ResNet优化超深网络的训练原理


ResNet(残差网络)通过引入 残差连接 ,解决了超深网络难以训练的问题,使得网络层数可以突破百层甚至千层,大幅提升了视觉任务的性能。
1
ResNet是什么?
一句话定义 :ResNet是一种通过 残差连接 (或称为“短路连接”)来构建极深卷积神经网络的结构,使得网络可以轻松达到上百层甚至上千层。
在ResNet之前,人们普遍认为“越深的网络,表达能力越强,性能越好”。但实验发现,当网络层数增加到一定程度后, 训练误差反而上升 ,这并非过拟合,而是因为网络优化变得极其困难。ResNet正是为了解决这一“网络退化”问题而诞生。
2
ResNet的工作原理
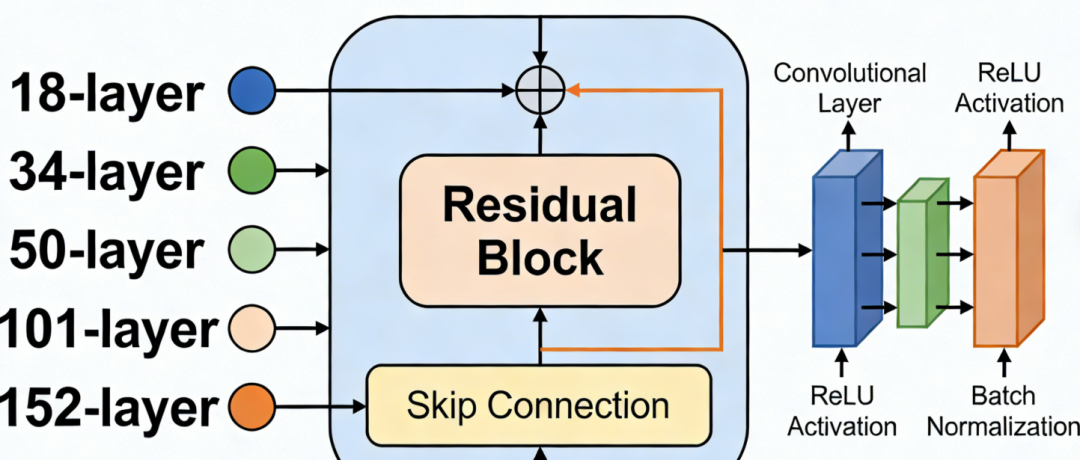
1. 残差块的核心思想
传统网络试图直接学 习目标映射 H(x),ResNet则改为学习残差映射F(x)=H(x)−x,而最终的输出是 F(x)+x,也就是说,网络不再直接学习完整的输出,而是学习输入与输出之间的“差异”。
残差块公式 :
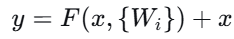
其中 x 是输入,F是需要学习的残差函数(通常是两三层卷积),而 x通过“短路连接”直接与输出相加。
恒等映射 :如 果 F学习到0,则 y=x,网络至少F学习到0,则y=x不会比浅层网络差。这种“至少不退化”的特性是ResNet能堆叠超深层的理论基础。
2. 两种常见的残差块结构
结构 | 说明 | 适用场景 |
|---|---|---|
BasicBlock | 两层卷积(3×3 → 3×3),用于较浅的ResNet(如ResNet-18、ResNet-34) | 计算量较小 |
Bottleneck | 三层卷积(1×1 → 3×3 → 1×1),中间层降维再升维,减少计算量 | 用于深层网络(如ResNet-50、ResNet-101、ResNet-152) |
Bottleneck设计 :先用1×1卷积降维(减少通道数),再用3×3卷积提取特征,最后用1×1卷积恢复通道数。这样在保持表达力的同时,大幅降低了计算量。
3. 当输入输出维度不匹配时
如果残差块的输入和输出维度不同(例如由于步长卷积导致空间尺寸减半或通道数增加),短路连接不能直接相加。此时有两种处理方式:
- 填充零 :在短路上用零填充维度,不引入额外参数。
- 投影连接 :在短路上添加一个1×1卷积,将输入映射到目标维度。通常用于维度变化时,以保持信息流动。
3
ResNet如何发挥作用
ResNet的有效性可以从多个角度解释:
1. 缓解梯度消失
在深层网络中,反向传播的梯度需要经过多层非线性变换。如果没有短路连接,梯度会随着层数增加而指数级衰减。残差连接为梯度提供了一条“高速公路”,使得梯度可以直接回传,避免了梯度消失问题。
数学上,对于 残差块 y=x+F(x),反向传播时:
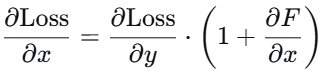
常数项1保证了梯度不会消失,即 使 ∂F/∂x很小,梯度也能有效传播。
2. 解决网络退化问题
如果没有残差,当层数加深时,网络可能会“忘记”之前学到的映射,导致优化困难。残差连接让网络可以 以恒等映射为起点 ,逐步学习增量,使得优化更容易。换句话说,网络只需要在已有基础上做微小调整,而不是从头学习完整映射。
3. 隐式的集成学习
有研究认为,残差网络可以看作是一系列浅层网络的 隐式集成 。因为每个残差块可以看作是一个“路径”,最终的输出是不同路径的组合,这增强了模型的鲁棒性和泛化能力。
4. 加速收敛
由于梯度流动顺畅,残差网络可以使用更大的学习率,收敛速度明显快于同等深度的普通网络。
4
ResNet的后续演进与更优方案
ResNet之后,研究者们在多个方向上进行了改进,涌现出大量更优的架构。下表对比了其中最具代表性的几种:
模型 | 核心创新 | 关键特点 | 优势 | 劣势 |
|---|---|---|---|---|
ResNet | 残差连接 | 极深网络、恒等映射 | 开创性,稳定易用 | 效率非最优,参数量较大 |
DenseNet | 密集连接 | 每层与之前所有层连接,特征复用 | 参数利用率高,梯度流动极佳 | 内存占用大,推理速度稍慢 |
ResNeXt | 分组卷积 | 在ResNet基础上引入“基数”概念,多分支并行 | 在同等参数量下性能更好 | 设计稍复杂 |
SENet | 通道注意力 | 自适应地重标定通道特征,强调重要通道 | 在原有网络上即插即用,提升显著 | 增加少量计算 |
EfficientNet | 复合缩放 | 同时缩放深度、宽度、分辨率,使用NAS搜索 | 在FLOPs和精度上达到帕累托最优 | 训练复杂度高 |
RegNet | 设计空间 | 通过大规模实验总结出简单高效的网络设计模式 | 在低FLOPs下表现优异 | 实验成本高 |
ConvNeXt | 现代化CNN | 借鉴Swin Transformer的设计思想,对ResNet进行“现代化改造” | 在ImageNet上超越Swin Transformer | 仍属CNN范畴,未突破Transformer |
Swin Transformer | 移位窗口注意力 | 将Transformer引入视觉,通过移位窗口实现高效全局建模 | 在COCO等任务上成为新的SOTA | 计算量仍较大,但已优化 |
对比分析
- DenseNet vs ResNet :DenseNet通过密集连接实现了特征复用,参数量更小,但内存占用大,训练时需谨慎处理。
- ResNeXt vs ResNet :ResNeXt通过分组卷积增加了网络宽度(基数),在同等复杂度下提升了精度,成为ResNet的常用改进版。
- SENet :不改变网络主体结构,仅添加通道注意力模块,可嵌入各种CNN中提升性能,简单有效。
- EfficientNet :通过NAS搜索出深度、宽度、分辨率的最佳组合,在移动端和低计算量场景下表现优异。
- Swin Transformer :将Transformer引入视觉,并针对视觉特性设计移位窗口注意力,在多项视觉任务上刷新纪录,但其核心思想已不再是ResNet风格。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号