深入理解 Doris Compaction:提升查询性能的幕后功臣

深入理解 Doris Compaction:提升查询性能的幕后功臣

数据极客圈
发布于 2025-07-31 15:53:35
发布于 2025-07-31 15:53:35

在 Doris 的数据存储与查询体系里,Compaction 是保障查询效率、优化存储的关键机制。如果你好奇 Doris 如何在高频写入后仍能高效响应查询,或是想解决数据版本膨胀带来的性能问题,这篇关于 Compaction 的深度解析值得收藏 👇
一、为什么需要 Compaction?
Doris 采用类 LSM - Tree 的存储结构,每次数据导入会生成新的 Rowset(可理解为数据版本片段 ),每个rowset由0到n个sgement组成。segment实际对应这个磁盘上的一个文件。单个sgement文件是有序的。
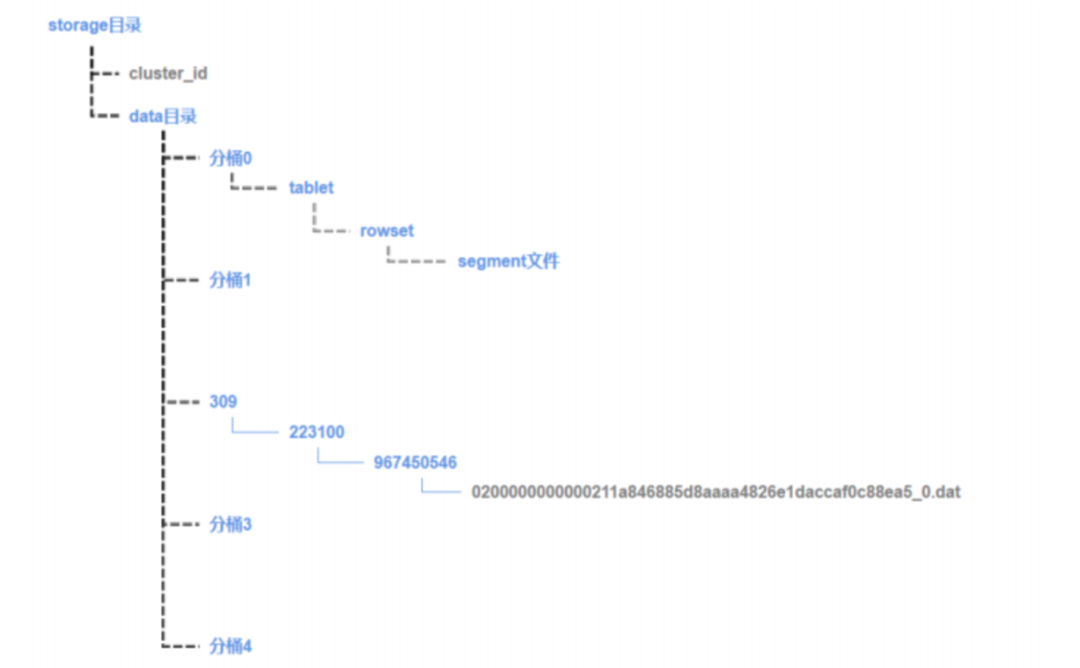
存储文件目录结构
存储文件目录结构
随着导入操作增多,Rowset 数量不断累积,会引发两大核心问题:
(一)查询效率下降
查询时,Doris 需要对多个 Rowset 执行 “多路归并” 操作来整合结果。Rowset 数量越多,归并的路数就越多,查询耗时呈几何级增长。例如,若一个查询需要合并 10 个 Rowset,归并过程就像同时梳理 10 条杂乱的线,难度和耗时远大于合并 2 - 3 个 Rowset。
(二)存储成本上升
大量零散的 Rowset 会占用更多磁盘空间,还可能存储重叠和无效数据。比如多次导入同一范围的数据,会生成多个有重叠的 Rowset,不仅浪费存储,还会让查询时的归并逻辑更复杂。
Compaction 的核心目标
- 减少查询归并成本:将多个小 Rowset 合并为大 Rowset,降低查询时的合并路数。
- 消除无效数据:将标记删除(Delete)、更新(Update)的数据真正清理,避免查询时的无效扫描。
- 优化存储:在 Aggregate 模型中预聚合相同 Key 的数据,在 Unique 模型中保留最新版本,进一步提升查询效率。
compaction的粒度是tablet,下图是一个tablet compaction过程的示意图
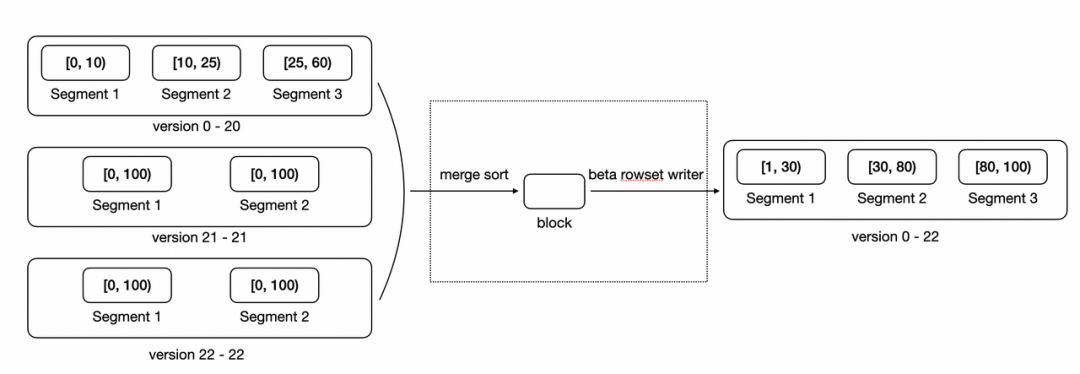
tablet 的 compaction过程
tablet 的 compaction过程
二、Compaction 关键概念解析
1. Compaction Score:优先级调度指标
Compaction Score 是 Doris 判断 Tablet 做Compaction优先级的核心指标,值越高,优先级越高。
(一)本质
反映查询时 Rowset 参与 “多路归并” 的路数。路数越多,查询效率越低,越需要优先compaction。
(二)计算逻辑
遍历 Tablet 的 Rowset,根据其数据重叠情况统计归并路数:
若某 Tablet 的 Rowset 分布如下:
"rowsets": [
"[0-100] 3 DATA NONOVERLAPPING ...", // 无重叠,归并占 1 路
"[101-101] 2 DATA OVERLAPPING ...", // 有重叠,归并占 2 路
"[102-102] 1 DATA NONOVERLAPPING ..." // 无重叠,归并占 1 路
]
- 无重叠 Rowset:如
[0-100]范围的 Rowset 由 3 个Segment 组成,但是没有但是没有overlap,查询归并时仅占 1 路; - 有重叠 Rowset:如
[101-101]范围的 Rowset 由 2 个Segment 组成,但是有但是有overlap,查询归并时占 2 路。
则 Compaction Score = 1(第一行) + 2(第二行) + 1(第三行) = 4。
2. Base & Cumulative Compaction:分层合并策略
为了平衡 “压缩效率” 和 “数据合并成本”,Doris 采用分层压缩思路:
(1)Cumulative Compaction
- 作用:优先合并新写入的小 Rowset,避免直接与大 Rowset 合并导致效率低下。新导入的零散数据(如实时写入的小批次数据 ),先通过Cumulative Compaction逐步 “攒大”,减少后续 Base Compaction 的压力。
(2)Base Compaction
- 作用:当Cumulative Rowset 合并到一定规模后,再与 历史大 Rowset(Base Rowset)合并,最终形成更紧凑的大 Rowset,彻底优化查询路数。
(3)Cumulative Point:分层 “临界点”
用来划分 “Cumulative Rowset” 和 “Base Rowset” 的边界。比如某 Tablet 的 Cumulative Point 为 293,意味着:
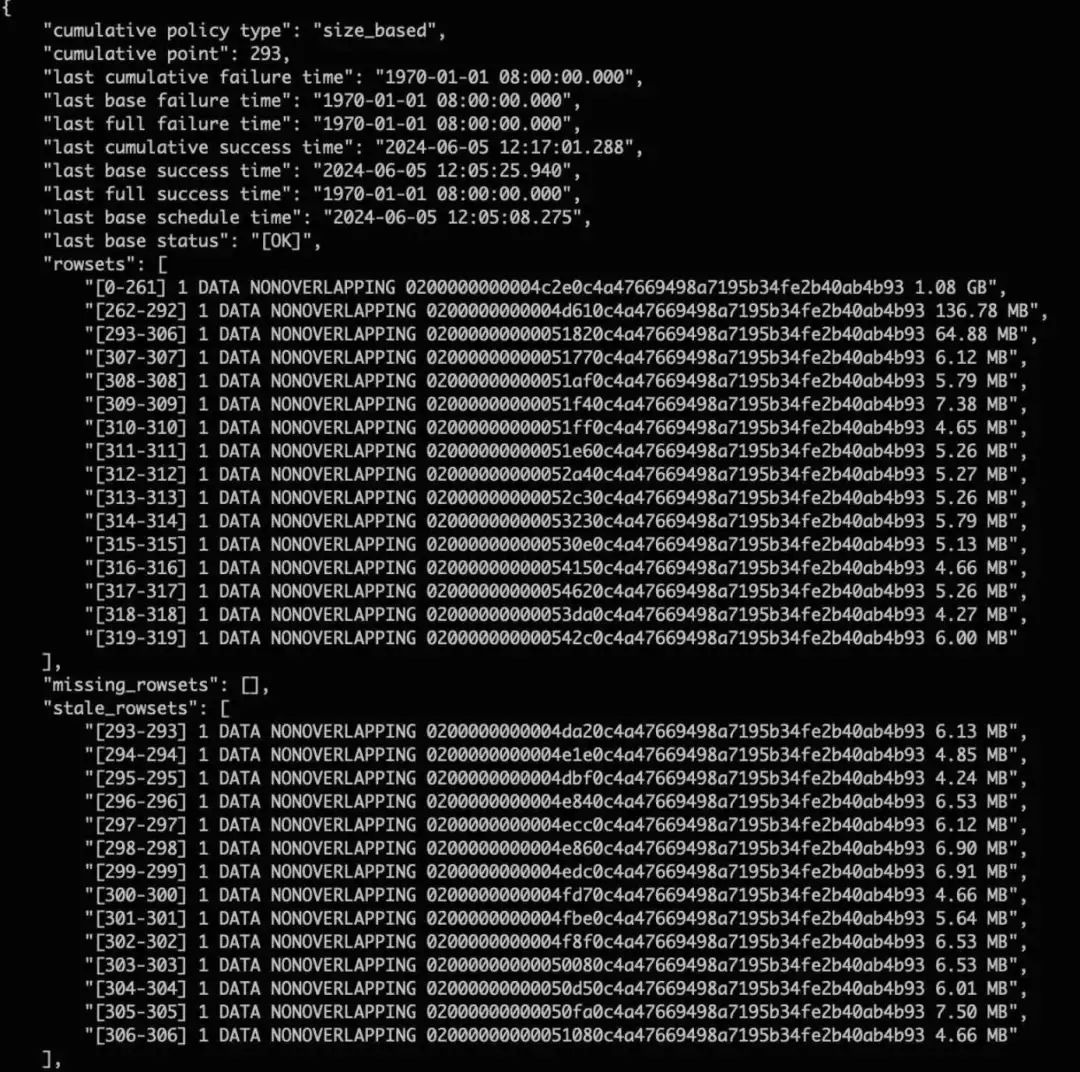
compaction图
compaction图
- Rowset 范围
293+做的是 Cumulative Compaction; - Rowset 范围
0-292做的是 Base Compaction。
三、Compaction 工作流程:生产者 - 消费者模式
Doris 的 Compaction 流程遵循生产者 - 消费者模型,可拆解为 4 大核心步骤,每个步骤都蕴含精细的设计逻辑:
1. 扫描与优先级计算(生产者线程)
BE 的 Compaction 生产者线程定时(可配置扫描间隔)扫描所有 Tablet,执行以下操作:
(一)计算 Compaction Score
遍历 Tablet 的 Rowset,统计每个 Rowset 在查询时的归并路数,累加得到 Compaction Score,确定compaction优先级。
(二)分层任务调度
Doris 通过轮询策略平衡 Base 和 Cumulative Compaction 的资源占用:
- 默认每 10 轮扫描选 1 次 Base Compaction 任务(处理历史大 Rowset 合并 );
- 其余 9 轮选 Cumulative Compaction 任务(快速合并新写入的小 Rowset )。 这样设计的原因是:Base Compaction 通常涉及更大数据量,资源消耗更高,需控制执行频率;而 Cumulative Compaction 处理小数据,可高频执行以快速优化查询。
2. 并发控制:避免磁盘过载
磁盘的 IO 带宽和处理能力是有限的,若同时执行过多 Compaction 任务,会导致磁盘性能雪崩(比如磁盘 IO 利用率瞬间 100%,其他读写操作阻塞 )。因此,Doris 会:
(一)检查当前任务数
查询磁盘当前运行的 Compaction 任务数,与配置的compaction的线程数对比。
(二)动态跳过机制
若任务数已达阈值,跳过该 Tablet,等待下一轮扫描;若未超限,允许任务继续,确保磁盘资源合理利用。
3. Rowset 筛选策略
并非所有 Rowset 都会被选中压缩,筛选逻辑聚焦两点,这直接影响 Compaction 的效率和效果:
(一)连续性优先
优先选择连续的 Rowset(如按时间或数据范围连续 ),因为零散的 Rowset 合并后,能减少查询时归并的 “碎片问题”。例如,连续的 Rowset 合并后,查询时可一次性归并,而零散 Rowset 可能需要多次跳转磁盘读取。
(二)数据量均衡
避免合并 “大小差距极大” 的 Rowset。在多路归并排序中,若 Rowset 数据量差距过大,归并时小 Rowset 会快速处理完,大 Rowset 仍需大量时间,整体效率会断崖式下跌。因此,筛选时会优先选数据量相近的 Rowset,保证归并过程的高效性。
4. 任务分发:分线程池执行
为了隔离 Base Compaction ·和 Cumulative Compaction 的资源,Doris 设计了两个独立线程池。
Base compaction线程池和cumulative compaction线程池分别从队列中取出compaction task任务后,执行多路归并排序:将多个 Rowset 的数据按顺序合并,生成一个新的大 Rowset。
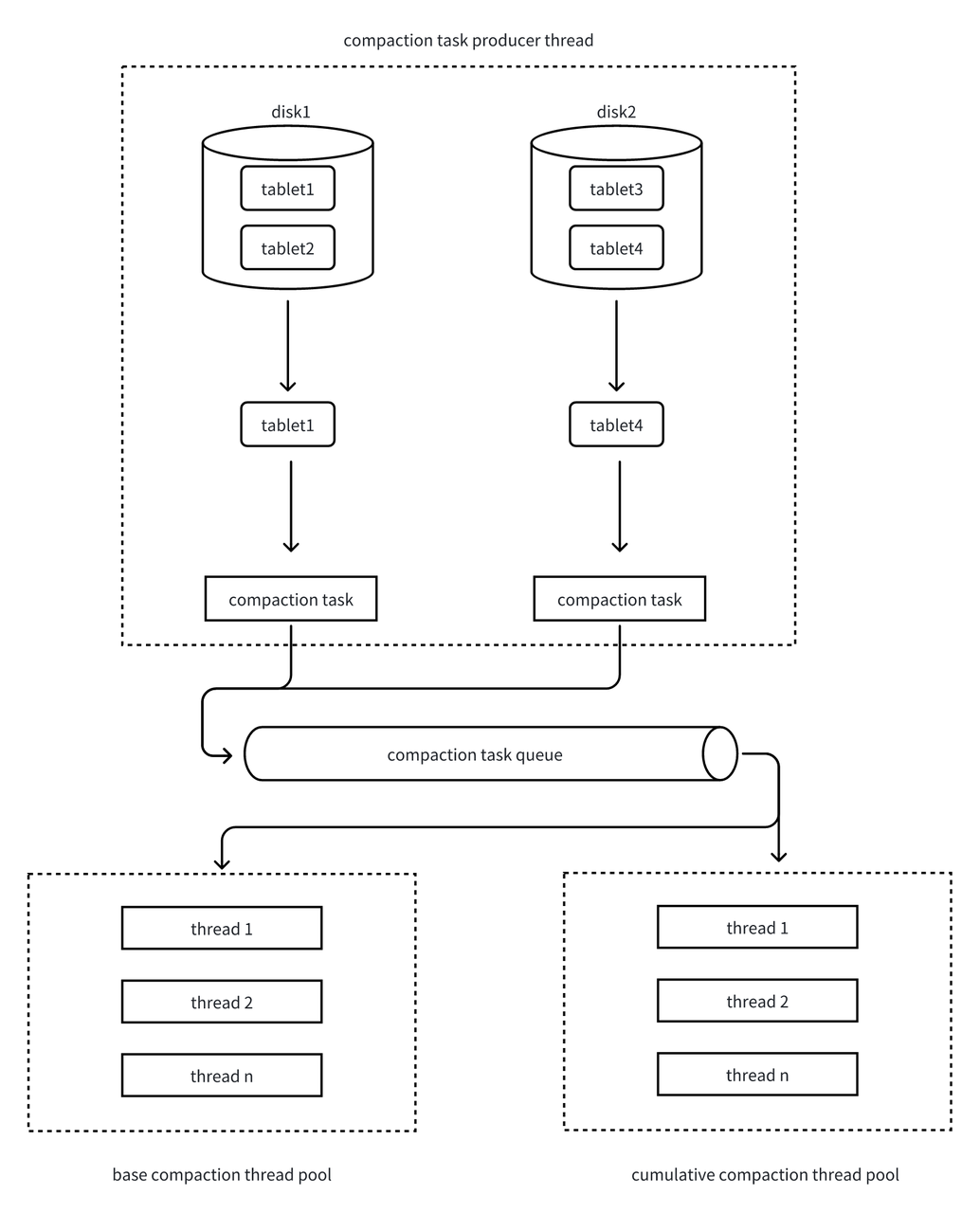
Compaction工作流程图
Compaction工作流程图
四、总结:Compaction 是效率与成本的平衡艺术
理解 Compaction 的逻辑后,再面对 “查询变慢”“存储膨胀” 等问题时,就能从 “数据版本管理” 的视角切入,精准定位与解决。下次遇到 Doris 性能瓶颈,不妨先看看 Compaction 是否在 “默默加班”,是否因配置或数据模式问题导致其 “有心无力”~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号