1PB 数据免费送,卖数据的公司慌了吗?

1PB 数据免费送,卖数据的公司慌了吗?

数据微光
发布于 2026-03-31 18:05:24
发布于 2026-03-31 18:05:24
昨天刷 HuggingFace 的时候,一个数字让我停下来了:1PB。
一家叫 Ropedia 的公司,把 1PB 的具身智能数据集直接扔上了 HuggingFace,免费开源。1000 万条交互体验,10000 小时同步录像,28.8 亿帧 RGB 图像,7.2 亿帧深度图。手部动捕、全身动捕、IMU、语言标注,全都有。
这个数据集叫 Xperience-10M,据说价值千万。
数据集地址:https://huggingface.co/datasets/ropedia-ai/xperience-10m
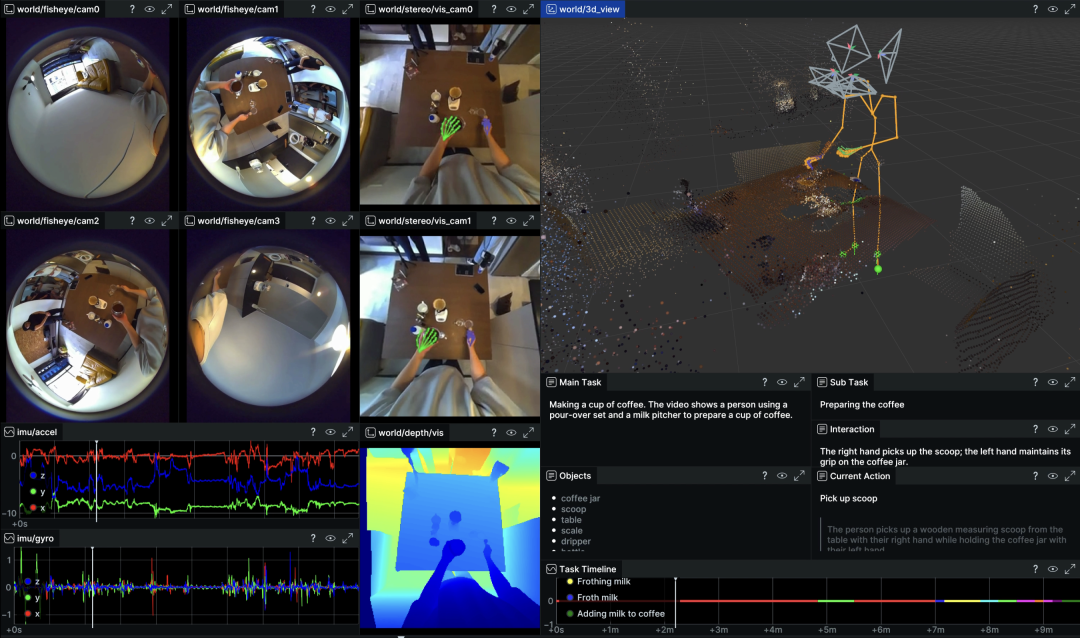
说实话,我第一反应不是兴奋,是替一些人捏了把汗。过去两年涌进具身智能数据赛道的创业公司,刚把商业计划书写好,转头发现有人把同类数据白送了。这感觉,大概跟当年做 LLM API 中间商的人看到 Meta 开源 LLaMA 差不多。

具身智能最缺的东西,就是数据
大语言模型靠互联网文本训练,图像模型有 ImageNet 打底。但机器人训练数据?Open-X-Embodiment 是之前最大的开源机器人数据集,规模比 Common Crawl 小 1673 倍。三个数量级的差距。

但 2025 年开始,事情变了。HuggingFace 上的机器人数据集从 2024 年的 1000 个暴增到 2025 年的 27000 个,是所有 AI 训练数据里增长最快的品类。更关键的是,几个大型开源数据集几乎同时出现:
- • Xperience-10M(Ropedia):1PB,1000 万条交互,第一视角全模态
- • RealOmni-Open(GenrobotAI):10000+ 小时,100 万+ 片段,覆盖 3000+ 真实家庭场景
- • Open-X-Embodiment 持续扩展,已覆盖 22 种机器人形态
数据荒的时代,正在快速结束。
Xperience-10M 凭什么特别
Ropedia 的数据集有三个让我印象深刻的地方。
全是第一视角。 人戴着头盔录的,不是监控摄像头拍的。机器人要用自己的眼睛看世界,第一视角数据才是它真正需要的学习素材。
模态极全。 六路视频流、音频、立体深度、相机位姿、手部动捕、全身动捕、IMU、分层语言标注,一套设备同时采集,全部时间同步。研究者拿来就能训世界模型、做 sim-to-real 迁移,不用自己对齐多个数据源。
1PB 级别。 HuggingFace 上 27000 个机器人数据集,大部分是几十 GB 的小数据集。1PB 级别的,目前只此一家。

免费送,图什么?
Ropedia 不是在做慈善。这家公司今年 3 月刚完成数千万美元种子轮融资,投资方背景包括 Google、NVIDIA、Amazon 前高管,加上亚洲头部美元基金。创始团队来自新加坡南洋理工大学,CEO 陈昭熹和 CTO 洪方舟都是清华本科出身,导师是计算机视觉领域的刘子纬教授。
他们真正卖的是数据采集基础设施。核心产品 HOMIE 是一个头戴式多模态采集设备,已经进入量产,号称把采集成本降低 50 倍,目前服务十几家北美头部公司。
逻辑很清楚:数据开源 → 建立行业标准 → 更多人用你的格式和工具 → 你的硬件和服务成为默认选择。Hugging Face 把平台免费开放,靠企业服务赚钱。Meta 开源 LLaMA,靠广告生态回收价值。Ropedia 开源 1PB 数据,真正赚钱的是 HOMIE 设备和采集方案。
还有个细节:许可协议是 CC BY-NC 4.0,非商用。学术研究随便用,商业公司想拿去训模型?得找 Ropedia 谈。
免费的午餐从来不免费。
卖数据的公司怎么办?
这才是我最想聊的。
过去两年,超过 10 亿美元投向了试图填补机器人数据缺口的初创公司。这些公司大致分两类:
第一类,做通用采集的。 雇人录数据、做标注,打包卖给机器人公司。
第二类,做垂直场景的。 专注某个领域(工厂产线、仓库分拣、手术室操作),提供高度定制化的数据。
Xperience-10M 冲击最大的是第一类。
数据平台 Codatta 最近有篇分析说得很到位:基础操控数据已经在被商品化。当 Xperience-10M、RealOmni、Open-X-Embodiment 同时涌现,通用数据的稀缺性就不存在了。
你的护城河如果建在「我有数据你没有」上面,那这条河正在被一群开源项目填平。
但第二类公司暂时安全。工厂里拧螺丝的数据、手术室里缝合的数据、密集杂乱环境下的精密操作数据,这些 Xperience-10M 里没有,短期内也不会有人免费送。Codatta 的分析也指出,仿真数据在涉及流体、布料变形、高精度装配这些领域,和真实数据的差距仍然巨大。真实世界的场景专属数据仍然有不可替代的溢价。
我的判断:通用数据终将被开源吞噬,场景专属数据才是真正的壁垒。 这和大模型领域的演化路径很像。基础模型开源了(LLaMA、Qwen、DeepSeek),但垂直行业的微调数据和 know-how 仍然值钱。具身智能大概率也走这条路。
写在最后
一年前大家还在讨论具身智能的数据从哪来,现在已经开始比谁的数据集更大、更全、更开放。这个速度超出了我的预期。
开源数据的真正意义不在免费,在于它重新定义了竞争维度。当基础数据不再稀缺,拼的就是谁能在特定场景里做出别人替代不了的东西。那些还想靠通用数据搬运赚差价的公司,确实该紧张了。
数据的战争已经开打,但输赢的标准变了。
看清方向,比跑得快更重要。我是向光,下次见。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号