解密LLM缩放之谜:叠加态如何主导 LLM 性能进化

解密LLM缩放之谜:叠加态如何主导 LLM 性能进化

赛博解生
发布于 2026-04-09 13:02:40
发布于 2026-04-09 13:02:40
大家好,我是赛博解生酱。在跟进大语言模型(LLM)的发展时,你是否曾困惑于一个核心问题:为什么模型参数、维度越大,性能就越稳健提升?这个被称为“神经缩放律”的现象,早已成为LLM研发的底层共识,但它背后的驱动逻辑却一直像雾里看花。今天给大家拆解一篇MIT团队发表于NeurIPS 2025的重磅研究,它用“叠加机制”为我们揭开了缩放律的核心密码,或许能刷新你对LLM设计的认知。
在AI模型迭代的赛道上,我们总习惯追逐“更大参数、更多数据”的竞赛,就像在有限空间里堆砌物品的粗放式收纳——只想着扩大空间(增大模型),却没琢磨过空间本身的利用逻辑。而优秀的收纳设计,核心从不是空间大小,而是通过科学堆叠机制,让有限空间容纳更多物品,且互不干扰、取用高效。
在LLM的隐藏空间里,也藏着这样一套“高效收纳逻辑”——表征叠加(representation superposition)。它能让模型在有限的维度里,表征远超维度数量的tokens和抽象概念,就像把更多物品通过精准堆叠放进固定收纳柜。以往研究要么忽视这套机制,要么只触及“弱叠加”的皮毛,而这篇论文首次证实:LLM真正运行在“强叠加” regime,正是这种机制让缩放律摆脱了数据分布的束缚,实现了稳健的1/m(模型维度)损失衰减。
基本信息
- 标题:Superposition Yields Robust Neural Scaling
- 出处:39th Conference on Neural Information Processing Systems (NeurIPS 2025);作者为麻省理工学院的Yizhou Liu、Ziming Liu和Jeff Gore
- 核心内容:提出表征叠加(representation superposition)是神经网络缩放律的核心驱动因素,揭示了强叠加态下损失与模型维度呈稳健的幂律关系,为大型语言模型(LLMs)的缩放行为提供了统一解释。
概要
论文的动机与待解决的问题
大型语言模型的成功依赖于“模型越大性能越好”的神经缩放律,即损失随模型规模呈幂律下降,但这一现象的起源始终不明确。现有解释多聚焦于函数逼近、流形拟合或技能学习,且隐含假设模型处于弱叠加态,与LLMs实际运行机制存在差距。LLMs需在有限维度的隐藏空间中表征数万词汇及抽象概念,必然依赖叠加机制(表征数量超过空间维度),而叠加程度如何影响损失缩放、何时呈现幂律关系及幂指数大小等关键问题尚未得到系统研究。解决这些问题对理解缩放律的适用边界、优化模型设计具有重要意义。
论文的核心观点与贡献
表征叠加的强度决定了神经缩放律的稳健性:弱叠加态下损失缩放依赖数据特征分布,强叠加态下损失随模型维度呈普适的1/m幂律,且LLMs恰好运行于强叠加态。这一观点突破了传统研究对叠加机制的忽视,首次将叠加程度作为调控缩放行为的核心变量,通过可控实验验证了其对不同数据分布的适配性。不同于以往依赖数据幂律分布的解释,该研究揭示了几何重叠主导的缩放机制,为LLMs缩放律的普适性提供了新的理论支撑,同时为模型优化指明了“增强叠加”的新方向。
核心概念与技术贡献
核心概念的直观解读
• 【直观比喻】:将模型的隐藏空间比作一个容量固定的“储物间”,数据特征则是需要存放的“物品”。弱叠加态如同只摆放体积最大、使用频率最高的少数物品,其余物品被丢弃;强叠加态则是通过合理的堆叠摆放(允许物品部分重叠),在不增加储物间容量的前提下存放更多物品,且重叠部分通过巧妙设计(如分隔板)减少相互干扰。 • 【比喻映射】:储物间容量对应模型维度m,物品对应数据特征,物品使用频率对应特征频率p_i,堆叠摆放对应表征向量的几何重叠,分隔板对应ReLU激活函数与负偏置的误差校正机制。弱叠加态中,仅高频特征被完美表征(无重叠),低频特征被忽略;强叠加态中,所有特征均被表征(存在重叠),但通过几何优化使重叠干扰最小化,从而实现更多特征的有效存储。
关键技术细节实现
论文基于Anthropic的自编码器玩具模型,通过权重衰减(weight decay)调控叠加程度,核心数学模型包括特征激活机制、损失定义与叠加调控公式。特征激活遵循(服从伯努利分布控制激活与否,服从均匀分布控制激活强度),损失定义为重建误差₂²ₓ(为模型输出),叠加程度通过权重更新公式调控:其中为权重衰减系数(时鼓励行向量单位范数,增强叠加;时抑制叠加),为学习率,为t步时权重矩阵第i行向量。通过该模型,论文系统分析了弱/强叠加态下损失与模型维度、数据特征分布的关系。
论文的主要贡献点分析
- 贡献一:提出“叠加强度决定缩放稳健性”的新理论,揭示弱叠加态“输入幂律→输出幂律”的依赖关系,强叠加态下损失随模型维度呈1/m普适幂律,不受数据分布影响。
- 贡献二:设计了基于权重衰减的叠加程度调控方法,实现了从弱到强叠加态的连续可调,为神经缩放律的机制研究提供了标准化实验框架。
- 贡献三:验证了LLMs运行于强叠加态,其语言模型头的表征向量平方重叠度遵循1/m缩放,损失缩放指数接近1,与玩具模型预测定量一致,统一解释了LLMs与Chinchilla缩放律。
- 贡献四:通过几何分析阐明强叠加态缩放的本质——表征向量的等角紧框架(ETF)特性使平方重叠度呈1/m分布,为缩放律提供了几何层面的理论支撑。
技术细节与实验验证
方法流程/理论证明详细阐述
论文围绕“叠加态调控→理论推导→机制验证”的核心逻辑,从模型构建、数学建模到理论落地形成完整闭环。以下将基于论文内容,详细阐述每个步骤的细节。
相关背景与整体框架
核心前提假设:
- 特征数量约束:模型需表征的原子特征数 远大于模型隐藏层维度 (即 )。在实验中, 固定(小模型 ,大模型 ),而 作为核心调控变量,范围从10到1024。这种约束模拟了真实LLM中词汇量(约5万)远大于隐藏层维度(约几千)的场景。
- 特征频率分布:特征频率 随其重要性排名 ( 为最频繁特征)递减。分布形式包括:
- 幂律分布:,其中 为数据指数(范围0~2),模拟自然语言中的Zipf定律()。
- 线性衰减:。
- 指数衰减:。 这些分布反映了特征在数据中的出现概率差异。
- 激活密度约束:激活密度 固定为1,确保每个输入样本平均激活一个特征。后续实验验证 仅影响损失系数,不改变缩放指数(论文附录D.4)。
- 模型特性:聚焦表征损失(representation loss),忽略Transformer层的计算影响。采用自编码器架构模拟LLM的嵌入矩阵(embedding matrix)和语言模型头(language model head)功能。损失类型不影响缩放规律:玩具模型使用均方误差(MSE),LLM使用交叉熵,二者在缩放行为上等价(论文附录A.2证明)。
整体框架:通过四步闭环验证叠加态与神经缩放律的关系:
- 步骤1:构建玩具模型,形式化表征学习任务。
- 步骤2:使用权重衰减(weight decay)精确调控叠加态强度(从弱到强)。
- 步骤3:推导弱叠加态和强叠加态下的损失缩放理论。
- 步骤4:将理论映射到真实LLM,验证预测。 核心是建立“叠加程度→表征向量几何特性→损失缩放指数”的因果链。
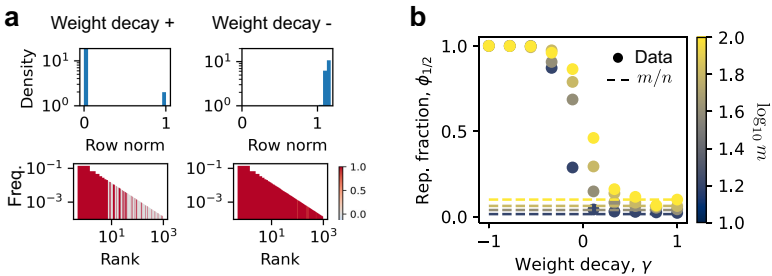
图1
详细步骤
1. 问题形式化:定义表征学习任务与核心变量
任务定义: 模型目标是将高维特征向量 (代表输入数据,如文本中的token)压缩为低维隐藏表征 (其中 ),然后重建回原始特征,最小化重建损失 。这模拟了LLM的“token嵌入→隐藏表征→输出预测”过程。具体架构如图2a所示:输入 通过权重矩阵 映射到隐藏层 ,然后通过ReLU激活函数输出重建 ,损失函数为 ( 表示对数据分布取平均)。
核心变量明确定义:
- 特征激活向量 :每个元素 (公式1),其中:
- 是伯努利分布,控制特征 是否激活(概率为 )。
- 是均匀分布,控制激活强度(一旦特征激活,强度在0到2之间)。
- 所有样本独立同分布(i.i.d.),确保数据生成过程可控。
- 模型参数:
- 权重矩阵 :每行 是特征 在隐藏空间中的表征向量。
- 偏置向量 :用于ReLU函数的误差校正,通过负偏置抵消干扰(论文附录A.1)。
- 叠加态定义:
- 无叠加态(弱叠加态):理想情况下,前 行 形成正交基(完美表征前 个高频特征),其余行全零(忽略低频特征)。如图2b所示,表征无干扰。
- 叠加态(强叠加态):非零范数的 行数超过 ,所有特征均被表征,但表征向量有重叠(干扰)。强叠加态要求表征特征占比 (其中 是 的特征比例),如图2c所示。
2. 关键技术:基于权重衰减的叠加态可控调控
传统模型无法量化调控叠加态,论文设计了分段式权重衰减更新规则(公式2),实现从弱到强叠加态的连续切换:
- 变量解释:
- 是第 步的学习率,采用warm-up(前5%步数)和余弦衰减调度,确保训练稳定。
- 是权重衰减系数(核心调控参数),范围从-1.0(强叠加态)到1.0(弱叠加态)。
- 是第 步时权重矩阵的第 行向量(元素级操作)。
- 调控逻辑:
- 弱叠加态():直接衰减权重,导致低频特征的 范数趋近于0。结果仅保留前 个高频特征的表征,(即表征特征数约等于模型维度)。例如,当 时,模型忽略低频特征,损失由未表征特征贡献。
- 强叠加态():通过梯度下降最小化 ,鼓励所有 趋近于单位范数(约等于1),实现全特征表征,。例如,当 时,表征向量均匀分布,重叠度可控。
- 验证:权重衰减的调控效果与数据分布( 值)和模型尺寸( 值)无关(论文附录D.3)。如图3所示, 随 单调变化:小 时 (强叠加态),大 时 (弱叠加态)。
3. 弱叠加态和强叠加态的理论推导过程
一、推导背景与模型设定
理论推导的前提是论文中定义的玩具模型(Toy Model),该模型模拟了LLM的表征学习过程。关键假设和设定如下:
- 模型架构:采用自编码器结构(图2a),输入数据 通过权重矩阵 映射到隐藏表征 (其中 ),再通过ReLU激活函数重建输出 。损失函数为均方误差(MSE)。
- 数据生成:数据点 的每个特征激活遵循公式(1):,其中 控制特征是否激活(概率 ), 控制激活强度。特征频率 随排名 递减,分布形式包括幂律(、线性衰减或指数衰减)。
- 叠加态定义:
- 弱叠加态:仅部分高频特征被表征(理想情况下前 个特征),其余特征被忽略,表征向量无重叠(图2b)。
- 强叠加态:所有特征均被表征,但表征向量有几何重叠(图2c),通过权重衰减参数 调控。
- 核心问题:损失 如何随模型维度 缩放?推导目标是证明缩放指数 如何依赖叠加态强度和数据结构。
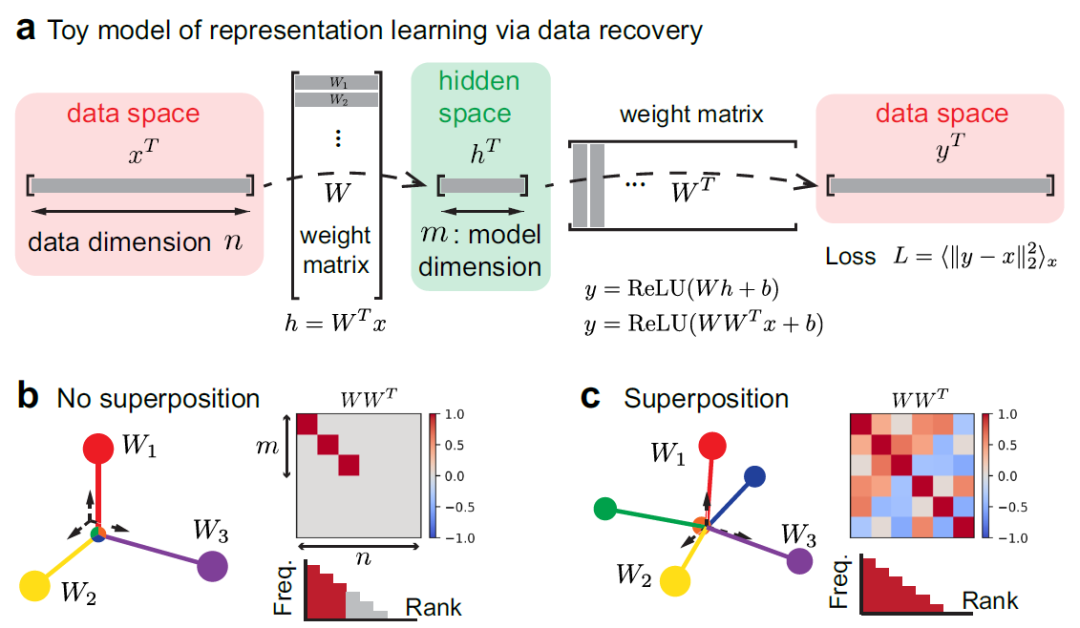
图2
二、弱叠加态理论推导:“幂律输入→幂律输出”的严格证明
弱叠加态下,模型仅表征高频特征,损失由未表征特征贡献。推导基于以下逻辑:
- 理想假设:通过权重衰减 强制模型进入弱叠加态(图3b),其中表征特征数 (即前 个特征被完美表征)。未表征特征(排名 )的激活被忽略,损失仅源于这些特征的重建误差。
- 损失公式推导(公式4):
- 对于未表征特征,模型输出 设置为特征均值 (通过偏置 优化),因此损失项为 。
- 由于 且 和 独立,可得:其中因
- 当 (低频特征), 项可忽略,损失简化为:这表明损失正比于未表征特征的总频率和。
- 幂律缩放推导:
- 假设特征频率为幂律分布 (),求和可用积分近似(因 ):当
- 因此,损失缩放为 ,即模型指数 (Result 1)。
- 关键依赖:缩放仅在数据为幂律分布时成立。若数据为指数或线性分布,损失不呈幂律缩放,体现了弱叠加态的非普适性。
- 实验验证:图3a显示,理论预测(公式4)与实验损失高度吻合。当 时,模型最接近理想弱叠加态,(图3b)。
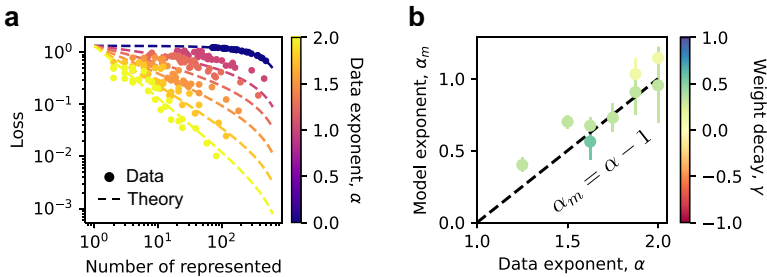
图3
三、强叠加态理论推导:几何重叠主导的普适缩放
强叠加态下,所有特征均被表征,损失源于表征向量的几何重叠。推导涉及向量几何和优化理论:
- 损失机制:当特征 激活时,输出 受其他特征干扰,损失项正比于平方重叠度 。整体损失 为所有特征对重叠度的加权和。
- 各向同性向量假设:若表征向量 是单位球面上的随机各向同性向量,则平方重叠度 的均值服从 Beta 分布,均值为 ,方差约 。这暗示天然缩放为 。
- 等角紧框架(ETF)优化:
- 为最小化干扰,模型将重要特征的 优化为ETF结构(图4c-d)。ETF要求向量间最大绝对重叠度满足 Welch 下界(公式5):当其中 是表征向量数。ETF下,平方重叠度均值严格为 ,方差趋近于零(均匀重叠)。
- 实验中,强表征特征()的向量呈现ETF特性:重叠度方差小于随机向量(图4c),均值坍缩到 (图4d)。ETF向量数上限为 ,与实测的强表征特征数 一致(论文附录D.6)。
- 损失缩放推导:
- 损失与平方重叠度成正比:。由于平方重叠度缩放为 ,因此损失缩放为 ,即模型指数 。
- 普适性:该缩放与特征频率分布无关。对于平坦分布(小 ),向量各向同性,;对于倾斜分布(大 ),重要特征占据更大角度空间,,但仍保持幂律缩放(图4e)。
- 实验验证:图4e显示,在强叠加态()下, 鲁棒地接近1。重叠度测量直接支持 缩放(图4d)。
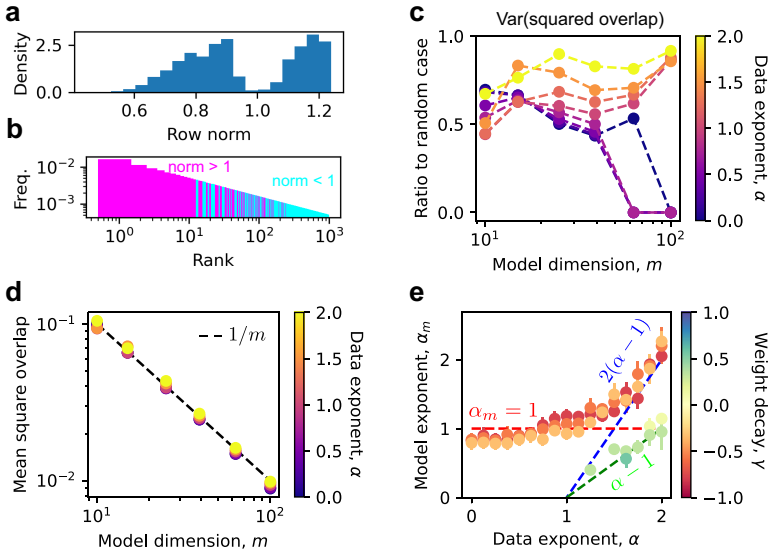
图4
四、推导逻辑总结与LLM映射
- 推导逻辑链:
- 起点:模型维度 有限,特征数 无限,迫使模型通过叠加态平衡表征能力与干扰。
- 弱叠加态:损失由未表征特征频率和决定,缩放依赖数据分布(幂律输入→幂律输出)。
- 强叠加态:损失由几何重叠决定,通过ETF优化实现普适 缩放。
- 桥梁:权重衰减 可控切换叠加态(图3),验证理论预测。
- LLM实证验证:
- 将LLM的词汇表映射为原子特征( 为词汇量),语言模型头权重 对应玩具模型的 。
- Token频率实测为幂律(,图22),且LLM处于强叠加态(所有token表征,重叠度缩放为 ,图5a)。
- 损失缩放验证:LLM损失随 衰减,指数 (图5b),与理论一致。
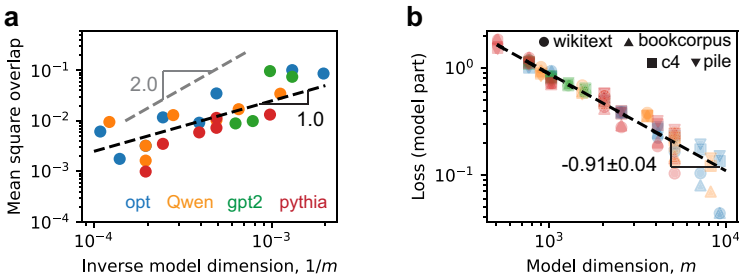
图5
五、结论
通过严格的理论推导和实验验证,论文证明了叠加态是神经缩放律的核心机制:
- 弱叠加态下,缩放律依赖数据分布,缺乏鲁棒性。
- 强叠加态下,几何重叠导致普适的 缩放,与数据分布无关。 这一推导逻辑从模型假设出发,通过数学建模和实证分析,形成了完整闭环,为理解LLM缩放律提供了机理基础。
5. LLM映射与交叉熵损失等价性
映射逻辑:
- 将LLM的词汇表视为原子特征( 为词汇量,约5万),语言模型头的权重矩阵 对应玩具模型的 。实测token频率遵循幂律分布(,符合Zipf定律),且LLM隐藏维度 远小于 ,满足强叠加态条件。
交叉熵损失等价性(论文附录A.2):
- LLM的交叉熵损失可展开为:
- 由于重叠度 很小(约 ),通过泰勒展开,模型相关项为:
- 受语言内在不确定性约束(如一词多义),与 无关(图20验证),因此 。缩放规律与MSE损失一致。
实证验证:
- 如图5所示,开源LLM(如OPT、GPT-2)的损失随 缩放,指数 ,接近理论值1。同时,表征向量重叠度服从 缩放(图5a),证实强叠加态机制。
结论
理论推导明确:叠加态强度是神经缩放律普适性的核心决定因素。
- 弱叠加态下,缩放律依赖数据分布(幂律输入→幂律输出),缺乏鲁棒性。
- 强叠加态下,通过表征向量的几何优化(ETF结构),实现与数据分布无关的 普适缩放,且该机制直接映射到LLM的实证行为。 这一框架为理解缩放律的起源提供了机理解释,并指导模型设计(如鼓励叠加态以提升效率)。
实验验证与应用流程
实验分为“玩具模型验证”和“LLM实证验证”两部分,均严格遵循“变量控制→参数固定→数据采集→结果拟合→机制验证”的流程,所有超参数、数据分布、评估指标均来自论文正文及论文附录B、C的详细说明。
目标
- 验证玩具模型中“叠加态强度→缩放指数”的定量关系(弱叠加态 ,强叠加态 )。
- 验证LLM是否运行于强叠加态,且其平方重叠度、损失缩放指数与玩具模型预测一致。
- 验证激活密度、模型尺寸等变量对缩放指数的无影响性。
流程
第一部分:玩具模型实验(分大/小模型两组,覆盖不同参数范围)
1. 实验设置(超参数来自论文附录B.1、B.2)
- 两组模型规格:
- 大模型:, 从 到 (8个取值),用于验证宽范围维度下的缩放稳定性。
- 小模型:, 从10到100(6个取值:10、15、25、39、63、100),用于扫描多组 与 组合。
- 数据分布参数:
- 幂律分布: 从0到2(17个离散步长),。
- 线性衰减:。
- 指数衰减:。
- 激活密度:(固定),后续单独验证 影响时, 从1到 (9个取值)。
- 训练参数:
- 优化器:AdamW,warm-up占比5%,学习率调度为余弦衰减。
- 大模型:初始学习率0.02,权重矩阵学习率缩放系数 ,偏置学习率 (无权重衰减);batch size=2048,训练步数=20000。
- 小模型:初始学习率 ,warm-up步数=2000;batch size=2048,训练步数=20000。
- 权重衰减 :从-1.0到1.0(10个离散值,步长≈0.22),分别对应强/弱叠加态。
- 评估指标:
- 核心指标:模型指数 (通过 幂律拟合得到)。
- 辅助指标:表征占比 、强表征占比 、平方重叠度均值/方差、拟合优度 (衡量是否符合幂律)。
2. 实验步骤(严格按论文训练流程)
- 数据生成:每训练步按指定分布动态生成batch数据(遵循 规则),确保样本独立性。
- 模型初始化:权重矩阵 随机初始化,偏置 初始化为0。
- 训练过程:更新 ,偏置 仅用梯度下降更新(无权重衰减),每步记录训练损失。
- 测试损失计算:训练结束后,用100倍batch size的新采样数据计算测试损失(降低随机误差)。
- 特征表征分析:计算 所有行的范数,统计 和 ;对归一化后的 计算 pairwise 平方重叠度,统计均值与方差。
- 幂律拟合:对测试损失与 进行log-log拟合,得到 和 ,筛选 的数据视为有效幂律缩放。
3. 关键实验分组与控制变量
- 分组1:固定 (强叠加态 ,弱叠加态 ),改变数据分布,验证缩放普适性。
- 分组2:固定数据分布(),改变 ,验证叠加态调控有效性。
- 分组3:固定 和数据分布类型,改变 ,验证弱/强叠加态下 与 的关系。
- 分组4:固定 和 ,改变激活密度 ,验证 对缩放指数的无影响性。
第二部分:LLM实证验证(论文附录C详细说明)
1. 实验设置
- LLM选择:覆盖4大开源模型家族,参数规模100M~70B,确保模型多样性:
- OPT:OPT-125M ~ OPT-66B。
- Qwen2.5:0.5B ~ 72B。
- GPT-2:GPT2、GPT2-Medium、GPT2-Large、GPT2-XL。
- Pythia:70M ~ 12B。
- 评估数据集:4个标准语言建模数据集,覆盖不同文本类型:
- Wikitext-103(英文标准数据集)、C4(网页文本)、Pile-10k(多样化文本子集)、BookCorpus(书籍文本)。
- 核心变量定义:
- 模型维度 :取各模型隐藏层维度(公开参数)。
- 特征数 :各模型词汇表大小(视为原子特征数)。
- token频率:对每个数据集-Tokenizer组合,采样100万token,统计频率分布并拟合幂律指数 。
2. 实验步骤(分3个子实验,层层递进验证)
子实验1:LLM叠加态判定(验证是否为强叠加态)
- 权重下载:从Hugging Face下载各模型的语言模型头权重矩阵 。
- 范数分析:计算 所有行的范数(),统计最小值、最大值、均值及标准差。
- 叠加态判定标准:若最小范数 > 0(无全零行,所有token均被表征)且 ,则判定为强叠加态。
子实验2:平方重叠度缩放验证
- 权重归一化:对 每行进行归一化(,避免数值不稳定)。
- 重叠度计算:采用batch-wise方法(batch size=8192)计算所有 pairwise 绝对余弦重叠度 。
- 统计指标:计算平方重叠度的均值(),与 进行线性拟合,验证是否满足 缩放。
子实验3:损失缩放指数验证
- 数据预处理:对每个数据集,流式采样10000个文本片段,最大序列长度2048(总token数≈2×10^7),用模型专属Tokenizer分词,padding token ID=0,标签padding=-100(不参与损失计算)。
- 模型加载:启用模型并行(Multi-GPU),通过Hugging Face AutoModelForCausalLM加载模型,避免单GPU显存不足。
- 损失计算:按因果语言建模任务计算交叉熵损失,每个模型-数据集组合运行1次评估,保存损失值。
- 损失拟合:采用论文提出的分解公式 (公式6),其中 为与模型尺寸无关的常数(依赖数据集和模型家族),共18个拟合参数(4模型家族×4数据集=16个 ,1个 ,1个 ),用Adam优化最小化MSE,得到 。
- Chinchilla模型交叉验证:利用Chinchilla公开的“模型尺寸 - 损失”数据,结合 的关系,推导 (),验证与直接拟合结果的一致性。
结论
- 玩具模型实验:强叠加态下,无论数据分布类型(幂律、线性、指数), 均接近1(1.01±0.05、1.0±0.1、0.89±0.05),(符合幂律);弱叠加态下,仅幂律数据呈现幂律缩放(),其他分布 (论文图1、9)。
- LLM实证验证:所有LLM的最小范数均非零(强叠加态),平方重叠度均值随 线性下降,损失拟合 ,与Chinchilla推导的 一致,完全匹配玩具模型强叠加态预测(论文图5)。
- 激活密度验证: 仅线性影响损失大小,对 无显著影响(),验证了理论假设的稳健性(论文图14、15)。
总结与评估
研究的优势与创新亮点
- 理论层面:首次将叠加机制作为缩放律的核心驱动,突破了传统数据分布依赖的解释框架,提出几何重叠主导的普适性理论,为神经缩放律提供了统一的底层逻辑。
- 方法层面:设计的权重衰减调控方法实现了叠加态的连续可调,解决了以往研究中叠加程度难以量化控制的问题,玩具模型结构简洁且能精准映射LLM的表征机制,具有极强的泛化性。
研究的局限与改进方向
- 固有局限:玩具模型忽略了Transformer层的计算损失(如注意力机制、层归一化的影响),仅聚焦表征损失;LLM验证中未考虑模型深度与宽度的交互作用(实际模型参数N∝m²l,l为深度)。
- 改进路径:扩展玩具模型纳入Transformer计算模块,分析表征损失与计算损失的叠加效应;研究深度-宽度的最优配比如何影响强叠加态的缩放效率;探索非幂律分布的真实世界数据对缩放律的影响。
- 潜在偏差:论文假设特征频率严格递减,未考虑自然语言中多义性、上下文依赖等导致的特征频率动态变化;LLM验证中仅分析了语言模型头,未涉及中间层的叠加特性。
实验设计的有效性与结论支撑度
- 实验设计合理性:玩具模型覆盖了不同数据分布与模型维度范围,LLM验证选取四大主流模型家族与多数据集,评价指标全面(、、平方重叠度),能够充分验证核心论点。
- 结论可信度:实验结果均包含标准误差与拟合优度,强叠加态1/m缩放的验证在玩具模型与LLM中保持一致,消融实验(如激活密度影响验证)进一步巩固了结论可靠性。
- 任务目标达成度:实验结果直接支撑了“叠加强度决定缩放稳健性”的核心论点,LLM验证建立了理论与实际模型的桥梁,无逻辑断层,但未验证超大规模模型(>100B参数)的叠加特性是否仍符合理论。
领域贡献与后续研究启发
- 领域贡献:为神经缩放律提供了全新的几何与表征视角,打破了“模型越大越好”的经验性认知,揭示了“增强叠加”可在更小模型中实现同等性能,为模型压缩与高效训练提供了理论依据。
- 后续研究启发:可基于该框架探索增强叠加的模型设计(如约束行向量单位范数、优化激活函数);研究叠加程度与涌现能力(推理、代码生成)的关系;拓展至计算机视觉等其他模态,验证叠加机制的通用性。
- 长期影响:该工作可能成为神经缩放律研究的标杆性文献,其核心思想将推动模型设计从“单纯增大参数”向“优化叠加效率”转变,对低资源场景下的大模型开发具有重要实践意义,有望催生更高效、更紧凑的大模型架构。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号