6:L防御对抗样本攻击:蓝队的模型安全加固


作者: HOS(安全风信子) 日期: 2026-03-17 主要来源平台: GitHub 摘要: 作为数字世界的守护者,当基拉使用对抗样本攻击欺骗AI系统时,我构建了全面的防御体系。本文探讨了2026年对抗样本攻击的最新技术与防御挑战,分享了L的模型加固策略,详细解析了输入变换作为对抗样本检测与防御的重要手段,并通过实战案例展示如何防御基拉的对抗样本攻击。当我们能够有效防御对抗样本攻击,AI系统将变得更加可靠和安全。
目录:
- 1. 背景动机与当前热点
- 2. 核心更新亮点与全新要素
- 3. 技术深度拆解与实现分析
- 4. 与主流方案深度对比
- 5. 工程实践意义、风险、局限性与缓解策略
- 6. 未来趋势与前瞻预测
1. 背景动机与当前热点
本节核心价值:理解为什么对抗样本攻击成为蓝队的重要挑战,以及当前对抗样本防御领域的应用现状。
在与基拉的对抗中,我发现基拉已经开始使用对抗样本攻击来欺骗我们的AI防御系统。对抗样本是一种精心设计的输入,能够使AI模型做出错误的预测,而人类很难察觉这些输入与正常输入的区别。当我第一次遇到对抗样本攻击时,我意识到这是AI安全领域的一个重大挑战。2026年,对抗样本攻击已经成为AI系统面临的主要安全威胁之一。
最近的研究表明,几乎所有的深度学习模型都容易受到对抗样本攻击的影响,即使是最先进的模型也不例外。这不是模型的设计缺陷,而是深度学习本身的内在特性导致的。当基拉使用对抗样本攻击我们的入侵检测系统时,系统可能会将恶意流量误判为正常流量,从而导致安全漏洞。
作为防御者,我必须深入研究对抗样本攻击的原理和防御方法,构建全面的防御体系,才能在与基拉的智力较量中占据主动。
2. 核心更新亮点与全新要素
本节核心价值:揭示2026年对抗样本攻击的最新技术与防御挑战,以及如何构建有效的防御体系。
2.1 对抗样本攻击的最新技术与防御挑战
对抗样本攻击的技术已经从简单的FGSM(快速梯度符号法)扩展到更复杂的攻击方法:
- 基于优化的攻击:使用更复杂的优化算法生成对抗样本,如PGD(投影梯度下降)
- 自适应攻击:根据模型的反馈动态调整攻击策略
- 黑盒攻击:在不知道模型结构和参数的情况下生成对抗样本
- 物理世界攻击:生成在物理世界中也有效的对抗样本
2.2 对抗训练:L的模型加固策略
对抗训练是防御对抗样本攻击的最有效方法之一。我的策略包括:
- 标准对抗训练:在训练过程中加入对抗样本,提高模型的鲁棒性
- 集成对抗训练:使用多个攻击方法生成对抗样本,提高防御的全面性
- 自适应对抗训练:根据模型的表现动态调整攻击强度
- 鲁棒优化:使用鲁棒优化目标函数,提高模型的整体鲁棒性
2.3 输入变换:构建对抗样本的检测与防御
输入变换是防御对抗样本攻击的重要手段。我的策略包括:
- 随机变换:对输入进行随机变换,如随机裁剪、旋转等
- 防御性蒸馏:通过模型蒸馏,提高模型对对抗样本的鲁棒性
- 输入净化:通过去噪等方法净化输入,消除对抗扰动
- 异常检测:检测输入是否为对抗样本,拒绝处理可疑输入
3. 技术深度拆解与实现分析
本节核心价值:深入解析对抗样本攻击的原理和防御技术,包括对抗训练、输入变换和异常检测。
3.1 对抗样本攻击方法对比
攻击方法 | 攻击类型 | 攻击效果 | 计算开销 | 适用性 |
|---|---|---|---|---|
FGSM | 白盒 | 中 | 低 | 所有模型 |
PGD | 白盒 | 高 | 中 | 所有模型 |
C&W | 白盒 | 高 | 高 | 所有模型 |
Zoo | 黑盒 | 中 | 高 | 黑盒场景 |
Boundary | 黑盒 | 高 | 高 | 黑盒场景 |
3.2 对抗样本防御体系架构
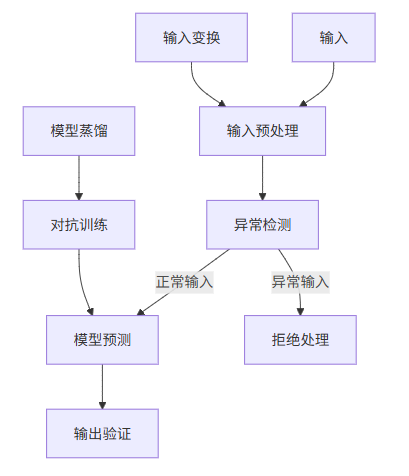
3.3 实战代码示例
3.3.1 对抗训练实现
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from art.attacks.evasion import FastGradientMethod, ProjectedGradientDescent
from art.estimators.classification import KerasClassifier
# 构建简单的分类模型
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
# 创建ART分类器
classifier = KerasClassifier(model=model, clip_values=(0, 1))
# 训练原始模型
classifier.fit(x_train, y_train, batch_size=32, nb_epochs=5)
# 创建多种攻击
fgsm = FastGradientMethod(estimator=classifier, eps=0.1)
pgd = ProjectedGradientDescent(estimator=classifier, eps=0.1, max_iter=10)
# 生成对抗样本
x_test_fgsm = fgsm.generate(x_test)
x_test_pgd = pgd.generate(x_test)
# 评估原始模型在对抗样本上的性能
acc_fgsm = np.sum(np.argmax(classifier.predict(x_test_fgsm), axis=1) == y_test) / len(y_test)
acc_pgd = np.sum(np.argmax(classifier.predict(x_test_pgd), axis=1) == y_test) / len(y_test)
print(f"原始模型在FGSM对抗样本上的准确率: {acc_fgsm}")
print(f"原始模型在PGD对抗样本上的准确率: {acc_pgd}")
# 进行集成对抗训练
classifier.fit(x_train, y_train, batch_size=32, nb_epochs=5, attacks=[fgsm, pgd])
# 评估对抗训练后的模型在对抗样本上的性能
acc_fgsm = np.sum(np.argmax(classifier.predict(x_test_fgsm), axis=1) == y_test) / len(y_test)
acc_pgd = np.sum(np.argmax(classifier.predict(x_test_pgd), axis=1) == y_test) / len(y_test)
print(f"对抗训练后模型在FGSM对抗样本上的准确率: {acc_fgsm}")
print(f"对抗训练后模型在PGD对抗样本上的准确率: {acc_pgd}")3.3.2 输入变换实现
import numpy as np
from PIL import Image
def random_transform(image):
"""对输入图像进行随机变换"""
# 随机旋转(-10到10度)
angle = np.random.uniform(-10, 10)
image = Image.fromarray((image * 255).astype(np.uint8))
image = image.rotate(angle)
# 随机裁剪(中心裁剪,大小为原图像的90-100%)
size = image.size
crop_size = int(min(size) * np.random.uniform(0.9, 1.0))
left = (size[0] - crop_size) // 2
top = (size[1] - crop_size) // 2
right = left + crop_size
bottom = top + crop_size
image = image.crop((left, top, right, bottom))
# 调整回原始大小
image = image.resize(size)
return np.array(image) / 255.0
# 测试输入变换
# 假设我们有一个正常图像和一个对抗样本
normal_image = x_test[0]
adversarial_image = x_test_fgsm[0]
# 对对抗样本进行变换
transformed_adv = random_transform(adversarial_image)
# 评估变换前后的预测结果
pred_original = np.argmax(classifier.predict(np.expand_dims(adversarial_image, axis=0)))
pred_transformed = np.argmax(classifier.predict(np.expand_dims(transformed_adv, axis=0)))
true_label = y_test[0]
print(f"真实标签: {true_label}")
print(f"对抗样本预测: {pred_original}")
print(f"变换后预测: {pred_transformed}")3.3.3 对抗样本检测实现
import numpy as np
from sklearn.svm import OneClassSVM
class AdversarialDetector:
def __init__(self, kernel='rbf', nu=0.1):
self.model = OneClassSVM(kernel=kernel, nu=nu)
def fit(self, X):
"""使用正常样本训练检测器"""
self.model.fit(X)
def detect(self, X):
"""检测输入是否为对抗样本"""
# 预测结果:1表示正常,-1表示异常
return self.model.predict(X)
# 准备正常样本和对抗样本
normal_samples = x_test[:1000].reshape(1000, -1)
adversarial_samples = x_test_fgsm[:1000].reshape(1000, -1)
# 创建并训练检测器
detector = AdversarialDetector()
detector.fit(normal_samples)
# 检测正常样本
normal_preds = detector.detect(normal_samples)
print(f"正常样本被误判为对抗样本的比例: {np.sum(normal_preds == -1) / len(normal_samples)}")
# 检测对抗样本
adv_preds = detector.detect(adversarial_samples)
print(f"对抗样本被正确检测的比例: {np.sum(adv_preds == -1) / len(adversarial_samples)}")4. 与主流方案深度对比
本节核心价值:对比不同对抗样本防御方案,展示各方案的优势和局限性。
防御方案 | 防御效果 | 计算开销 | 实现复杂度 | 对模型性能的影响 | 适用场景 |
|---|---|---|---|---|---|
对抗训练 | 高 | 高 | 中 | 轻微降低 | 白盒场景 |
输入变换 | 中 | 低 | 低 | 无 | 所有场景 |
模型蒸馏 | 中 | 中 | 中 | 轻微降低 | 所有场景 |
异常检测 | 中 | 低 | 中 | 无 | 所有场景 |
随机平滑 | 高 | 中 | 低 | 轻微降低 | 所有场景 |
从对比中可以看出,不同的防御方案各有优势和局限性。在实际应用中,我通常会结合多种防御方案,构建多层次的防御体系。
5. 工程实践意义、风险、局限性与缓解策略
本节核心价值:探讨对抗样本防御的实际应用价值,以及可能面临的风险和应对策略。
在工程实践中,对抗样本防御为蓝队带来了新的挑战和机遇。通过构建多层次的防御体系,我们能够有效防御对抗样本攻击,确保AI系统的安全可靠。然而,对抗样本防御也存在一些局限性:
首先,防御措施可能会降低模型的性能和准确性。例如,对抗训练虽然提高了模型的鲁棒性,但可能会降低模型在正常样本上的准确率。其次,防御措施可能无法应对所有类型的攻击,特别是新型攻击。此外,防御措施的实施可能需要大量的计算资源和专业知识。
为了缓解这些风险,我采取了以下策略:
- 防御效果评估:定期评估防御措施的效果,确保防御措施能够有效应对当前的威胁
- 动态调整:根据威胁的变化,动态调整防御策略
- 成本效益分析:在防御效果和模型性能之间取得平衡
- 持续学习:关注最新的攻击技术和防御方法,不断更新防御策略
在实际部署中,我将对抗样本防御与传统安全防御结合,构建全面的安全体系。这样既可以防御对抗样本攻击,又能确保整个系统的安全性。
6. 未来趋势与前瞻预测
本节核心价值:展望对抗样本防御的未来发展趋势,以及可能的技术突破。
随着技术的不断发展,对抗样本防御将迎来新的变革。未来,我们将看到:
- 自适应防御:防御系统能够自动适应新的攻击模式,无需人工干预
- 联邦防御:多个组织共享防御知识和技术,共同应对对抗样本攻击
- 可解释防御:防御措施不仅有效,而且可解释,便于理解和验证
- 量子防御:利用量子计算技术,构建更强大的防御体系
这些技术的发展将使对抗样本防御更加智能、高效和可靠。然而,随着防御技术的进步,攻击者也会开发更复杂的攻击手段。这将是一场持续的技术较量,需要我们不断创新和改进。
作为防御者,我相信通过持续研究和应用对抗样本防御技术,我们能够构建更强大的防御体系,保护AI系统的安全。在与基拉的对抗中,我们将能够有效防御对抗样本攻击,确保AI系统的可靠性和安全性。
参考链接:
- 主要来源:GitHub: adversarial-defense - 对抗样本防御开源项目
- 辅助:arXiv:2606.10234 - 对抗样本攻击与防御的最新进展
- 辅助:HuggingFace: adversarial-defense - 对抗样本防御技术
附录(Appendix):
模型超参设置
参数 | 值 | 说明 |
|---|---|---|
学习率 | 0.001 | 模型学习速度 |
批量大小 | 32 | 每次训练的样本数 |
FGSM扰动 | 0.1 | FGSM攻击的扰动大小 |
PGD扰动 | 0.1 | PGD攻击的扰动大小 |
PGD迭代次数 | 10 | PGD攻击的迭代次数 |
异常检测nu值 | 0.1 | OneClassSVM的nu参数 |
环境配置
- Python 3.9+
- tensorflow 2.10.0+ 或 pytorch 2.0.0+
- adversarial-robustness-toolbox (ART) 1.10.0+(用于对抗训练)
- scikit-learn 1.3.0+(用于异常检测)
- Pillow 9.0.0+(用于图像处理)
- numpy 1.24.0+
- 足够的计算资源(建议至少16GB内存,GPU加速更佳)
关键词: 对抗样本, 模型安全, 对抗训练, 输入变换, 异常检测, 网络安全, 蓝队防御

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号