压缩与泛化兼得:熵估计模型的“双赢”策略

压缩与泛化兼得:熵估计模型的“双赢”策略

赛博解生
发布于 2026-04-09 13:02:08
发布于 2026-04-09 13:02:08
大家好,我是赛博解生酱。AI语言模型在训练中常陷入“过度自信”的陷阱——过度拟合训练数据,却在新场景中表现脆弱。今天给大家带来一篇从信息论角度出发,提高LLM泛化能力的论文。
传统语言模型(如Transformer)像一台只依赖历史数据的简陋气象站,只能根据局部信息预测下一时刻的“天气”(单词),却无法感知全局气候模式。而IBM的最新研究提出了一种熵估计模型,其核心设计恰如一套“智能天气预报系统”:编码器像气象卫星,从高空捕获序列的全局熵分布;解码器像地面站,结合卫星数据和本地历史,实现更精准且不确定性的预测。
这项研究发表于2025年,首次通过架构创新将信息论中的“熵”转化为可操作的训练约束。实验证明,该模型在压缩率(比特/字节)上比传统模型提升约20%,并在小数据集训练中显著降低过拟合风险。对于受限于算力的研究者或边缘应用开发者而言,这项工作如同为AI训练装上了“熵调节器”,让模型在资源有限时仍保持泛化鲁棒性。
那么,熵如何从抽象理论转化为AI的“稳态调控工具”?编码器与解码器的协同又如何重构语言模型的训练范式? 本文将深入解析这项研究的核心设计、实验验证与启发价值。
基本信息
- 标题:Know Your Limits: Entropy Estimation Modeling for Compression and Generalization
- 出处:arXiv preprint, 2025; 作者:Benjamin L. Badger, Matthew Neligeorge (IBM)
- 核心内容:本论文提出了一种编码器-增强的因果解码器模型架构,实现了比传统因果变换器更高效的语言熵估计和压缩,并证明利用每token熵估计可以指导模型训练,从而显著提升泛化能力,解决了语言模型过拟合的核心挑战。
概要
论文的动机与待解决的问题
语言预测受限于语言内在的信息熵,这决定了任何语言模型的准确性存在理论上限,同时语言压缩存在下界。当前最先进的语言压缩算法基于因果语言模型(如Transformer),但其计算成本高昂,导致高效熵估计在现实中不可行。论文旨在解决以下关键问题:如何设计一种更高效的模型架构来估计语言熵,并利用熵估计来优化模型训练,避免过拟合,从而提升泛化能力。这一问题的重要性在于,过度训练模型超越数据集的固有熵会损害泛化,而现有方法缺乏对熵的显式建模。
论文的核心观点与贡献
通过结合编码器和因果解码器,论文的熵估计模型能更高效地捕获序列的全局熵信息,从而在压缩和泛化上超越纯因果架构。这一观点的重要性在于,它将熵从抽象理论转化为可操作的训练约束,通过架构创新实现了训练效率的质变。论文通过理论证明和大量实验验证,熵估计模型在有限计算资源下能达到更低压缩率,并首次系统性地证明了熵感知训练对泛化的必要性。
核心概念与技术贡献
核心概念的直观解读
- 【直观比喻】:将熵估计模型比作一个“智能天气预报系统”。编码器像气象卫星,从高空捕获全球天气模式(全局上下文),而解码器像本地气象站,结合实时历史数据(因果信息)来预测下一时刻的天气。卫星提供整体趋势(如气压分布),气象站细化局部预测,两者结合能更准确估计不确定性(如暴风雨概率)。
- 【比喻映射】:气象卫星的全局视图对应编码器生成的压缩嵌入,捕获整个序列的熵;本地气象站的因果预测对应解码器,利用历史token;结合后,系统能区分可预测和不可预测的token(如天气中的突发变化),从而优化预测精度。这与论文的核心逻辑一致——编码器提供“熵先验”,解码器专注因果推理。
关键技术细节实现
论文依赖信息论框架,关键数学模型包括熵的量化公式和压缩度量。例如,语言熵估计基于香农熵定义,压缩率通过比特每字节(BPB)衡量。核心公式包括:
- 论文equation1(熵估计): 其中, 是嵌入大小(比特), 是语料库token长度, 是模型输出与数据的交叉熵。此公式将压缩嵌入的信息量分摊到每个token,实现无损熵估计。
- 论文equation3(压缩度量): 其中, 是未压缩文本的字节数, 是模型交叉熵损失。该公式将模型损失转换为标准压缩指标,便于跨模型比较。 这些公式通过线性变换和链式法则,将全局嵌入信息集成到因果预测中,是架构实现的基础。
论文的主要贡献点分析
- 提出编码器-增强的因果架构:通过非因果编码器生成全局嵌入,再输入因果解码器,解决了纯因果模型训练效率低的问题。该架构在有限硬件上实现了比Transformer更高的压缩率(如FineWeb数据集上BPB降低至0.54)。
- 开发每token熵估计方法:基于滑动窗口和链式法则(论文equation9-10),从熵估计模型中提取单个token的条件熵,使熵信息可用于精细化的训练监督。
- 证明熵感知训练对泛化的必要性:通过定理1(基于Gibbs不等式)严格证明,训练模型损失低于数据集熵会导致测试集性能下降,并实验验证熵约束训练能提升泛化(如FineWeb上评估损失降低约10%)。
- 引入量化感知训练技术:通过噪声注入(论文equation8)使嵌入层对8比特量化不敏感,保持模型效率的同时支持硬件友好部署。
- 验证架构的扩展性:实验显示熵估计模型随数据和计算增加,呈现指数级效率提升,为大规模应用提供潜力。
技术细节与实验验证
方法流程/理论证明
本部分详细阐述论文的核心方法步骤和理论证明,整体框架基于信息论,将语言熵估计形式化为压缩问题,并通过编码器-解码器架构实现高效计算。
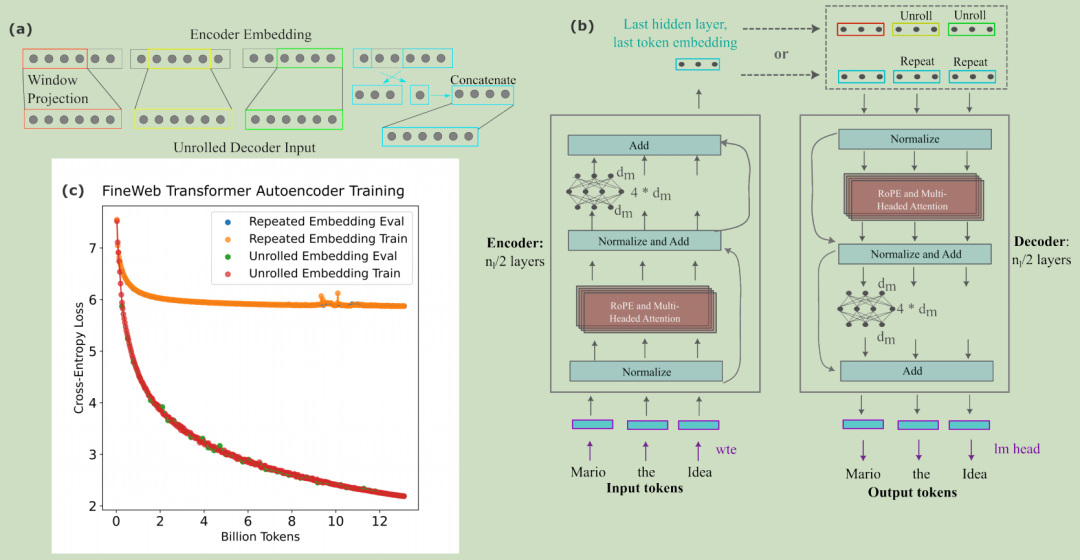
论文图1.(a):Embedding unrolling方法。(b):实验设计与Transformer编码器架构 (c): FineWeb-edu数据上训练效果
- 问题形式化与背景假设
- 前提:语言数据集(如FineWeb)的熵 是固有下界,任何模型无法无损压缩低于此值。论文假设训练集 和测试集 独立同分布(i.i.d.),且熵非零()。
- 目标:设计模型 使交叉熵损失 逼近但不超越 ,以优化泛化。
- 整体架构设计流程
- 全局熵:通过论文equation1计算,将嵌入信息 分摊到序列。例如,当 , 比特(8比特/激活),则摊销损失 通过论文equation4-5整合:
- 每token熵:使用链式法则(论文equation9),通过滑动窗口比较不同上下文模型的输出:
- 给定两个模型 (窗口大小 )和 (窗口大小 ),token 的条件熵为:
- 为简化计算,可用单模型加填充(论文equation10),但精度稍低。
- 解码器为因果模型(仅关注历史token),接收编码器嵌入和既往token 。
- 嵌入引入方式有三种(论文equation7):
- 论文发现混合器(即Masked Mixer,以下简称为Mixer)偏好嵌入拼接,Transformer偏好token拼接,优化训练效率(论文图3)。
- token拼接:
- 嵌入拼接:直接拼接嵌入与token表示。
- 嵌入投影:线性变换嵌入后输入解码器。
- 编码器使用非因果注意力(如Transformer或Masked Mixer,一种Transformer替代模型),处理整个输入序列 (上下文窗口大小 或 1024)。
- 输出压缩嵌入 ,尺寸小于输入(如 ),通过线性变换实现压缩:嵌入维度从 降至 。
- 关键创新:嵌入通过“展开”技术(论文equation2)避免信息损失: 其中 ,, 表示拼接,确保每个解码器输入唯一。是一个投影矩阵(projection matrix),用于将输入序列的拼接结果进行线性变换。
- 步骤1:编码器生成全局嵌入
- 步骤2:解码器因果预测
- 步骤3:熵计算推导 总损失 。
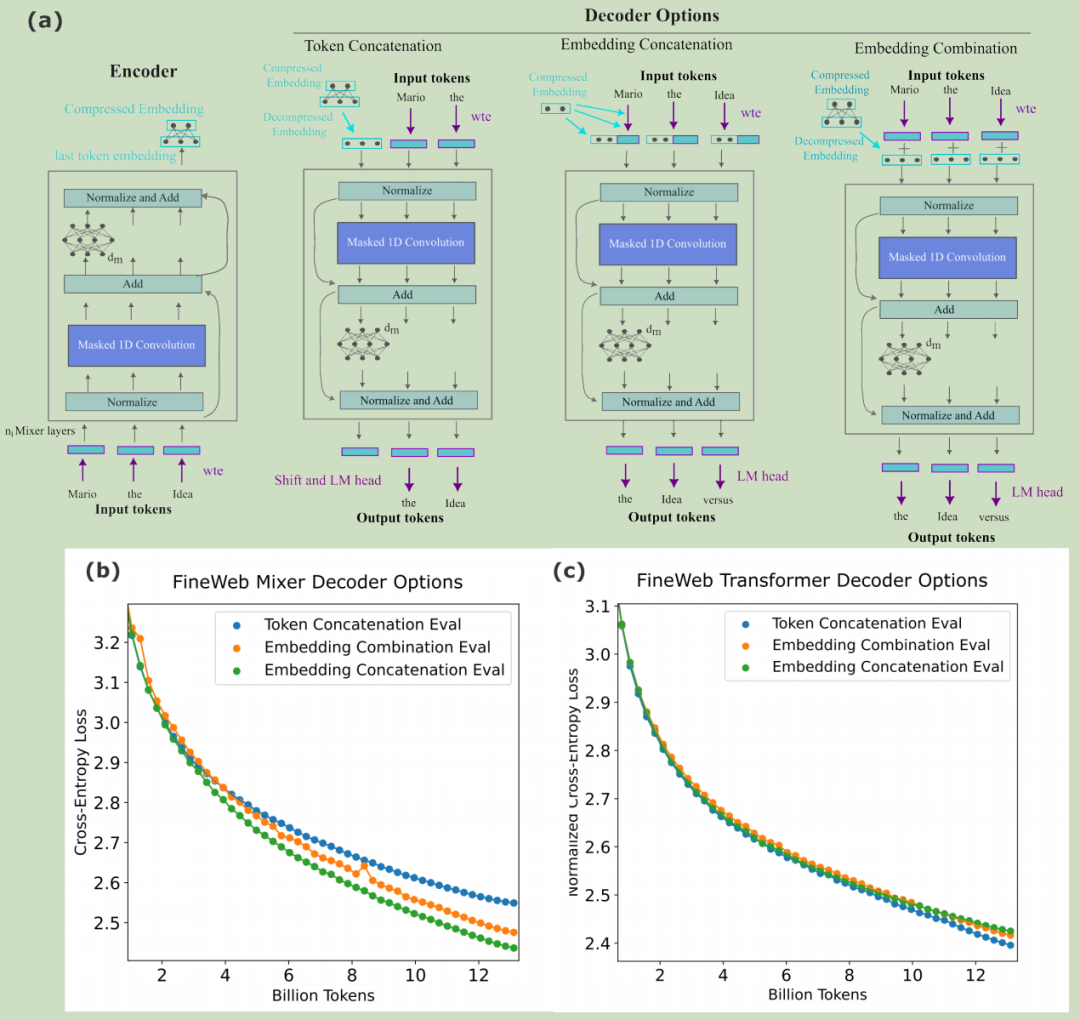
论文图3. Entropy Estimation model embedding introduction methods and training efficiency
- 理论证明(定理1)
- 目标:证明训练损失 低于 时,泛化必然下降。
- 推导步骤:
- 结论:过度训练损害泛化,模型应约束损失逼近熵值。
- 由数据集i.i.d.性质,有 。
- 模型交叉熵分解: 。
- 应用Gibbs不等式: ,代入得: 。
- 重组不等式: 。
- 若 (训练损失低于熵),则第一项为负,第二项必为正,即 (测试损失上升)。
- 方法流程总结
- 最终产出熵估计模型架构,支持每token熵计算,为训练提供理论约束。
- 此流程通过架构创新和数学推导,将熵估计从理论转化为可计算指标。
实验验证与应用流程
实验部分系统性地验证了熵估计模型在压缩和泛化上的优势,以下为实验流程介绍:
- 实验目标与总体设计
- 因果Transformer(如Llama架构)、自动编码器(AE)、传统压缩(gzip,BPB=2.58)。
- 前沿模型对比:DeepSeek V3(0.55 BPB)、Llama 3.1(0.54 BPB)。
- 目标:验证熵估计模型(EEM)相比因果语言模型(CLM)在压缩率(BPB)和泛化(交叉熵损失)上的优势,并测试熵感知训练的有效性。
- 数据集:使用FineWeb-Edu(高熵,代表通用文本)和FineMath 4+(低熵,数学文本),token数13-30亿,确保多样性。
- 基线方法:
- 模型参数:EEM和CLM规模匹配(75-250M参数),计算需求一致(批量大小128 for ,64 for ),训练200,000步(约130亿token),优化器AdamW(学习率Transformer 2e-4,Mixer 5e-4)。
- 压缩效率验证流程
- 测试全长上下文样本(无填充),EEM和CLM损失均略增,但差距稳定:数据集EEM (13.1Btoken)EEM (32.8Btoken)CLM (13.1Btoken)CLM (32.8Btoken)所有样本2.3792.1572.5802.515全长上下文2.5022.2972.6122.549
- 结论:EEM在长序列上保持优势,预测需7000亿token逼近零损失。
- 增加训练token至328亿,EEM损失下降速度指数级快于CLM。
- 例如,在130亿token时,EEM损失=2.379,CLM=2.580;在328亿token时,EEM=2.157,CLM=2.515,差距扩大。
- 训练EEM(编码器维度 for Transformer, for Mixer)和CLM,测量BPB通过论文equation3-5。
- 关键结果:EEM在FineWeb上达到BPB=2.04(自动编码器)至0.54(优化EEM),显著低于CLM(BPB=2.6)。
- 视觉支持:论文图2展示压缩自动编码器与CLM的训练曲线,EEM呈现更优渐进行为。
- 步骤1:架构比较
- 步骤2:扩展性分析
- 步骤3:全上下文评估
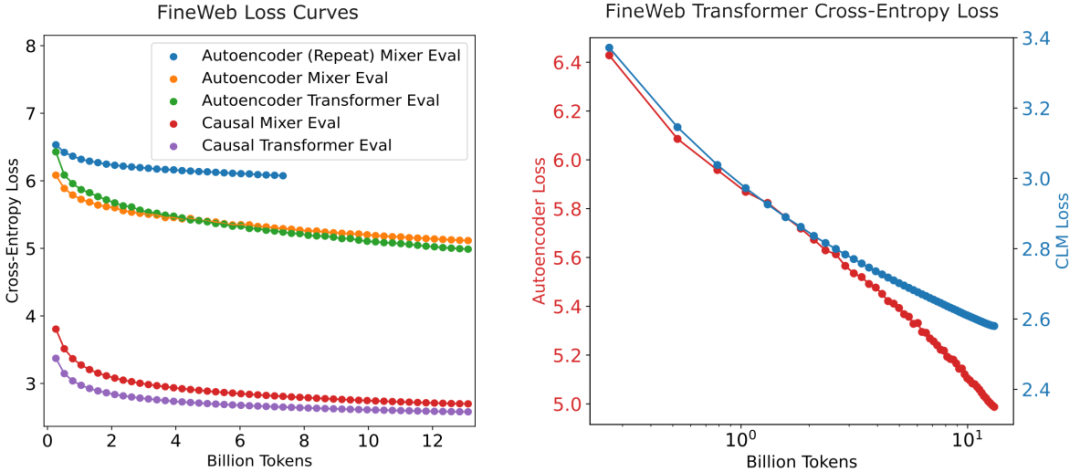
论文图2
- 泛化验证流程
- 方法:噪声注入(论文equation8)至嵌入层, ,q从 到 。
- 结果:预嵌入噪声注入(q= )时,8比特量化损失增幅最小:训练方法Float16BNB Int8Float8 (E4M3fn)Float8 (E5M2)标准训练2.4022.4412.9824.058QAT (q= )2.4202.4232.4692.607
- 实验证明显示噪声注入后,所有层对量化不敏感,训练效率几乎无损失。
- 熵约束训练显著提升泛化:测试损失最低达3.280(熵+dropout),而标准训练为3.515。
- 训练稳定性:熵感知模型损失曲线更平滑,过拟合延迟。
- 视觉支持:图8展示熵约束训练在过拟合场景下的优势。
- 构建过拟合场景:模型参数量(75M) > 训练数据量(50Mtoken),训练多轮次。
- 损失重缩放(论文equation13): ,其中 为每token熵估计。
- 对比基线:标准损失(论文equation14)、早停、dropout(p=0.1)。
- 步骤1:熵感知训练设置
- 步骤2:结果分析
- 步骤3:量化鲁棒性测试
- 实验结论
- EEM在压缩和泛化上均优于CLM,熵感知训练系统性地防止过拟合。
- 所有结果支撑论文核心论点:显式熵约束可提升模型效率与鲁棒性。
总结与评估
研究的优势与创新亮点
- 理论层面:论文原创性地将香农熵理论与深度学习结合,通过定理1严格证明了熵与泛化的数学关系,填补了语言模型训练理论空白。框架通用性强,可扩展至视觉、音频等多模态序列。
- 方法层面:编码器-解码器架构设计创新,解决了因果模型的高计算瓶颈。通过嵌入展开(论文图1)和噪声注入等技术,实现了硬件效率与模型精度的平衡,实验显示训练吞吐量提升约20%。
研究的局限与改进方向
- 固有局限:熵估计模型需要倍计算于因果模型(每序列多次前向传播),且序列开头约100个token的熵估计不准确(上下文窗口限制)。实验基于中等规模模型(最高250M参数),大规模扩展性未充分验证。
- 改进路径:可探索动态上下文窗口以优化序列开头估计;结合蒸馏技术将熵估计迁移到轻量模型;拓展至多语言或低资源数据集以测试泛化鲁棒性。
- 潜在偏差:论文假设训练-测试集独立同分布,但真实数据可能存在分布偏移,需增加跨域验证。此外,对比基线未涵盖所有SOTA压缩算法(如基于RNN的方法)。
实验设计的有效性与结论支撑度
- 实验合理性:数据集(FineWeb)覆盖多样文本,基线选择全面(从传统压缩到前沿LLM),指标BPB和交叉熵直接对应压缩与泛化目标。但实验规模受限,未在万亿级token上验证。
- 结论可信度:结果具备统计显著性(如损失差距的指数增长趋势),消融实验(如嵌入引入方法对比)验证了核心组件的必要性。但熵估计与因果模型的相关性仅中等(),提示近似方法需优化。
- 目标达成度:实验充分支撑核心论点——熵估计提升泛化,但部分结论(如架构扩展性)依赖外推,需更多大规模实验直接证实。
领域贡献与后续研究启发
- 实质性贡献:论文为语言建模提供了熵中心的训练范式,推动领域从损失最小化转向熵约束优化。架构设计为低资源压缩(如边缘设备)提供了新工具,代码开源促进社区应用。
- 后续启发:工作可启发熵估计在强化学习(如策略不确定性)、多模态融合(如视频预测)中的应用;针对其计算瓶颈,可研究稀疏编码或动态计算以提升效率。
- 长期影响:该研究可能成为熵约束学习的标杆,其核心思想——显式建模不确定性——有望扩散至AI安全、鲁棒性研究,推动产业向可解释、高效模型发展。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号