柜级通信速度/训练吞吐量提升

光芯
发布于 2025-04-08 21:28:11
发布于 2025-04-08 21:28:11
(论文链接: https://arxiv.org/abs/2501.18169)
Cornell大学和Lightmatter合作发表的一个论文,说已经在OFC 2025上被接收了。是之前这个工作的延续(链接:Cornell大学& Lightmatter:服务器规模的光互连/光交换研究),基本信息差不多,还是用的Lightpath芯片,给这套架构起了个名字叫做
光域可重构数据中心机架架构LUMORPH。
◆ 基本架构 回顾一下芯片,LIGHTPATH晶圆包含至多32个模块,每个模块有多组发射和接收(TRX),都是基于微环谐振腔的调制/解调。每组发射是8或者16个波长的调制,接收看示意图是双微环的Demux。片上OCS的基础单元是级联的MZI实现的1*3光开关,通过编程MZI的开关行为,可在服务器内加速器间构建电路,实现不同加速器间的连接。服务器内模块之间是直接跨reticle的波导连接,不同服务器之间的模组之间是光纤连接。
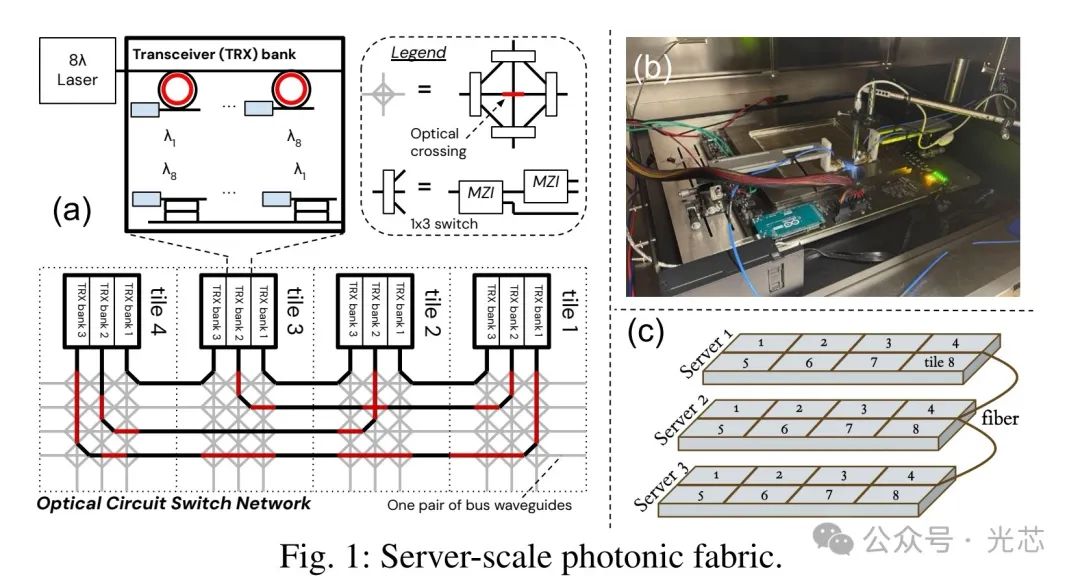
研究团队在GlobalFoundries制造了测试平台(图1(b))进行传输回环实验。结果显示,在10Gbps、15Gbps和20Gbps数据速率下,误码率极低,分别为6.96e-13、6.62e-13和5.60e-14 。MZI光开关重新配置仅需3.7us,这使得芯片间能按需建立光电路。 ◆LUMORPH架构的优势 1. 避免多租户计算碎片化 LUMORPH借助LIGHTPATH模块间密集的波导和灵活的MZI配置,实现服务器内芯片无拥塞访问。同时,通过服务器间的光纤连接,可拓展至其他服务器的空闲芯片。与传统固定大小计算切片分配架构不同(如基于3D Torus的TPU、基于BCube的SiPAC),LUMORPH能为用户提供任意大小的电路交换分配(图2)。
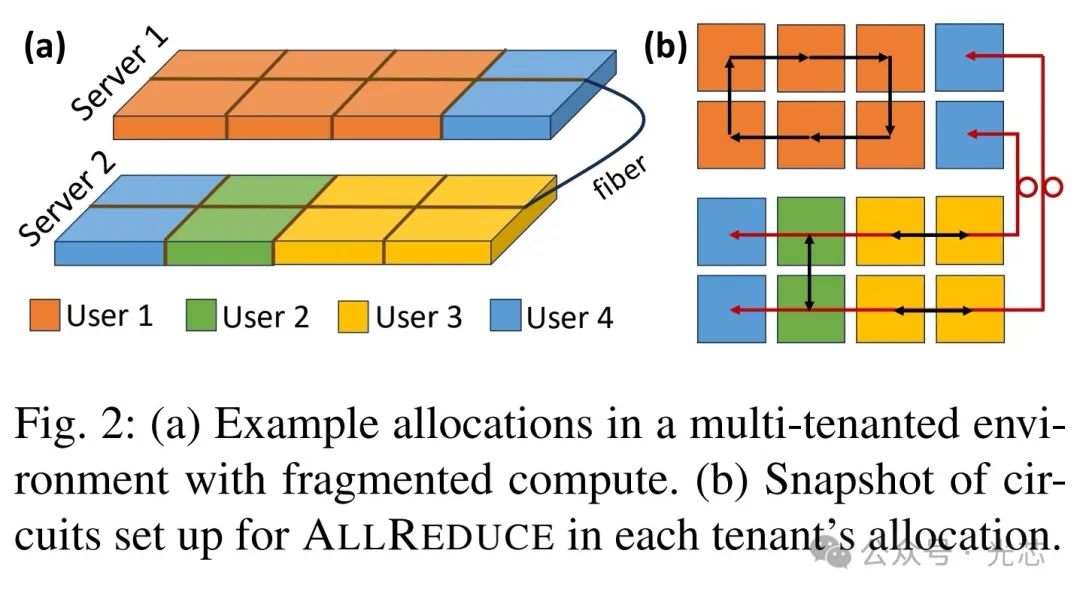
在图2(a)中可以看到,对于用户4申请的四个芯片资源,LUMORPH可灵活分配,而传统架构却无法利用这些空闲计算资源。此外,LUMORPH能适配多种ALLREDUCE算法,不同租户可根据自身芯片分配情况选择最优算法,如用户1的六个芯片分配可采用Ring ALLREDUCE算法,数量为2的幂次方的分配则使用递归加倍/减半算法(图2(b))。
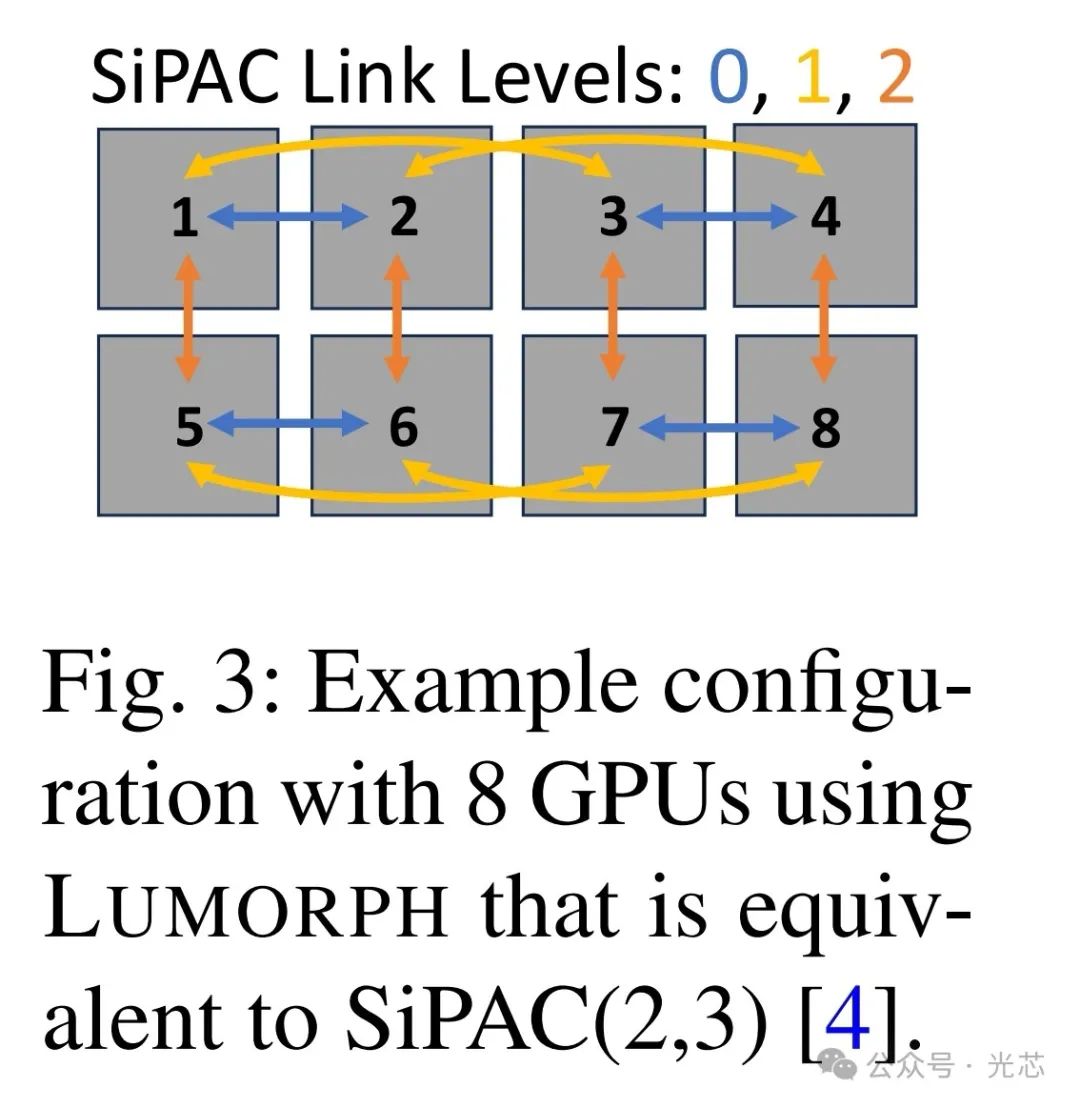
2. 优化集合通信性能 研究采用α-β成本模型衡量集合通信时间,其中α代表发送一个数据块的固定成本,β代表数据传输延迟。为最小化LUMORPH上集合通信的α-β成本,研究团队对递归加倍/减半等成熟算法进行适配。 LUMORPH的光子互连使GPU能在一轮通信中与多个GPU交互,团队进一步将递归加倍/减半拓展为四倍/四分之一算法。在模拟评估中(图4),对比最严苛的基线(无排队延迟的理想电气互连)以及NCCL实现的基于理想交换机的环算法和树算法,LUMORPH - 2和LUMORPH - 4算法表现卓越。在256个GPU互连场景下,尽管存在MZI重新配置的延迟,LUMORPH的集合通信完成时间比环算法和树算法快近80%,
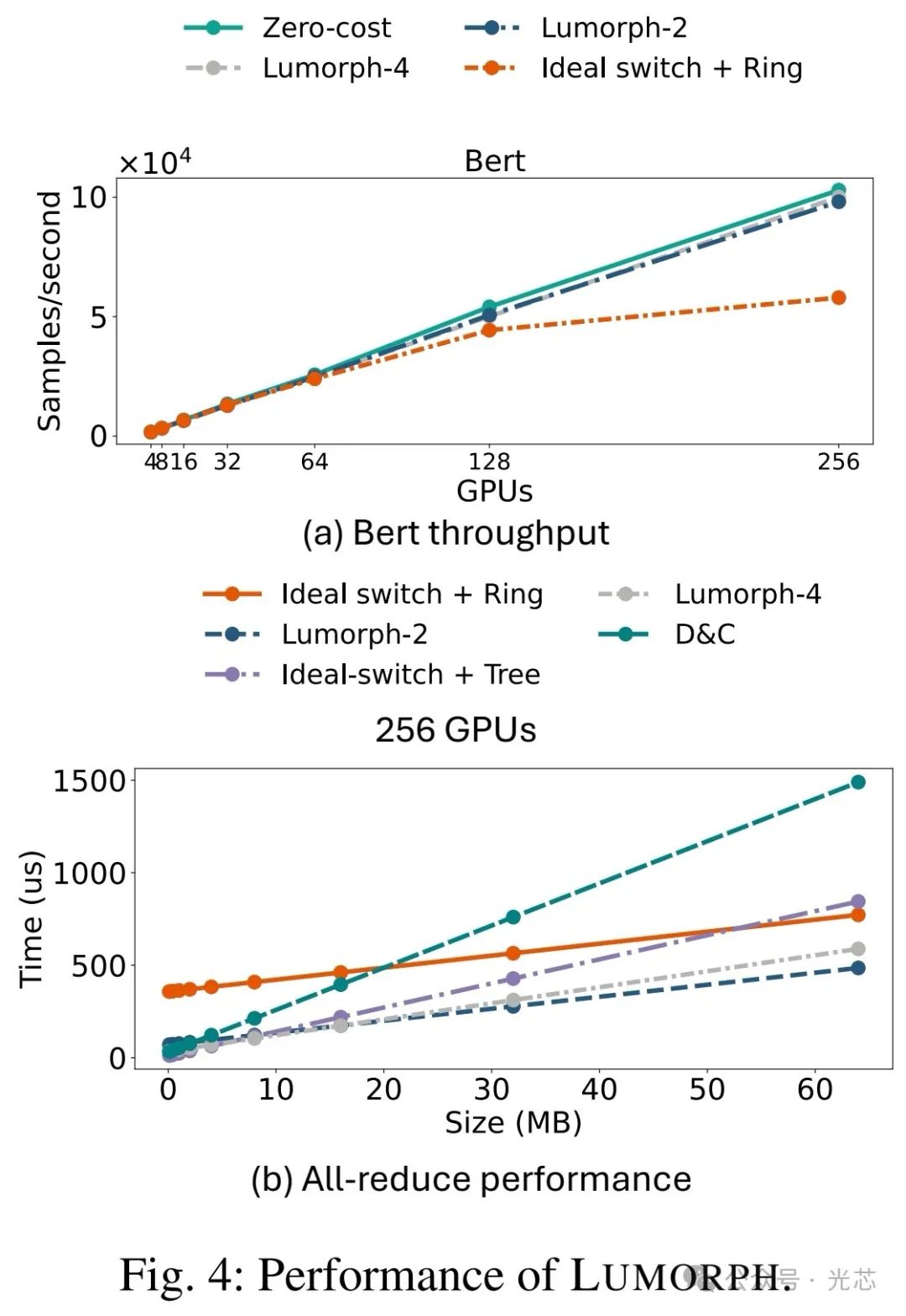
在端到端的机器学习训练评估中,研究使用FlexFlow模拟器为BERT语言模型生成最优计算图。结果显示,LUMORPH的训练吞吐量比环算法高出1.7倍(见图4(a))。这是因为BERT模型的并行化策略包含大量小缓冲区大小的ALLREDUCE调用,在高带宽(300GB/s)下,小缓冲区ALLREDUCE运行时间主要由α成本主导,而LUMORPH算法在α成本优化上表现更优(见图4(b))。 ◆ 研究总结与展望 这项研究成果充分展示了在多加速器服务器中集成芯片间光子互联技术的显著优势。LUMORPH架构不仅解决了多租户资源碎片化问题,还大幅提升了机架级集合通信速度和机器学习训练吞吐量。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-02-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号