大模型本地部署,小号的vLLM来了


大家好,我是 Ai 学习的老章
GitHub 发布的 2025 年度开发者趋势报告一文中提到 2025 年最热门的项目分布在 AI 基础设施(vllm、ollama、huggingface/transformers)和持久的生态系统(vscode、godot、home-assistant)之间。
- 一方面,像 vllm、ollama、ragflow、llama.cpp 和 huggingface/transformers 这样的项目占据主导地位,这表明贡献者正在投资 AI 的基础层——模型运行时、推理引擎和编排框架。
- 另一方面,像 vscode、godot、expo 和 home-assistant 这样的主要生态系统继续吸引稳定的贡献者基础,表明开源的势头远远超出了 AI 领域。
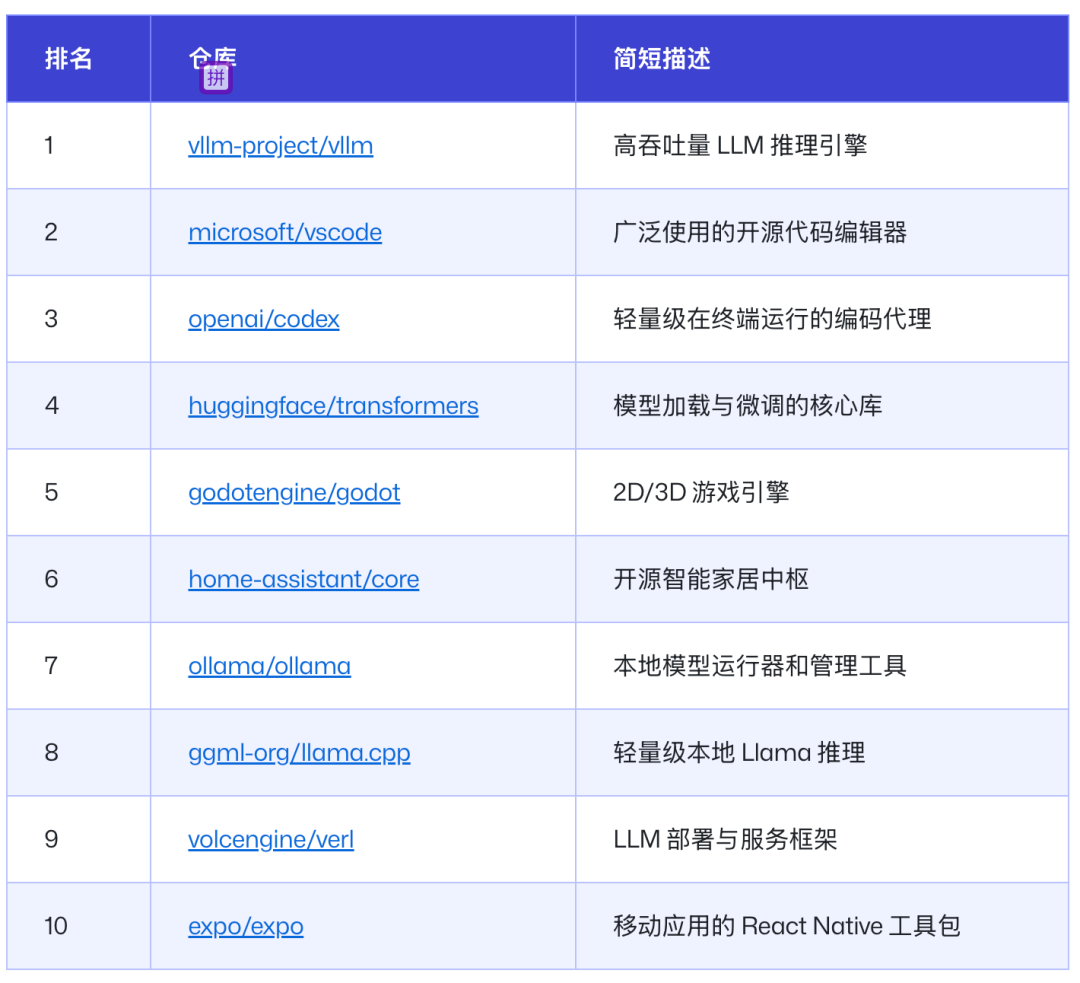
vLLM——2025 年增长最快的开源 AI 项目之一。
🏆 按贡献者数量排名的顶级开源项目 🚀 按贡献者数量增长最快的项目 🌱 吸引最多首次贡献者的项目
这个推理引擎也是我最喜爱的,本号测试部署的 N 多大模型都是用它来部署的
大模型_本地部署_,vLLM 睡眠模式来了 快手编程大模型真实水平,本地部署,实测 智谱 GLM-4.5-Air 量化大模型,本地部署,实测 字节跳动开源大模型 Seed-OSS-36B,本地部署,性能实测 本地部署大模型性能测试,DeepSeek-R1-0528-Qwen-8B 依然是我的不二之选 DeepSeek-R1-0528 蒸馏 Qwen3:8B 大模型,双 4090_本地部署_,深得我心
唯一让我不满的是我在内网用 docker 起 vLLM,它太大了,足足 22 个 GB
周末刚看到一个新项目:轻量级 vLLM 实现——Nano-vLLM
项目地址:https://github.com/GeeeekExplorer/nano-vllm
关键功能🚀 快速离线推理 - 推理速度与 vLLM 相当 📖 易读的代码库 - 约 1,200 行 Python 代码的简洁实现 ⚡ 优化套件 - 前缀缓存、张量并行、Torch 编译、CUDA 图等
一行命令安装pip install git+https://github.com/GeeeekExplorer/nano-vllm.git
手动下载模型权重,使用以下命令:
huggingface-cli download --resume-download Qwen/Qwen3-0.6B \
--local-dir ~/huggingface/Qwen3-0.6B/ \
--local-dir-use-symlinks False
网不通的话,可以使用我多次推荐的modelscope
pip install modelscope 之后,即可使用 modelscope download 下载模型
下载完整模型库
`modelscope download --model Qwen/Qwen3-0.6B
下载单个文件到指定本地文件夹(以下载 README.md 到当前路径下“dir”目录为例)
modelscope download --model Qwen/Qwen3-0.6B README.md --local_dir ./dir
API 与 vLLM 的接口类似,LLM.generate 方法有一些细微差别:
from nanovllm import LLM, SamplingParams
llm = LLM("/YOUR/MODEL/PATH", enforce_eager=True, tensor_parallel_size=1)
sampling_params = SamplingParams(temperature=0.6, max_tokens=256)
prompts = ["Hello, Nano-vLLM."]
outputs = llm.generate(prompts, sampling_params)
outputs[0]["text"]
看官方测试配置:**
- 硬件:RTX 4070 笔记本电脑(8GB)
- 模型: Qwen3-0.6B
- 总请求量: 256个序列
- 输入长度: 随机采样在100到1024个标记之间
- 输出长度: 随机采样在100到1024个标记之间
性能结果:
推理引擎 | 输出标记 | 时间(秒) | 吞吐量(令牌/秒) |
|---|---|---|---|
vLLM | 133,966 | 98.37 | 1361.84 |
Nano-vLLM | 133,966 | 93.41 | 1434.13 |
这种小模型,时延更小,吞吐量更大,看起来是很不错的样子
时间关系,我还没有本地跑大参数模型,后续肯定要试一试的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号