非单调缺失机制下非参数估计的渐近性:贝叶斯视角

非单调缺失机制下非参数估计的渐近性:贝叶斯视角

CreateAMind
发布于 2026-04-03 09:27:21
发布于 2026-04-03 09:27:21
Asymptotics of Nonparametric Estimation under general non-monotone MAR missingness: A Bayesian Approach
非单调缺失机制下非参数估计的渐近性:贝叶斯视角
https://arxiv.org/pdf/2603.23449

摘要
缺失值在(数据)科学中无处不在,可能对任何统计分析产生潜在的有害后果。因此,近年来开发了大量方法和理论结果。尽管如此,许多问题仍未解决,特别是在一般非单调随机缺失(MAR)的情况下。在这项工作中,我们将非参数贝叶斯理论扩展到此 MAR 设置。我们引入了一个 MAR 下后验收缩的一般定理以及一个额外的温和正性条件。利用这一结果,我们能够表明,尽管存在缺失值,无污染数据的密度可以用极小极大后验收缩率(直至对数因子)进行估计。据我们所知,这是第一个非参数结果,表明在 Rubin 的 MAR 定义下可以一致地估计无污染分布。因此,我们获得了一种算法,该算法接受受缺失值污染的数据,并返回来自无污染分布的可证明一致估计的样本。
1 引言
缺失数据是现代数据科学应用中的一个普遍问题,也是一个活跃的研究领域。在存在缺失数据的情况下,人们不再观测到完整的数据点,而只观测到部分值,以及观测条目所在的位置。通常,这需要引入一个缺失数据机制(MDM)模型,该机制决定哪些值缺失。一种经典且有效的方法由 Rubin (1976) 引入,即使用满足随机缺失(MAR)属性的条件分布来建模 MDM——意味着缺失概率仅取决于观测值——并将 MDM 与数据模型分开参数化。在这种建模选择下,MDM 在某种意义上变得可忽略,即在完整联合模型上最大化观测值及其位置的似然性,与仅最大化观测值的边缘似然性,所得到的数据参数 θθ 估计量完全相同。这一原则也扩展到贝叶斯推断(当假设数据和 MDM 参数之间先验独立时),极大地简化了缺失数据分析领域的推断和计算。
尽管“可忽略性”原则具有直观吸引力并被广泛采用(允许研究人员和从业者在不建模潜在复杂缺失机制的情况下估计 θ),但其理论基础几十年来仍有些未定。确实,虽然 MAR MDM 模型在最大似然估计量 (MLE)
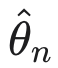
的定义中使缺失机制可忽略,但这本身并不能保证基于所谓可忽略似然的推断的统计有效性。Rubin 具有影响力的表述具有说服力,并塑造了缺失数据的大部分应用和方法论文献;然而,严格的数学论证直到相对最近才大量出现。正如 Takai 和 Kano (2013) 所强调的,许多基础文本——包括著名的专著 Little 和 Rubin (2019)——呈现基于不完整数据似然的推断,仿佛它自然继承了完整数据推断的大样本性质,而没有为所得估计量提供一致性或渐近正态性的形式证明。在一项显著的贡献中,Takai 和 Kano (2013) 通过证明在标准正则条件下,忽略 MDM 的 MLE
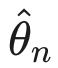
确实是一致的且渐近正态的,解决了这一差距,前提是真实的缺失数据机制本身是 MAR 的。在这个意义上,Takai 和 Kano (2013) 的结果为长期以来的主张提供了理论验证,即真实缺失数据机制的 MAR 性质是基于可忽略似然的推断可靠的关键条件。
虽然这解决了规则参数模型的 MLE
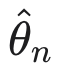
的情况,但几个基本问题仍未解决:
- 首先,在可比条件下,贝叶斯推断是否享有类似的保证?
- 其次,基于可忽略似然的推断的统计有效性能否扩展到参数设置之外?
这些问题推动了本项工作。我们表明,丰富的贝叶斯理论结合 Kullback-Leibler (KL) 散度的自然使用,允许在 MAR 缺失下获得一般非参数收敛结果。特别是,我们表明可以在一般非单调 MAR 缺失和温和正性假设下非参数地估计完整密度。因此,我们自然地得到了一种方法,该方法能够接受 MAR 缺失数据,并从先前被缺失性掩盖的(未观测到的)基础分布中产生新样本。尽管缺失性文献浩瀚,这似乎是一般非单调 MAR 的第一个非参数一致性结果。由于 MAR 概念已有 30 多年历史,且被一些人视为已解决的问题,这似乎令人惊讶。确实,镜像 MLE 情况下关于 MAR 的讨论,论文经常声称"X 在 MAR 下有效”。然而,正如 Seaman 等人 (2013); Näf 等人 (2026) 和其他人所讨论的,这种印象可能部分源于对 MAR 条件本身的混淆。理论上确实已在较弱的缺失条件下获得结果,例如缺失概率取决于数据中始终观测到的子集。此外,在结构化问题情况下出现了大量理论结果,例如具有缺失性的特定回归问题,通常与此类简化缺失机制结合,参见例如 Wang 和 Rao (2002); Qin 等人 (2009); Yuan 和 Dong (2019); Chen 和 Yu (2016); Liu 和 Fan (2023); Zhao 和 Candès (2025)。然而,据我们所知,(参数) MLE 之外的一般 MAR 下的一致性结果此前尚未开发。事实上,即使尝试将忽略原则扩展到 M 估计,通常也会产生不一致的估计量,参见例如 Frahm 等人 (2020)。
本文其余部分组织如下:在第 2 节中,我们介绍了关于缺失值、MAR 条件和可忽略性的详细背景,并介绍了我们的符号。在介绍 MAR 条件和相关符号后,我们在第 3 节更详细地讨论了相关文献并概述了我们的贡献。第 4 节随后提出了 MAR 缺失下的一般后验收缩结果。第 5 节将这些结果应用于
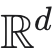
上的密度估计,从而得出极小极大估计结果。最后,第 6 节提供了一个小型模拟研究,第 7 节得出结论。
2 背景与符号



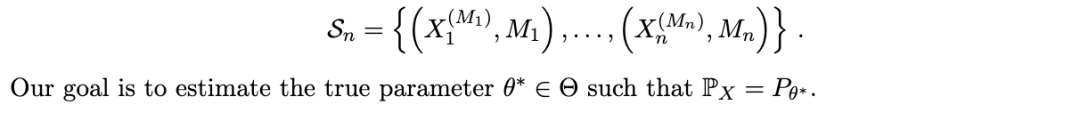
2.1 随机缺失
本文专注于某一特定族的缺失机制,通常被称为随机缺失,其由以下假设刻画:

上述使用的 MAR 属性,形式上陈述缺失机制(即给定 XX 时 MM 的条件分布)不依赖于缺失值本身(给定观测值),是文献中存在的几种随机缺失变体的一个特例(始终随机缺失),参见例如,Mealli 和 Rubin (2015);Näf 等人 (2026) 以及其中的文献。我们注意到,假设 2.1 接近但不完全等同于 Rubin (1976) 的原始 MAR 版本。至关重要的是,与文献中使用的替代方案相比,它是最弱的 MAR 假设之一。例如,通常假设 P(M=m∣X) 仅依赖于一组完全观测的变量,这是一个强得多的假设(参见例如,Näf 等人 (2026) 中的讨论)。
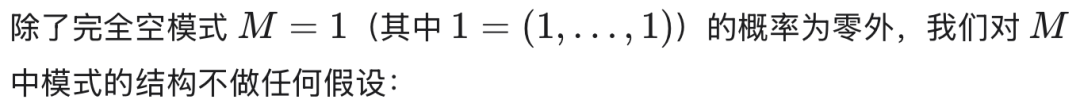




2.2 MAR 下基于似然推断的可忽略性

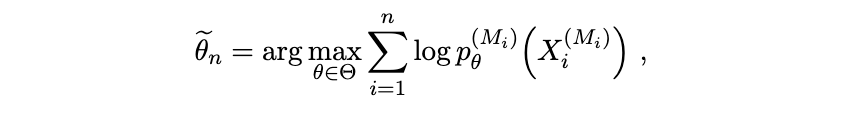

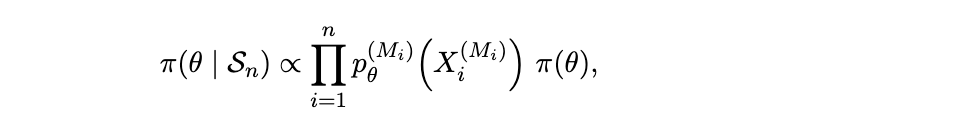

2.3 符号
我们现在介绍并总结全文中使用的符号。


3 问题陈述与贡献
在本节中,我们首先深入探讨相关文献,然后讨论我们的贡献。
3.1 相关文献
术语 MAR(随机缺失)一直是文献中频繁引起混淆的原因,正如大量仅仅讨论 MAR 定义的论文所表明的那样,例如 Seaman 等人 (2013);Mealli 和 Rubin (2015);Näf 等人 (2026)。文献中常声称“在 MAR 下,可忽略的基于似然的推断是有效的”。然而,这类陈述往往模棱两可。事实上,频率学派的有效性(即一致性意义下)迄今为止尚未在一般模型中正式确立,且仅在相对最近才针对规则参数完整数据模型得到解决。Rubin (1976) 明确确立的是关于 θθ 的完整与可忽略基于似然推断之间的等价性,前提是缺失数据机制的模型是 MAR(且参数互异)——无论真实缺失机制的性质如何。然而,当真实缺失数据机制是 MAR(如假设 2.1 所表述)时,这种方法是否仍然在统计上有效,则是一个不同且直到最近仍未解决的问题。
相反,虽然目前已有丰富的参数和非参数理论致力于处理缺失值,但针对一般非单调 MAR 情况的保证显著稀缺。虽然在 MLE 估计(Takai 和 Kano (2013))和插补(Wang 和 Robins (1998);Guan 和 Yang (2024))的参数情况下有一些有趣的结果,但我们并不知晓在此情况下有一般的非参数结果。例如,在 M 估计的背景下,Frahm 等人 (2020) 表明,简单的忽略估计量不再保证在 MAR 下是一致的。这也在第 5.1 节中得到了说明。一种直观的补救措施是重加权方法,该方法利用条件概率 P(M=m∣X=x) 的估计值对数据进行重加权,从而产生逆概率加权(IPW)估计量。然而,在非单调 MAR 下,这种方法并不直接。例如,Sun 和 Tchetgen (2018) 讨论了此设置下 IPW 估计量的困难,并提出了一种缺失概率的参数模型,允许对数据进行重加权以获得一致的结果。然而,这种参数形式似乎相当有限,且基于 IPW 的估计量需要估计模式概率,这在我们的设置中可能难以处理,因为在我们的设置中可能仅能偶尔观测到某种模式。因此,IPW 估计量的理论似乎主要是在单调缺失的背景下发展的(参见例如,Seaman 和 Vansteelandt (2018))。
对此的一个显著例外,也是极少数能够在 MCAR 之外为一般非单调模式下的 M 估计提供渐近保证的论文之一,是开创性的论文 Daniel Malinsky 和 Tchetgen (2022)。然而,他们研究的是无自删失(no-self-censoring)机制,这与 MAR 有着根本的不同。此外,他们再次要求用逆概率对其观测点进行复杂的重加权。在另一篇重要的近期论文 Chen 和 Sadinle (2019) 中,利用核密度估计器和识别条件估计了缺失值下多元样本的完整分布 Pθ∗ 。他们提供了由此分布估计导出的一致估计量甚至渐近正态性的一般保证。这在精神上与我们作为理论的自然应用而获得的密度估计器相近。然而,他们再次关注单调缺失。虽然他们也讨论了非单调缺失的可能性,但这需要相当复杂的识别条件,这些条件比 MAR 更强。特别是,他们的方法不能用于第 5.1 节中的例子。因此,虽然他们的方法很有希望,但也展示了非单调缺失的困难。相比之下,我们的方法相当直接,即使在 MAR 下也是有效的。从技术角度来看,正如完整数据的情况一样,与核密度估计器相比,贝叶斯密度估计方法还具有能够适应更高平滑度速率的优势,参见例如 (Ghosal 和 van der Vaart, 2017, 第 9 章)。
如上所述,关于正式 MAR 结果的文献稀缺并不完全令人惊讶。正如 Näf 等人 (2026) 详细讨论的那样,假设 2.1 中的 MAR 处理起来相当复杂。特别是,在第 5.1 节中我们证明,即使在三维情况下,当从一种模式切换到另一种模式时,也会出现复杂的分布偏移。这可能是 MAR 条件在一定程度上失宠,转而考虑稳健 MCAR 版本的原因之一 Ma 等人 (2024);Chérif-Abdellatif 和 Näf (2025)。另一方面,鉴于 Rubin (1976);Takai 和 Kano (2013) 的结果,MAR 似乎自然地与似然最大化对齐,特别是与 KL 散度最小化对齐。这在插补背景下的机器学习领域也得到了认可(Mattei 和 Frellsen, 2019; Yu 等人, 2025),尽管严格的统计结果似乎仍然缺乏。
3.2 贡献
在具有完整数据的规则参数模型中,贝叶斯方法的频率学派有效性现已确立。众所周知,当最大似然估计量(MLE)具有一致性和渐近正态性时,在对先验的温和条件下,后验分布通常集中在真实值周围并满足 Bernstein–von Mises (BvM) 定理。这些属性可以非正式地视为一致性和渐近正态性的贝叶斯对应物,确保后验表现得像一个良好的频率学派估计量。然而,在存在缺失数据的情况下,尚不清楚这些属性是否仍然成立。特别是,基于(可忽略)似然的贝叶斯推断在数据未完全观测时是否仍然有效,即使是在 MAR 假设下,仍是一个开放性问题。
在参数模型之外,贝叶斯方法的频率学派验证已通过所谓的先验质量与测试框架得以发展。该方法提供了确保非参数模型中后验集中性的一般条件,并具有可量化的速率。关键要素包括:(a) 真实值的 KL 邻域内具有足够的先验质量;(b) 存在合适的检验;(c) 先验集中在筛法(sieve)上。该理论在标准设置中现已得到充分理解,但其扩展到具有缺失数据的模型在很大程度上仍未被探索。因此,我们这里考虑的问题是,此类一般非参数结果是否可以扩展到仅观测到不完整数据且真实缺失机制为 MAR 的情况。特别是,我们感兴趣的问题是,在这种情况下是否可以恢复完整密度。
一个基本结果断言,在独立同分布(i.i.d.)数据下,且当 ΘΘ 是由 Hellinger 距离度量的概率测度空间时,(b) 中合适检验的存在性得到保证(参见例如,(Ghosal 和 van der Vaart, 2017, 附录 B))。我们表明,有些令人惊讶的是,这在 MAR 缺失和正性条件下仍然成立。我们通过为任何密度组合构建特定检验来实现这一点,灵感来源于 (Ghosal 和 van der Vaart, 2017, 附录 B) 中的思想。此外,由于在我们的框架中,先验和筛法(Sieve)均不因缺失值而改变,(c) 成立当且仅当它在完整数据情况下成立。然而,再次有些令人惊讶的是,KL 邻域中的先验质量在存在缺失值时可能不成立,即使在完整数据情况下成立。因此,虽然 (b) 对于 Hellinger 距离成立,且 (c) 可以通过完整数据进行检查,但 (a) 需要针对缺失数据进行仔细研究。我们表明,尽管如此,在
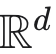
上贝叶斯密度估计的非常一般的情况下,如果真实密度满足 Hölder 条件,(c) 是可以验证的 [注:原文此处为 (c),根据上下文逻辑疑似应为 (a)]。利用 KL 散度、似然性与 MAR 条件之间的联系,我们的一般结果允许推导出一个易于实现的密度估计器,同时达到极小极大收缩率。随后可以从估计的无污染分布中采样,以便在第二步中获得密度的任何连续函数。
因此,我们的贡献有四个方面:
- 我们将一般后验收缩结果扩展到了非单调 MAR 缺失的情况。
- 我们证明,即使在非单调 MAR 缺失下,针对 Hellinger 距离的合适检验始终存在。
- 我们应用这些结果表明,在 Hölder 条件下使用 Dirichlet 先验进行的密度估计,其后验收缩率达到了与估计的极小极大速率相对应(直至对数因子)的水平。
- 我们推导并实现了一种算法以获得该估计,该算法能够接受受缺失值污染的数据,并生成来自无污染分布的样本,这些样本可用于第二步中的任何感兴趣参数。
我们注意到,我们的密度估计应用仅触及表面,因为第 1 点和第 2 点中的结果可能具有更广泛的适用性。
4 MAR 下的后验收缩速率
本节提供了本文的主要结果。我们首先介绍一种适应于缺失数据设置的 Kullback-Leibler 散度的新变体,然后在著名的先验质量与检验框架下陈述一个一般性定理。最后,我们将此结果特化应用于 Hellinger 距离下的估计情形。
4.1 定义
我们首先引入以下 KL 散度的适应性定义:
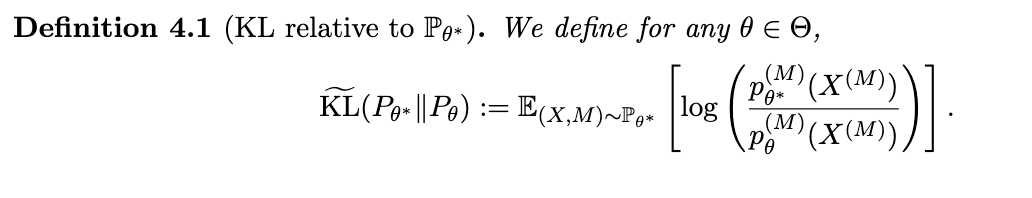


4.2 一般后验收缩结果
我们现在可以表述我们的第二组假设:
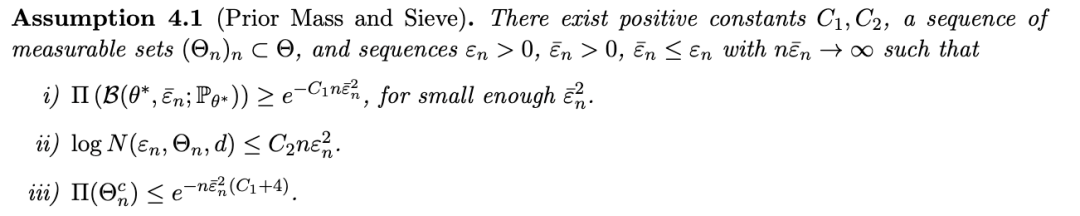

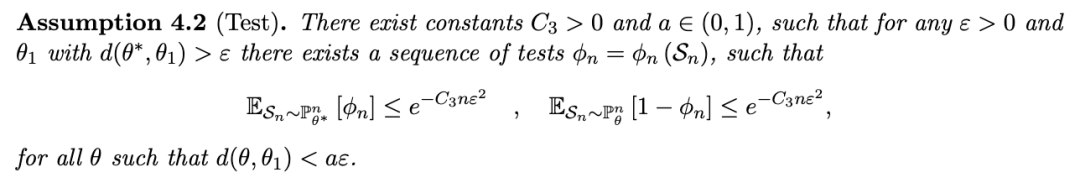
该条件类似于贝叶斯非参数文献中通常的检验假设,其显著区别在于,在标准方法中,检验统计量通常是利用完整数据集构建的,而我们这里仅依赖于不完整的观测数据。在这些假设下,可以建立一个类似于完整数据设置下的收敛速率:
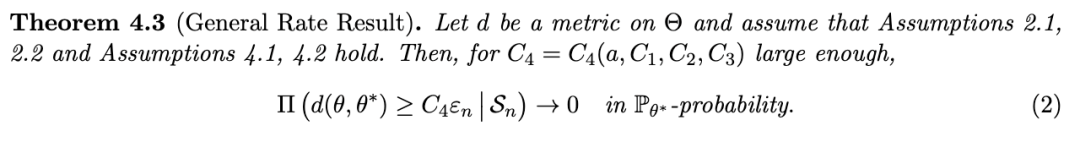

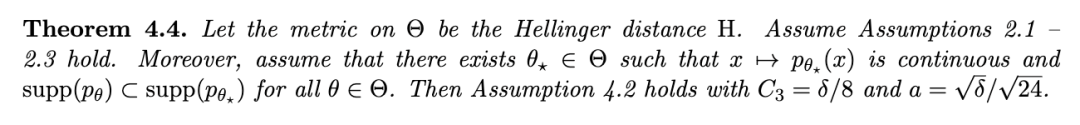

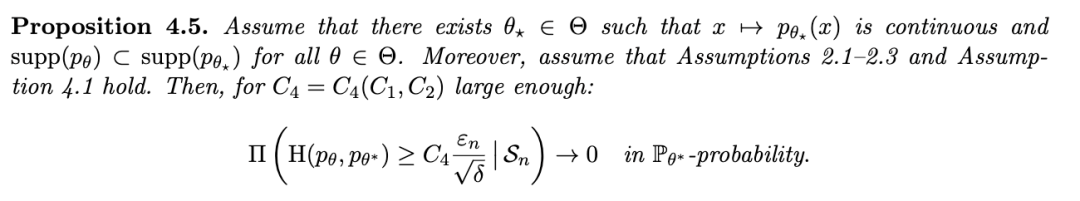

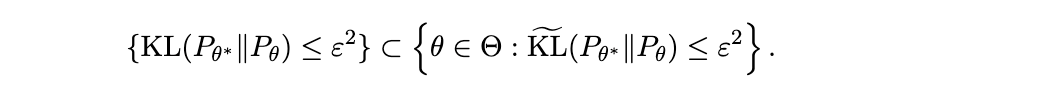
虽然这可能足以证明类似于(Ghosal 和 van der Vaart, 2017,定理 6.23)的 Schwartz 型结果,即证明无任何速率的一致性,但这不足以证明我们此处希望证明的更强结果。原因是完整数据和缺失数据量之间的相同关系对 eV 不成立,因此尚不清楚在完整数据情况下满足先验质量假设是否也意味着在 MAR 缺失下满足假设 4.1 i)。我们现在将这些一般结果应用于
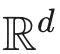
上的密度估计情况。
5 MAR 缺失下的密度估计

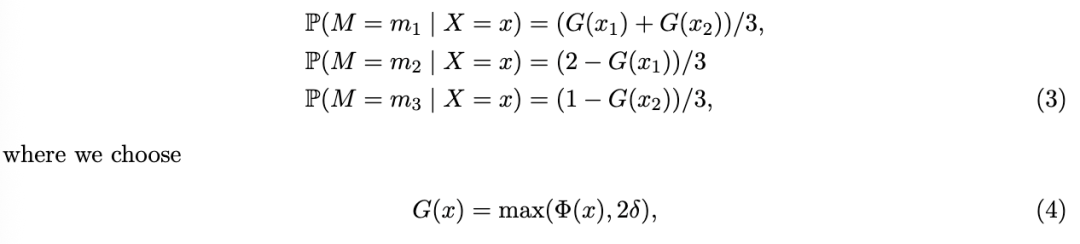



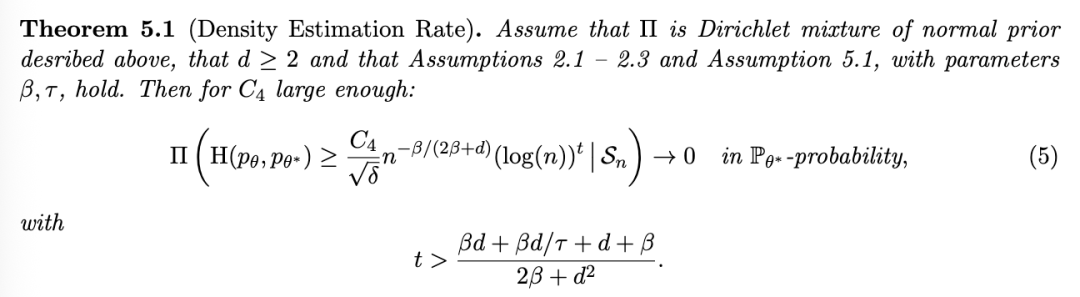

凭借这一有些令人惊讶的结果,我们自然地得到了一种方法,该方法能够接受 MAR 缺失数据,并从先前被缺失性掩盖的(未观测到的)基础分布中生成新样本。另一方面,在第 5.1 节中,处理复杂 MAR 情况的一种方法是尝试使用非参数插补,通过以恢复 XX 的无污染分布的方式填补缺失值。我们的方法与这种方法并行,尽管我们注意到这严格来说并不是一种插补方法,因为它生成的是全新的样本,而不是保持观测样本完整。在插补文献中,这传统上被视为可疑的。例如,在最近的插补基准 Grzesiak 等人 (2025) 中,更改观测数据会导致错误。然而,我们认为我们的方法提供了一个有趣的视角:新方法学允许我们根据需要从估计的未掩码密度中采样任意多的点,并可用于估计任何感兴趣的属性。事实上,最近的论文隐式或显式地论证了插补是一项分布任务,即人们所能希望做到的最好的事情是通过插补恢复原始的未掩码分布。这反映了缺失值通常无法恢复且不应尝试恢复这一事实。正如 Van Buuren (2018, 第 2.6 章) 所述:“插补不是预测”。因此,我们的方法将这一思想向前推进了一步,从未掩码分布中生成全新的样本,承认在大多数应用中我们真正感兴趣的是分布的各个方面,而不是原始样本。
6 模拟研究
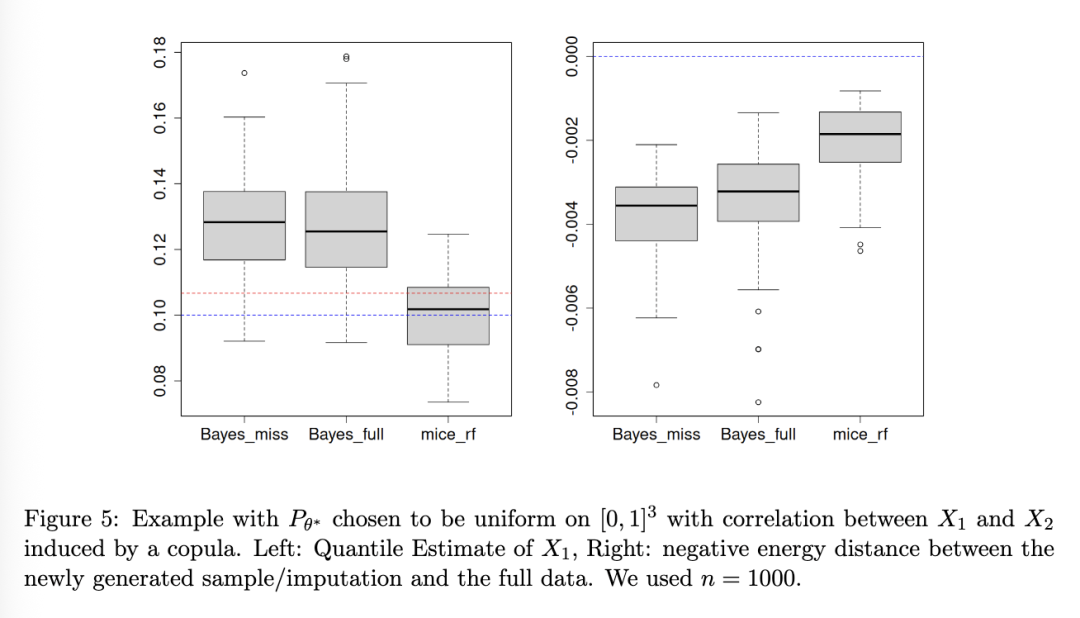
在本节中,我们的目标是实证证明,在算法 1 中实现的带有缺失值的理论算法,其性能与使用完整数据的同一算法大致相同。当然,这不是一个公平的比较,因为完整数据算法比算法 1 能访问更多的数据。尽管如此,相对于 d=3 的维度,我们使用了相对较大的样本量(n∈{500,1000}),这应该能揭示出两者相似的性能。


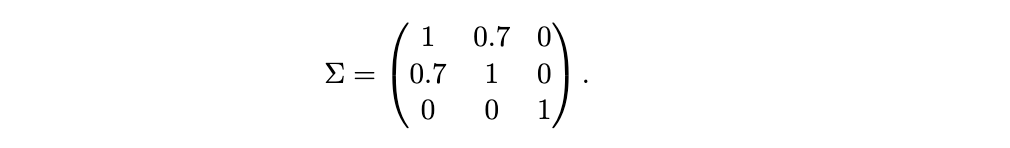

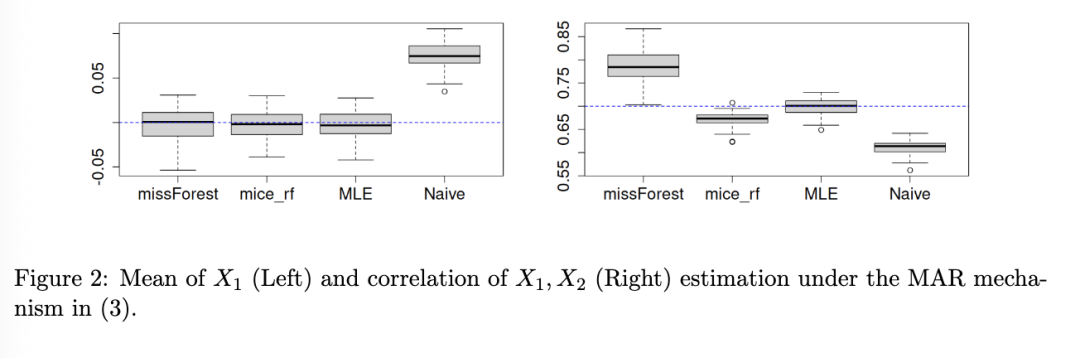
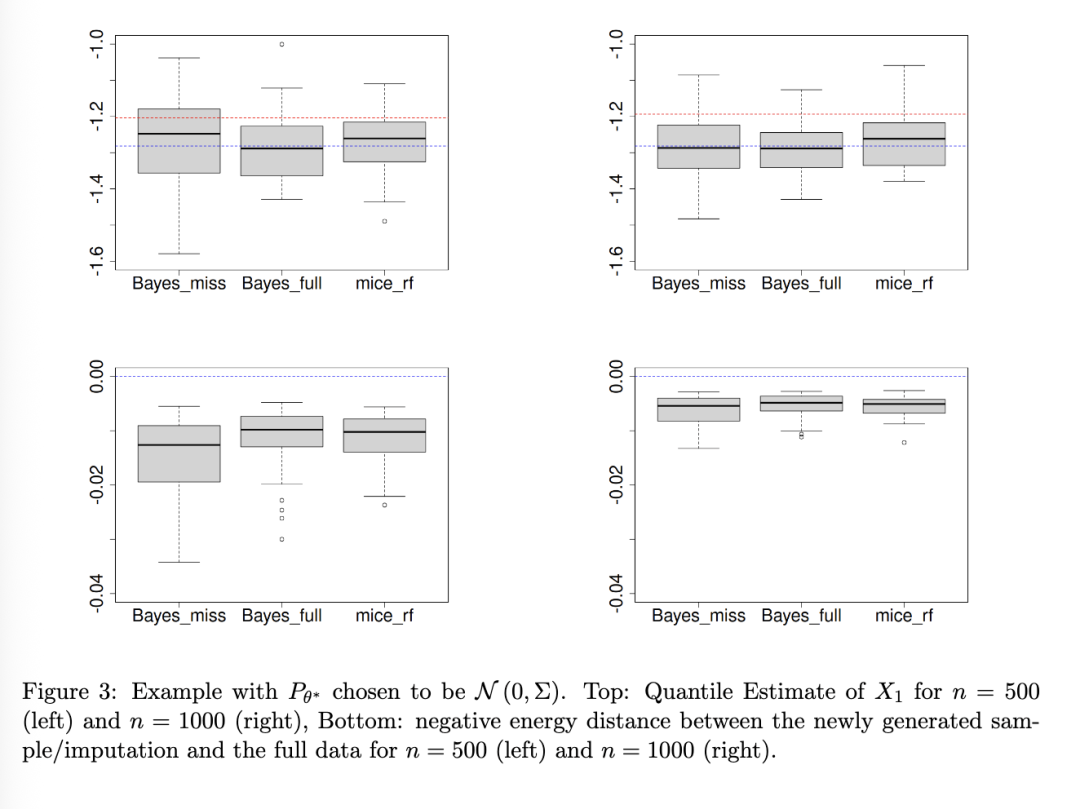
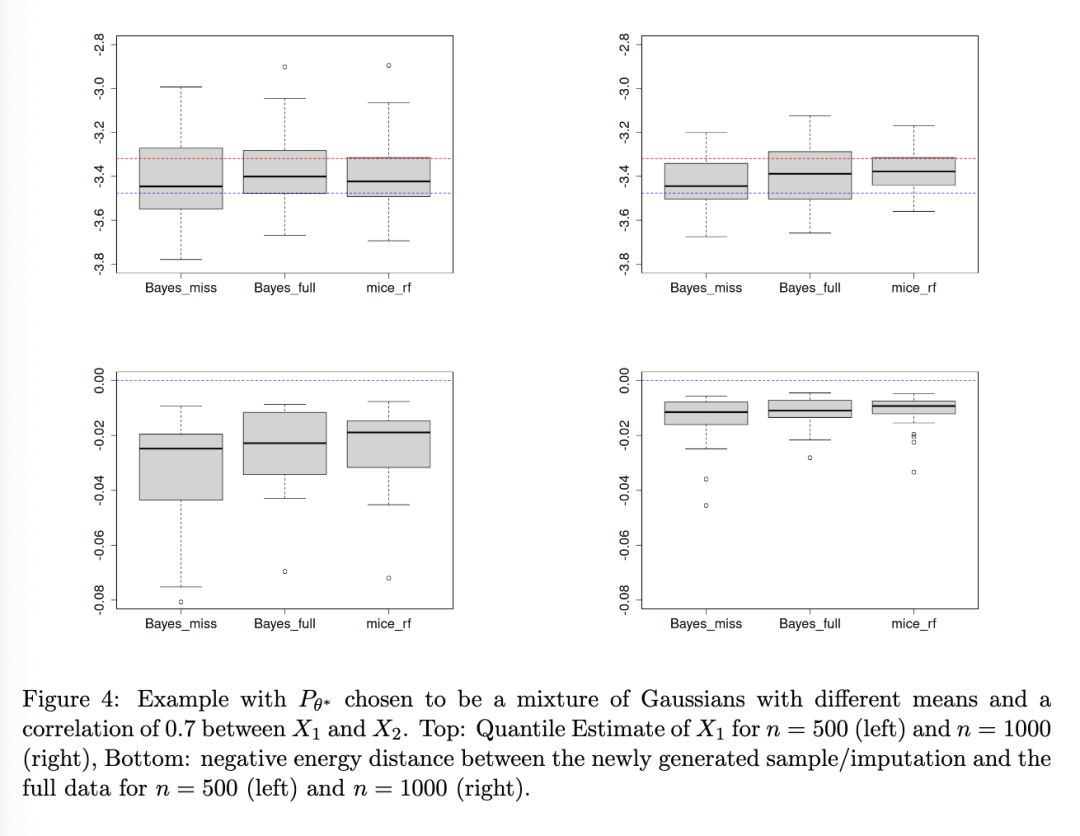
图 3 - 5 展示了结果。由于我们使用正态分布的 Dirichlet 混合,前两个设置对于我们的方法是理想的,尽管我们注意到这仍然与简单地使用参数方法不同。因此,我们的算法表现非常好,无论是在分位数 (1) 的估计方面,还是在能量距离 (2) 方面。特别是,尽管存在棘手的 MAR 机制和信息损失,其性能与能够访问完整数据的算法相当。正如预期的那样,mice_rf 也具有很强的竞争力,尽管它在分位数估计方面有些吃力。另一方面,对于均匀分布示例,正态分布的 Dirichlet 混合自然表现不佳,因为该方法试图用光滑的高斯分布来近似非光滑密度。尽管如此,对于 n=1,000,我们提出的带有缺失值的算法与能够访问完整数据的同一算法的性能再次相当。
7 结论
在这项工作中,我们将贝叶斯后验收缩结果适应于一般非单调 MAR 缺失的情况。我们表明,当向 MAR 添加正性假设时,Hellinger 距离仍然自动满足检验条件,提供了一个可以移除检验条件的结果版本。然后我们将该理论应用于密度估计,给出了在该一般 MAR 条件下看似首个非参数一致性结果。我们还在算法 1 中实现了该方法。
我们相信这项工作仅触及了表面。特别是,定理 4.3 可能比仅用于独立同分布数据下的密度估计具有更广泛的适用性。此外,一个自然的直接问题是是否可以推导出一(半参数)Bernstein-von-Mises 结果。这样的结果将使得能够用多元高斯分布渐近地近似感兴趣参数的后验分布,从而允许在 MAR 缺失值下进行基于原理的不确定性量化。我们打算在后续工作中研究这些问题。最后,虽然提出的密度估计算法在我们的模拟中效果很好,但更灵活的版本在实践中可能会获得更好的结果。例如,针对每种模式变化协方差矩阵 Σ,而不是在所有模式上固定它,可能会提高更复杂数据集的性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号