动动嘴就能查数据库,这个开源项目有点猛


大家好,我是 Ai 学习的
今天介绍一个让我眼前一亮的开源项目:Wren AI,一个 GenBI(生成式商业智能)Agent。
为什么现在需要 GenBI?
在数据驱动的时代,数据分析师是连接"数据"和"业务"的桥梁。但说实话,这活儿干起来很累——不同业务部门的需求五花八门,每个人想看的指标都不一样,分析师天天被各种"帮我拉个数据"的需求淹没。
LLM + RAG 的出现让人看到了希望:让 AI 自动查数据库、写 SQL,解放分析师的双手。
但理想很丰满,现实很骨感。

Text-to-SQL 为什么总是翻车?
说实话,Text-to-SQL 这个赛道我见过太多项目了,大部分都是"Demo 很惊艳,实际一用就拉胯"。
官方文档把问题总结得很到位,RAG + LLM 查数据库有四大挑战:
阶段一:上下文收集难
- 如何从各种数据源、元数据服务里整合信息?
- Schema、表关系、计算逻辑、聚合规则怎么存储和关联?
阶段二:检索精度差
- 向量库怎么优化?索引和分块策略很关键
- 语义搜索的理解偏差会严重影响结果准确性
阶段三:SQL 生成不靠谱
- 生成的 SQL 能跑吗?语法对吗?
- 不同数据库的 SQL 方言还不一样,PostgreSQL 和 MySQL 的写法就有区别
阶段四:协作困难
- 用户反馈怎么积累成知识?
- 数据权限怎么控制?总不能让 LLM 看到不该看的数据吧
简单说就是:你问"上个月销售额多少",LLM 根本不知道你公司里哪张表存销售数据、"销售额"是 total_amount 还是 revenue 字段、要不要排除退货订单……
Wren AI 的解法:语义层
Wren AI 的思路不是让 LLM 直接对着原始表结构硬生成 SQL,而是先建一层语义层(Semantic Layer),把业务概念和数据库字段的映射关系定义清楚。
这玩意儿就像给 LLM 配了一个"老员工"——知道公司业务怎么玩、数据怎么存、指标怎么算。
下图展示了完整的数据流:左边是各种数据源(PostgreSQL、Snowflake、BigQuery 等),中间是 Wren AI 的核心引擎(包含语义建模、访问控制、数据策略等模块),右边是输出端(可以对接 Slack、Teams、AI Agents 或直接生成报表)。
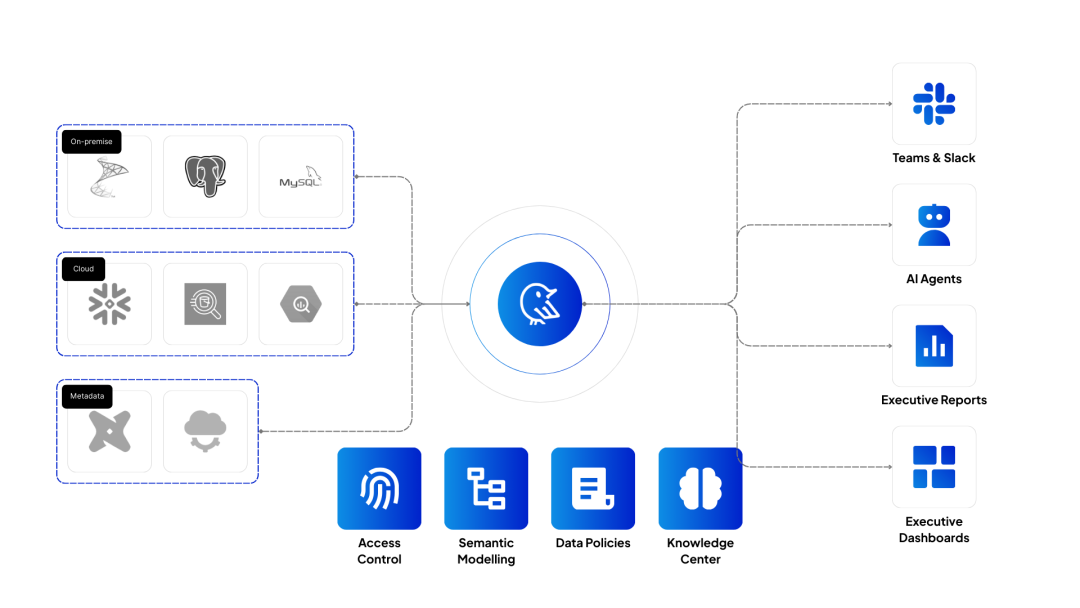
Wren AI 核心功能全景图
Wren AI 核心功能全景图
五大核心设计理念
官方文档里提到了 Wren AI 的五个设计理念,我挨个说说:
1. 多语言支持:用你的母语问数据
这点很贴心。支持英语、德语、西班牙语、法语、日语、韩语、葡萄牙语、中文等多种语言。不用再纠结怎么用英语描述业务问题了,直接用中文问就行。
2. 语义索引 + 精心设计的 UI/UX
Wren AI 实现了一套语义引擎架构,让你可以在原始 schema 上建立一层"逻辑表示层"。说人话就是:你可以告诉系统"这个字段叫什么"、"这两张表怎么关联"、"这个指标怎么算",然后 LLM 就能理解你的业务上下文了。
3. 带上下文生成 SQL
通过 MDL(Modeling Definition Language),你可以把元数据、schema、术语、数据关系、计算逻辑都编码进去。这样生成的 SQL 不仅更准确,还减少了重复代码,简化了表关联。
4. 不写代码也能获得洞察
用户提问后,Wren AI 会找到最相关的表,LLM 还会生成三个相关问题供你选择。支持多轮对话追问,越聊越深入。
5. 生成式报告
这个功能挺实用:AI 自动生成数据摘要和关键洞察,还能把查询结果一键转成图表和报告。从原始数据到可视化报表,一步到位。
还能对接 Excel 和 Google Sheets
官方提到 Wren AI 可以和 Excel、Google Sheets 无缝集成。这对很多业务人员来说太友好了——数据分析师的主战场可不就是 Excel 嘛。
架构解读
来看一下它的四层架构设计:
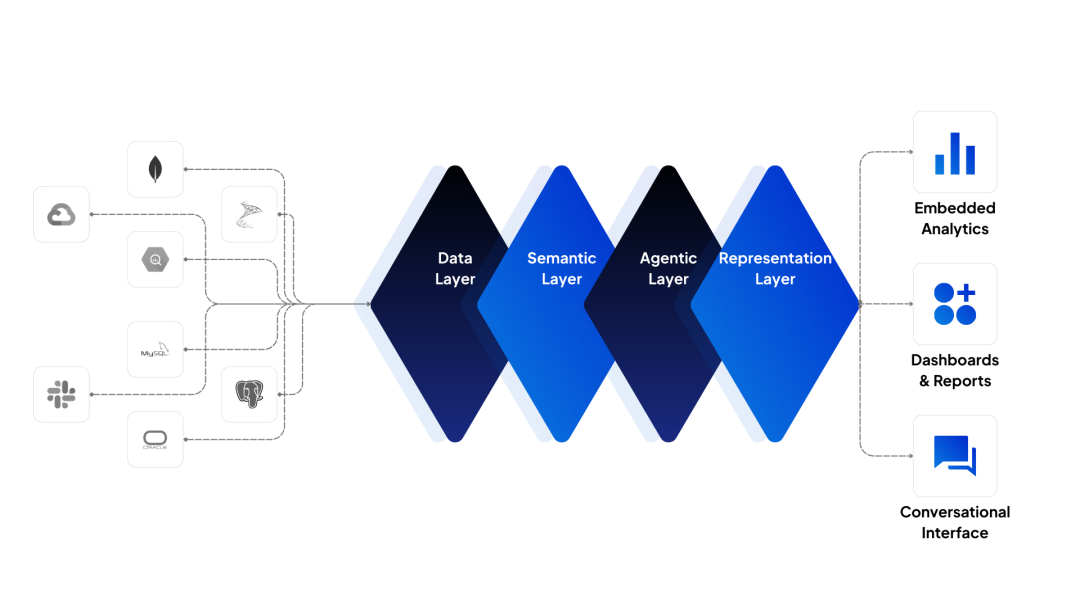
Wren AI 四层架构
Wren AI 四层架构
从下到上依次是:数据层 → 语义层 → 智能代理层 → 展示层。
重点说说中间两层:
- 语义层:把原始数据"翻译"成业务语言,LLM 不用再猜字段含义
- 智能代理层:编排 RAG、处理多轮对话、协调 SQL 生成和执行
这个设计比很多同类项目成熟多了。
再看详细的工作流:
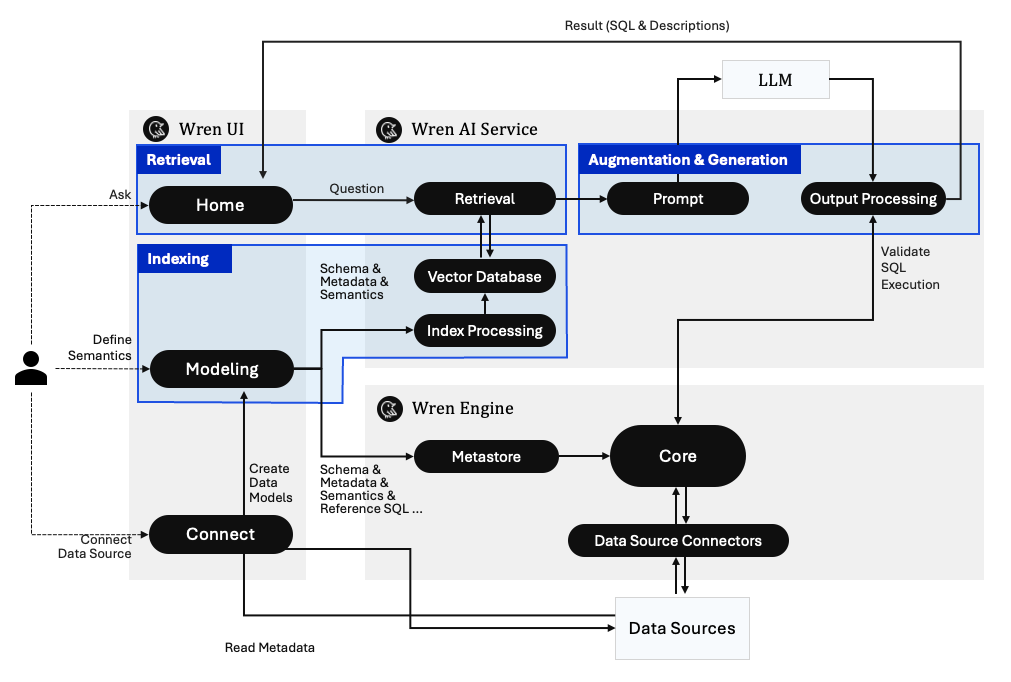
Wren AI 详细工作流
Wren AI 详细工作流
用户在前端 UI 提问 → Wren AI Service 通过 RAG 检索相关语义信息 → 调用 LLM 生成 SQL → Wren Engine 执行并验证 SQL 正确性 → 返回结果。
对,你没看错,它会验证 SQL 能不能正确执行,不是生成完就扔给你。这个闭环做得很扎实。
LLM 和数据源支持
不挑 LLM,这点我很喜欢:
- OpenAI (GPT-4o, GPT-4)
- DeepSeek
- Google Gemini
- Anthropic Claude
- Ollama(本地模型也能跑!)
- Azure OpenAI、Bedrock、Vertex AI、Databricks...
如果你公司有数据安全要求,不能把数据发到外部 API,用 Ollama 挂个本地模型就行,这点太实用了。
数据源几乎主流的都支持:
- PostgreSQL、MySQL、SQL Server、Oracle
- Snowflake、BigQuery、Databricks
- ClickHouse、DuckDB、Trino
基本上你能想到的数据仓库/数据库,它都有现成的 Connector。
安装
官方提供了一个 Wren AI Launcher,安装过程比较傻瓜化。
前置条件:
- 安装 Docker Desktop(版本 >= 4.17)
- 准备一个 OpenAI API Key(需要 Full Permission)
Mac 安装(Apple Silicon):
curl -L https://github.com/Canner/WrenAI/releases/latest/download/wren-launcher-darwin-arm64.tar.gz | tar -xz && ./wren-launcher-darwin-arm64
Mac 安装(Intel):
curl -L https://github.com/Canner/WrenAI/releases/latest/download/wren-launcher-darwin.tar.gz | tar -xz && ./wren-launcher-darwin
Linux 安装:
# Intel
curl -L https://github.com/Canner/WrenAI/releases/latest/download/wren-launcher-linux.tar.gz | tar -xz && ./wren-launcher-linux
# ARM64
curl -L https://github.com/Canner/WrenAI/releases/latest/download/wren-launcher-linux-arm64.tar.gz | tar -xz && ./wren-launcher-linux-arm64
Windows:下载 wren-launcher-windows.zip,解压后右键以管理员身份运行。
Launcher 会引导你选择 LLM Provider、输入 API Key,然后自动拉取 Docker 镜像并启动服务。完成后访问 http://localhost:3000 即可使用。
如果不想折腾本地部署,也可以试试 Cloud 版本:https://getwren.ai
详细安装文档:https://docs.getwren.ai/oss/installation
它适合谁?
- 数据分析师:不用再手写复杂 SQL,自然语言问就行
- 产品经理:自己拉数据做分析,不用老麻烦开发
- 企业开发者:想在自己产品里加个"数据问答"功能,它有完整的 API
- AI Agent 开发者:可以把它当成 Agent 的工具,让 AI Agent 具备查数据库的能力
和其他方案比
对比维度 | Wren AI | 普通 Text-to-SQL |
|---|---|---|
准确性 | 有语义层加持,更准 | 容易理解错业务含义 |
可控性 | 支持访问控制、数据策略 | 基本没有 |
多语言 | 支持中文等多语言 | 通常只支持英语 |
可视化 | 自动生成图表和报告 | 需要额外工具 |
私有部署 | 支持,可接本地 LLM | 看具体项目 |
成熟度 | 13.3k Star,150+ Release | 参差不齐 |
不足
当然也不是完美的:
- 学习成本:语义层需要花时间建模,小团队可能嫌麻烦
- LLM 依赖:效果取决于你选的模型,用弱模型效果会打折扣(官方也提醒了这点)
- 复杂查询:特别复杂的多表关联分析,可能还是得人工写 SQL
总结
Wren AI 是我最近看到的 GenBI 赛道最成熟的开源方案之一。它没有走"LLM 直接生成 SQL"这条看起来简单但坑很多的路,而是老老实实做了一层语义抽象。这个方向是对的。
官方文档写得也很清楚,把 RAG + LLM 查数据库的四大挑战(上下文收集、检索精度、SQL生成、协作)都点出来了,然后一一给出解决方案。这种"先讲问题再讲方案"的思路,说明团队对这个领域理解很深。
如果你的团队经常有"让 AI 帮我查数据"的需求,值得认真评估一下。
项目地址:https://github.com/Canner/WrenAI 官网:https://www.getwren.ai/oss 文档:https://docs.getwren.ai/oss/overview/introduction
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号