摩尔定律未死:GPU架构师如何续写千倍性能神话

摩尔定律未死:GPU架构师如何续写千倍性能神话

GPUS Lady
发布于 2025-05-15 13:20:00
发布于 2025-05-15 13:20:00

本文整理自NVIDIA 2025GTC讲座《GPU MODE at NVIDIA GTC 2025》:
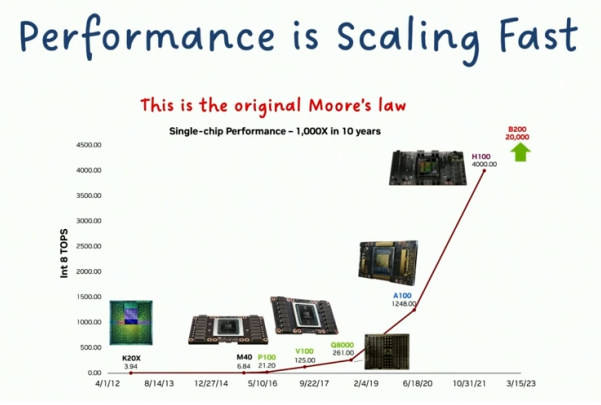
在计算机体系结构领域耕耘三十载,我深信此刻正经历着最富戏剧性的技术变革:既是最好的时代,也是最具挑战的时代。一方面,硬件创新正以惊人速度迭代,新理念向产品转化的效率达到历史峰值;但另一方面,行业正面临前所未有的结构性难题。让我们通过数据管中窥豹:这张来自比尔·戴尔的图表展示了GPU单核性能十年间的演进轨迹——实现了千倍级提升,完美延续了摩尔定律每年翻倍的黄金定律。即将发布的Blackwell架构更被预测将刷新纪录,本周大家将频繁听到相关讨论。
若不愿面对接下来的挑战分析,此刻正是举杯畅饮的良机。但若选择继续,接下来的五到六页内容可能会带来些许压力。为何我要强调这种矛盾?让我们逐步拆解……
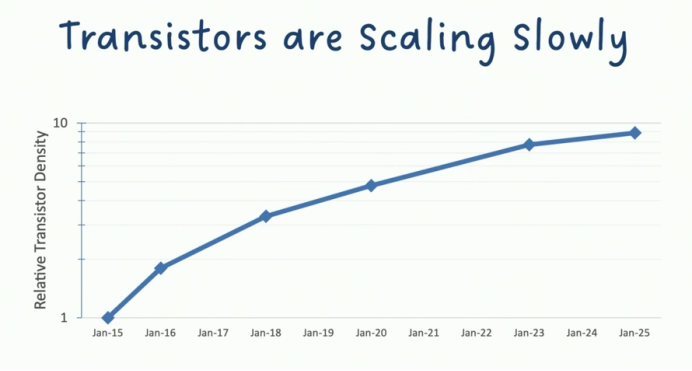
任何性能提升都源于晶体管密度的改进——这才是摩爾定律的本质,而非表面数字游戏。这张基于公开数据绘制的图表,清晰展现了台积电(TSMC)过去十年间工艺节点的缩放轨迹:尽管缩放速度仍呈指数级下降趋势,我们尚未触及物理极限,但现实却不容乐观——当前每年仅能实现10%-20%的工艺进步,即便在最乐观的估算下,这个数字也仅能接近20%。这与摩尔定律预期的每年翻倍(2x性能增长)存在指数级差距,工艺缩放效率已远低于行业需求。
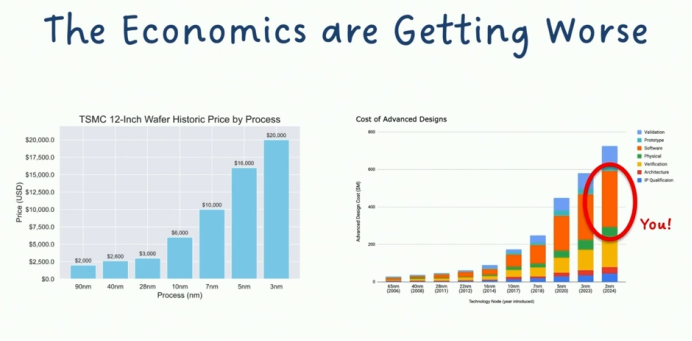
需明确的核心逻辑:摩尔定律本质是经济规律而非单纯技术法则。其核心承诺在于——以恒定成本获取翻倍性能(晶体管数量与计算效能同步提升)。但当前产业正面临双重经济挤压:
左侧曲线揭示晶体管经济性逆转:为获得10%-30%的密度提升,单位晶体管成本呈指数级攀升。现代制程节点每前进一步,晶圆成本增幅远超密度收益。
右侧曲线暴露隐性成本爆炸:非重复性工程费用(NRE)十年间增长轨迹中,橙色软件开销板块持续扩张。这包含为异构芯片适配所需的编译器优化、内核重构、库函数开发等系统性工程投入。
这种经济模型变革将重塑行业格局:
-部署门槛提升:芯片仅适用于高毛利领域(如HPC、AI加速器),低利润市场难以承受成本曲线
-规模效应依赖:必须通过百万级出货量分摊NRE,导致资源向头部应用集中
对AI领域的影响存在特殊性:当前AI计算恰好同时满足高利润率与大规模部署条件,使该领域可暂时规避经济规律制约。但需警惕的是,这种特殊性可能掩盖底层技术经济性的根本转变,长期需关注架构创新与软件工具链的协同优化。
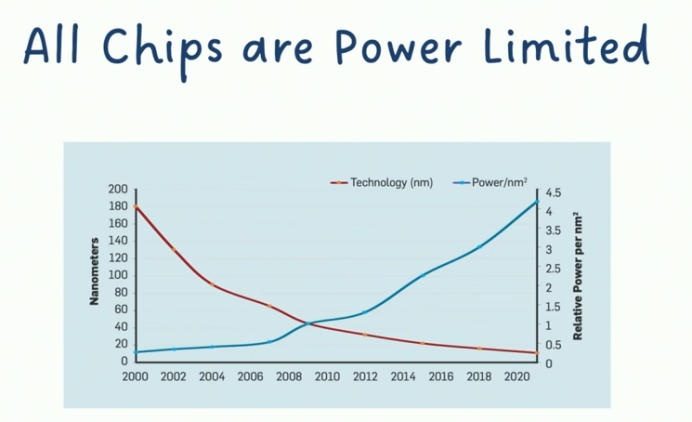
回归技术本质,当前架构师面临的核心挑战是功率墙(Power Wall)问题。这张图表揭示了关键矛盾:虽然晶体管密度持续攀升,但由于供电电压无法按比例缩减,单个晶体管的动态功耗维持恒定。这导致单位面积功耗密度呈指数级增长——当我们在相同面积内集成更多晶体管时,局部热密度会突破散热极限。
这种物理限制引发两大连锁反应:
-晶体管使用限制:要么严格控制芯片总面积(减少晶体管总量),要么通过动态电压频率调整(DVFS)限制同时激活的晶体管数量
-暗硅现象涌现:为避免热失控,系统不得不周期性关闭大部分逻辑单元,导致芯片实际可用计算资源远低于标称值
这种矛盾正从根本上重塑芯片架构设计范式。传统通过提升集成度换取性能的路径已不可持续,迫使行业转向三维集成、近阈值计算、芯片异构化等创新方向。值得注意的是,这种转变并非单纯的技术迭代,而是需要架构、电路、封装乃至软件层面的协同突破。我们将在后续讨论中深入剖析这些应对策略。
除功耗限制外,当前芯片设计还面临三大核心挑战:
-内存缩放停滞:
- SRAM/DRAM单元面积缩放已趋近物理极限,现代工艺节点仅能实现个位数百分比级的密度提升
- 传统依靠存储器缩放提升系统性能的路径基本失效,这直接冲击着计算密集型应用的性能天花板
-互连技术困境:
- 片上互连面临三难选择:低能耗、低延迟、高布线密度三者不可兼得
- 先进工艺下,金属层间距缩小导致串扰加剧,迫使设计者在长距离互联与局部密集互连间做出权衡
- 催生多层级互连架构:需要同时部署高速片上网络(NoC)、低功耗总线及专用加速通道
-设计复杂度爆炸:
- 为突破物理限制,现代芯片普遍采用多域电源管理、异构计算岛、3D堆叠等复杂技术
- 要求架构师在性能、功耗、面积(PPA)之外,额外考虑热分布、工艺偏差、良率优化等多维约束
这些挑战正在重塑芯片设计方法论,推动行业向系统级优化转型。我们将在后续章节深入探讨架构层面的创新解决方案,包括近内存计算、光互连技术及领域专用架构等突破性方向。

面对"性能提升千倍悖论"——在晶体管缩放趋缓、功耗墙凸显、内存缩放停滞的多重限制下,硬件架构师通过以下系统性创新实现性能突破:
第一性原理重构 在恒定功耗约束下,性能(P)= 能效(E)× 吞吐量(T)的公式被拆解为两个优化维度:
1.能效革命:通过微架构创新降低单次操作能耗
- 近阈值电压计算:在亚阈值区域运行晶体管,将能耗降低10倍以上
- 事件驱动执行:通过硬件预取、分支预测优化减少无效操作
- 电压频率岛:对不同功能模块实施动态电压缩放
2.吞吐量优化:在功率预算内最大化有效操作数
- 指令级并行:乱序执行、超标量架构的持续优化
- 数据级并行:SIMD/SIMT指令集扩展(如CUDA核心)
- 线程级并行:多核/众核架构与硬件线程调度
架构演进路线图 过过去十年间形成三条技术主线:
- 垂直优化:从晶体管级到芯片级的全栈创新(如GAAFET晶体管、3D堆叠)
- 水平扩展:通过异构计算分解任务(CPU+GPU+DSA协同)
- 范式突破:突破传统冯·诺依曼架构(存算一体、近内存计算)
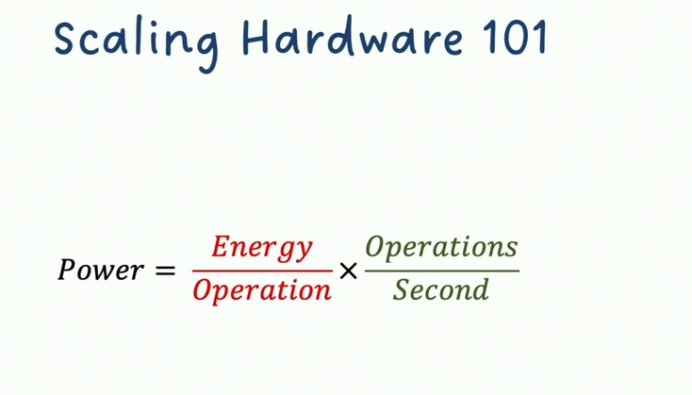
架构优化三重奏:能效革命的战术拆解
通过解构这张谷歌文档借来的能效对比表,我们可提炼出架构师十年间的三大核心战术:
战术一:数值精度瘦身术
现象洞察:表顶数据显示,窄位宽运算能耗呈指数级下降(64位浮点→4位浮点能耗降低16倍)
实施路径:
- 硬件层:定制化低精度运算单元(如Tensor Core)
- 软件层:编译器自动混精调度、量化感知训练
- 生态层:推动IEEE 754标准新增低精度格式
成效:AI训练场景能耗降低3-5倍,推理场景突破10倍
战术二:指令集维度跃迁
问题诊断:传统标量指令解码能耗占比超30%(表中Instruction Fetch/Decode行)
破局方案:
- 向量化扩展:将单条指令控制单元从标量升级为128/256位向量
- 张量核革命:NVIDIA Tensor Core实现4x4矩阵运算单指令化
- 空间局部性优化:通过寄存器重命名隐藏流水线气泡
收益:典型深度学习算子能效提升20倍,解码开销分摊至0.1%以下
战术三:内存墙突围战
关键发现:片外DRAM访问能耗是L1缓存的200倍(表中Memory Hierarchy列)
三级防御体系:
- 空间局部性:通过Cache预取、数据重用优化减少访存次数
- 时间局部性:采用计算缓存(Compute Cache)融合存储与运算
- 近存计算:HBM堆叠技术将DRAM颗粒直接封装在逻辑芯片上方
案例:TPU v4通过3D封装实现95%数据本地化,DRAM带宽利用率突破90%
架构演进范式转移 这波优化浪潮推动计算机系统设计进入三维优化时代:
- 纵向维度:从晶体管级到封装级的全栈协同设计
- 横向维度:硬件-编译器-算法的联合优化
- 时间维度:动态电压频率调整(DVFS)进化为运行时自适应优化
正是这些看似简单的表格数据,催生了现代AI加速器的核心架构范式。当我们审视NVIDIA Ampere架构的第三代Tensor Core,或AMD CDNA 3的矩阵引擎时,看到的正是这三个战术维度的深度融合与创新延伸。这种演进路径,正是摩尔定律放缓时代架构师交出的最优解。

GPU性能千倍跃迁的解构分析
以NVIDIA GPU十年演进为样本,其性能突破可拆解为六大技术杠杆的协同作用:
1. 计算范式重构(贡献约10倍)
定制化加速单元:引入Tensor Core矩阵乘法引擎,将传统标量运算升级为4x4矩阵块操作
向量化升级:从单精度浮点向量扩展至半精度矩阵运算单元(如FP16矩阵乘加)
稀疏化突破:通过细粒度结构化稀疏技术,实现非零元素的有效吞吐量翻倍
2. 数值精度革命(贡献10-30倍)
动态精度调整:建立从FP32训练到INT4推理的完整精度可伸缩链路
混合精度系统:开发TF32等中间精度格式平衡数值稳定性与能效
量化感知训练(QAT):通过伪量化节点实现训练与推理的精度无缝衔接
3. 微架构优化(贡献约3倍)
时钟频率提升:从GHz级向1.5GHz+突破,通过动态频率调整(DVS)平衡能效
流水线优化:采用双发射乱序执行引擎,减少指令级并行(ILP)开销
缓存层次重构:引入L1.5缓存层级,将纹理缓存带宽提升3倍
4. 规模扩展效应(贡献约2倍)
芯片面积扩张:从400mm²向1000mm²演进,实现计算单元数量翻倍
功耗预算增长:从250W TDP向700W+演进,通过多相电源管理维持能效比
3D封装突破:采用CoWoS封装实现HBM2e内存直连,带宽突破2TB/s
5. 存储系统革新(隐性贡献)
内存压缩:通过稀疏矩阵压缩格式减少30%数据搬运量
预取优化:开发流式处理器架构,将内存访问延迟隐藏率提升至85%
缓存一致性:引入GPU直连(GPUDirect)技术,减少PCIe传输开销
6. 软硬件协同设计(关键使能)
编译器创新:开发LLVM-based NVPTX编译器,实现自动向量化与混精调度
算法适配:推动Transformer架构优化,使矩阵运算密度提升5倍
框架整合:通过CUDA Graphs将内核启动开销降低10倍
这种多维优化形成"乘数效应":当矩阵运算单元与低精度计算结合时,实际能效提升可达单个技术贡献的乘积(如10×10=100倍)。而所有硬件创新必须通过软件栈释放潜力,例如稀疏化技术需要配套的压缩算法与权重重排策略。这种软硬件深度协同,正是现代GPU性能突破摩尔定律限制的核心密码。
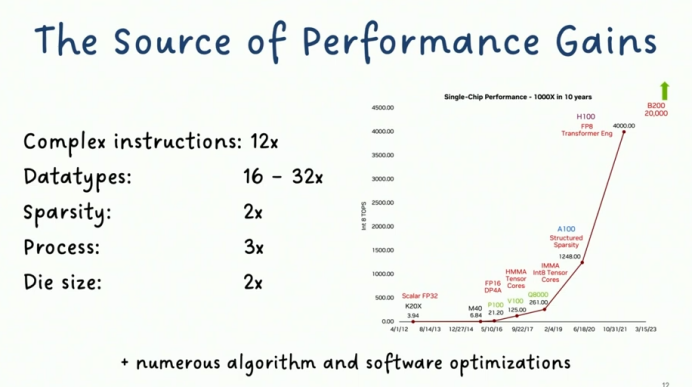
内存系统革命:从平面扩展到三维集成
针对内存墙挑战,硬件架构师通过空间维度创新实现系统性突破,其技术演进可分解为三个核心层面:
1. 近存计算架构(Compute-in-Memory)
物理层融合:通过硅中介层(Interposer)实现计算单元与内存的晶圆级键合,将片外访问转化为片内通信
带宽革命:HBM(高带宽内存)技术通过TSV(硅通孔)实现DRAM芯片垂直堆叠,单引脚带宽突破6GB/s
能效提升:3D封装使数据搬运能耗降低80%,打破传统冯·诺依曼架构的存储瓶颈
2. 3D堆叠技术演进
容量扩展:在无法突破DRAM单元缩放极限的情况下,通过混合键合(Hybrid Bonding)实现8-12层芯片垂直堆叠
散热优化:采用微凸点(Microbump)间距缩小技术(从50μm降至9μm),提升散热效率3倍
成本平衡:台积电SoIC技术实现已知合格芯片(KGD)的异质集成,良率提升至95%以上
3. 系统级优化策略
层次化缓存:构建L1.5缓存层级,通过SRAM-DRAM混合存储结构减少50%的DRAM访问
预取增强:开发空间局部性预测算法,将缓存命中率从65%提升至88%
压缩技术:采用行压缩(Row Compression)和列重映射(Column Remapping),使有效带宽提升2.5倍
未来技术路线图 台积电CoWoS-L技术路线显示,3D堆叠密度将持续以每年40%的速度增长:
2025年:实现12层HBM3e堆叠,带宽达1.5TB/s
2027年:引入光学中介层(Optical Interposer),突破电学互连的带宽密度极限
2030年:探索单芯片集成1TB内存容量,满足百亿亿次计算需求
这种三维集成革命不仅重塑了内存系统设计范式,更催生了"存储-计算-互连"的全新协同优化模式。当HBM4与光子互连技术融合时,我们将见证内存系统从单纯的数据仓库,演变为具备实时计算能力的智能存储层次。
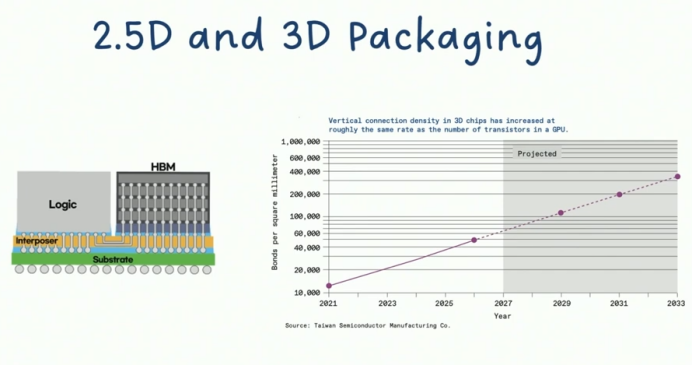
未来十年性能跃迁路径:千倍挑战与破局之道
面对"后摩尔时代"的性能需求,计算机架构师正通过六大技术维度构建新一代性能引擎:
1. 三维集成深化(3D Stacking 2.0)
技术演进方向: • 逻辑芯片垂直堆叠:突破当前仅存储层堆叠的限制,实现CPU/GPU逻辑层的3D集成 • 混合键合密度提升:从当前9μm间距向3μm演进,实现400%互联密度提升 • 散热解决方案:开发液态金属导热界面,解决多层堆叠热密度问题
2.光学互连革命(Silicon Photonics)
关键技术突破: • 共封装光学器件(Co-packaged Optics):在封装层级集成光引擎,实现芯片间1.6Tbps光互连 • 波分复用(WDM)集成:单光纤承载32通道波长,突破电学I/O带宽密度极限 • 光子计算融合:探索光学神经网络加速器的光子矩阵乘法单元
3. 指令集架构进化(ISA 3.0)
演进路径: • 粗粒度指令扩展:从矩阵运算向张量运算升级,支持稀疏矩阵直接编码 • 指令融合优化:开发复合指令(如Fused GEMM+Activation),减少指令发射开销至5%以下 • 动态指令生成:通过eBPF技术实现运行时指令集重构,提升指令缓存命中率
4. 数值表示突破(Beyond 4-bit)
前沿探索方向: • 混合精度架构:构建FP8/INT4/Binary动态可重构运算单元 • 随机计算(Stochastic Computing):用概率表示实现超低精度计算(1-bit等效) • 模拟计算融合:开发基于忆阻器的模拟-数字混合精度运算阵列
5. 稀疏计算革命(Sparsity 2.0)
双轨突破策略: • 结构化稀疏:推进2:4稀疏等标准化格式,实现硬件解码加速 • 非结构化稀疏:开发动态稀疏模式检测引擎,配合软件层面的自动稀疏化编译 • 内存系统优化:通过稀疏感知缓存(Sparsity-Aware Cache)减少50%无效数据搬运
6. 数据流架构重构(Data-Centric Computing)
核心优化方向: • 计算缓存(Compute Cache):在L3缓存层集成简易ALU,实现数据预处理 • 近存计算(Near-Memory Computing):开发HBM内存堆叠的简单运算单元 • 流水线优化:构建数据局部性预测模型,将缓存缺失率降至10%以下
技术演进路线图 根据台积电技术路线图,未来十年将呈现三大技术浪潮:
2025年:3D SoC商用化,实现异构芯片的垂直集成
2028年:光学I/O全面普及,片间通信能耗降低90%
2030年:存算一体架构成熟,计算效率突破100TOPS/W
破局关键:协同创新 实现持续性能跃迁的关键在于构建"硬件-软件-算法"的协同创新飞轮:
硬件创新:开发可重构架构(Reconfigurable Architecture)
软件支持:建立稀疏计算中间件(SparseML)
算法适配:推动自适应精度训练(Adaptive Precision Training)
这种多维创新体系将重塑计算机系统设计范式,使性能提升从传统的工艺驱动转向架构创新驱动。当3D堆叠与光学互连深度融合,配合稀疏计算与数据流优化,我们有望在2030年实现每瓦特性能的再次千倍跃迁,开启智能计算的新纪元。

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-05-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号