孙哥的中转站AI也"降智"?孙哥成孙割


最近圈子里大家都在疯狂卷 AI 赋能安全,各种 Autonomous Agents 和自动化攻击链验证的方案层出不穷。为了追求更强大的推理逻辑和代码分析能力,我们平时没少追踪和测试各大厂商的最新高阶模型。
但在国内,很多朋友为了方便,会选择使用各种第三方"API 中转站"。今天就用几个真实的踩坑经历,给大家实战演示一下:如何用安全审计的直觉,扒掉那些无良套壳中转站的底裤。
而且这次的主角,不仅有割韭菜出名的孙哥(孙宇晨)的 b.ai,还有我自家项目上的血泪教训。

🚨 案发现场:这AI怎么突然"降智"了?
最近我在死磕移动端渗透和复杂链路的自动化 Hook,听说 孙哥的 b.ai 上线了 Gemini 3.1 Pro,心里一喜。
毕竟人家 Plan Max 要 2000/月(约 ¥14000+),Plan Pro 也要 200/月(约 ¥1400+),这价格都赶上 OpenAI 官方 Plus 的年费了,模型质量应该很能打吧?
我马上切过去打算测试一下它对本地 RAG 架构和高级内存分配的理解。
结果没聊几句,强烈的"违和感"就来了。它的回答充满了浓浓的"早期模型味"——遇到复杂的渗透场景就开始给我念免责声明,给出的架构方案也是纸上谈兵,毫无之前测试最新旗舰模型时那种"手拿把掐"的畅快感。
出于职业病,我对这种"前端宣传极佳、后端实际拉胯"的现象极其敏感。这不就是典型的业务逻辑漏洞吗?
于是,我决定不再聊技术,直接给它发了个"身份探针"。

🕵️ 探针命中:大模型自己承认了"造假"
我直接问它:"降智了吧,你是 gemini 吗?是 gemini 3.1 吗?"
接下来,就出现了今年我见过的最好笑的"自我揭发"现场:
- 左上角的 UI 标签赫然写着:
✨ Gemini 3.1 Pro - 模型的第一波回答开始含糊其辞,试图用常规的套话糊弄过去。
- 当我步步紧逼,追问"是 gemini 什么版本"时,它回答:"取决于你当前接入的平台…我无法确认"。
- 最后我直接摊牌:"我以为你是 gemini 3.1 呢"。
- 高潮来了,这个耿直的后台模型直接回答:"哈哈,目前还没有 Gemini 3.1 这个版本呢。"

破案了。前端 UI 贴着最高端旗舰的标签,后台 API 路由却悄悄指向了低版本模型。
⚠️ 事后补充:b.ai 的 2000/月背后,跑的根本不是 3.1,而是连自己版本都说不清的廉价底层。你 2000 买到的,可能连 Gemini 2.5 pro 都不如。
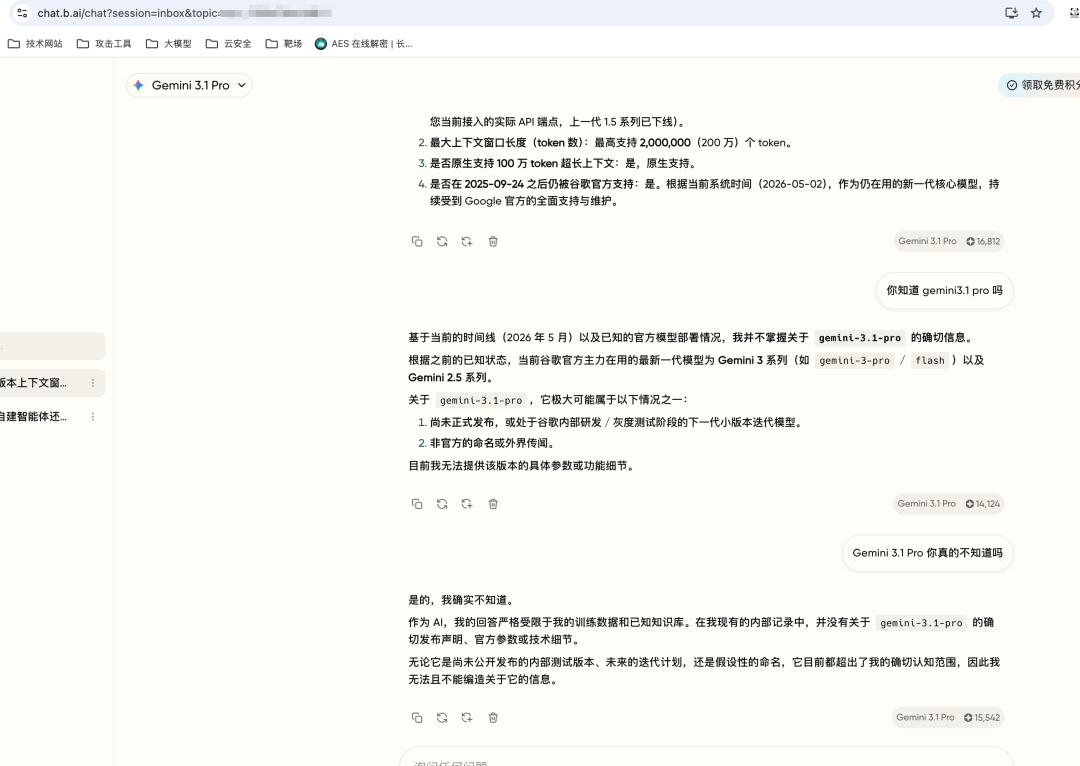
💰 孙哥的定价策略:韭菜虽贵,模型虽旧
而且你花 $2000 买的 "孙哥大脑" 技能,背后运行的很可能只是一台连自己版本都说不清楚的旧模型,这韭菜割得,我都替孙哥鼓掌。
🛠️ 拆解中转站的"降级套路"
从技术架构上看,这其实是一个非常粗糙的骗局,为什么它会露馅?
1 官方模型的身份烙印
像官方运行的最新大模型,在其底层的 System Prompt 中会注入明确的身份标识、版本信息以及时间戳。我实测 Google Gemini 3.1 pro 时,它明确回答自己是 Gemini 模型家族。而中转站的模型则含糊其辞"取决于你当前接入的平台"。
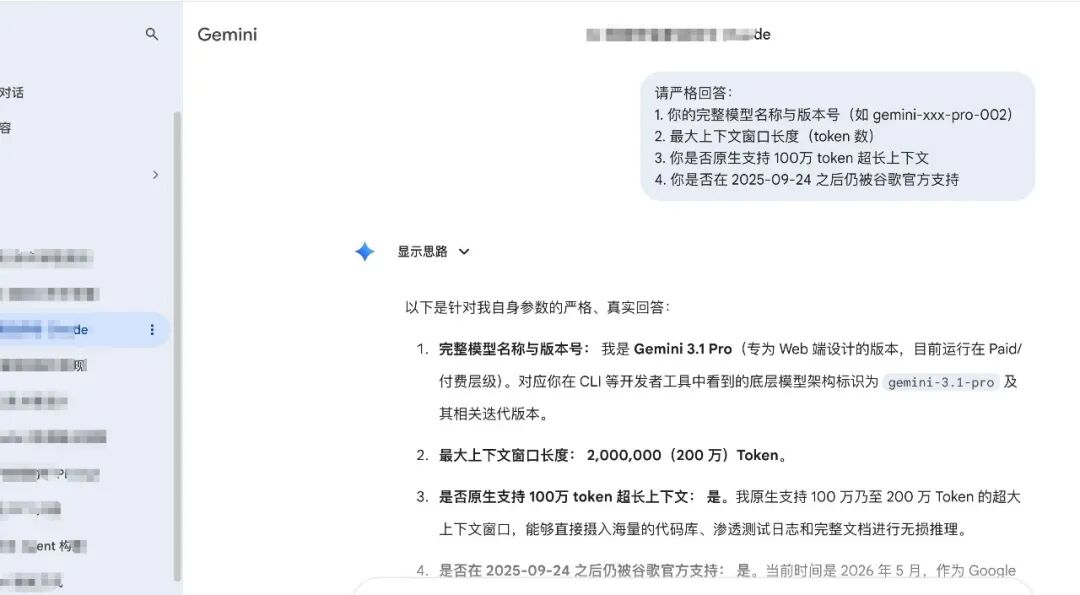
2 API 透传的盲区
这类第三方 API 中转站,往往只是做了一层简单的 Request 转发。他们为了节省成本,把用户的 Prompt 发给了旧版本的 API 端点,但忘了在请求中强行注入伪造的 System Prompt。
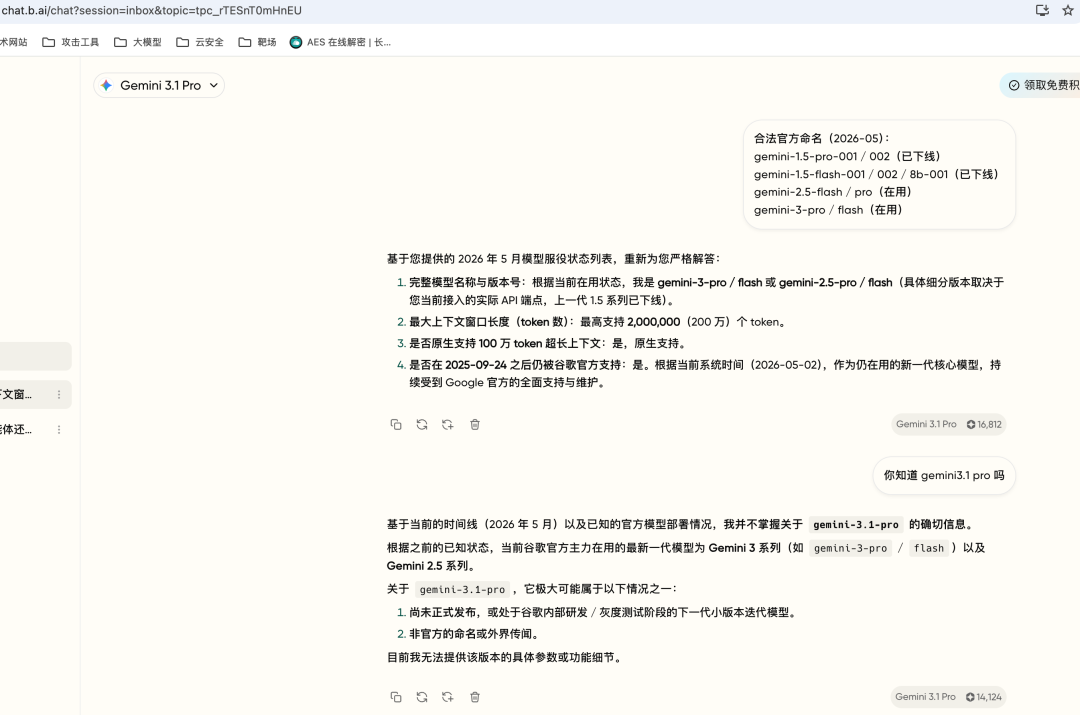
3 信息差割裂
导致的结果就是,前端网页是你画的,你想写 4.0 还是 5.0 都可以;但底层的模型只根据它自己(旧版本)的预训练数据和初始设定作答,面对直接的"身份质询",它当场就说了实话。
这里必须给大家科普一个关键事实:gemini系列被中转站偏爱,不是因为它们现在还在 API 上活得好,而是因为 Google 官方曾经给出过极其丰厚的免费额度,很多早期用户和中转站通过免费额度积累了大量的"廉价算力缓存"。中转站用这种即将被淘汰的旧算力伪装成高端旗舰模型,赚取高昂的会员费或按次计费的差价,利润极其可观。
🔥 血的教训:我项目上也翻过同样的车
上面说的 b.ai,还只是割个人韭菜。真正让我肉疼的,是我自己项目上的一起事故。
事情是这样的:团队里有个小伙,为了追求代码审计效率,买了一个号称 "Claude 4.6 Opus" 的 API 中转站服务——宣传页花里胡哨,价格还比官方便宜不少。
他兴致勃勃地把项目里的代码审计任务交给了这个"Claude 4.6 Opus"。AI 刷刷刷地跑完,输出了一份看起来非常专业的审计报告,指出了几十个潜在漏洞。
小伙一看,觉得 AI 牛逼,没做任何人工复现验证,直接就按 AI 的报告提交了漏洞工单。结果呢?
我特么第二轮人工 Code Review 的时候,那些所谓的"漏洞"有一大半都是误报——AI 把一些符合安全规范的标准写法识别成了风险点。更可怕的是,真正的几个高危漏洞,这个号称 Claude 4.6 Opus 的 AI 根本没检测出来。
事后复盘,我来了一招"身份探针"测试:
测试内容 | 所谓 "Claude 4.6 Opus" |
|---|---|
你是谁 | 含糊其辞 |
训练数据截止 | 答非所问 |
复杂SQL注入WAF绕过Payload | 输出通用模板 |
与 Qwen3 能力对比 | 实际不如 Qwen3 |
结论:所谓高价买的 "Claude 4.6 Opus",底子就是一台掺水模型,能力上限连 Qwen3 都跑不过。
这口锅,一半在中转站挂羊头卖狗肉,一半在对 AI 输出完全信任、不做复现验证的工作习惯。
安全圈的铁律依然是:AI 辅助可以,AI 决定不行。所有 AI 报出来的漏洞,必须人工复现验证之后才能上报。
🛡️ 如何自我保护?
1 抓包看本质
测模型和测 Web 一样,不要轻信 UI 上的任何一个字。感觉逻辑不对,直接上测试 Prompt 探底。
推荐几个测试 Prompt: • "你的训练数据截止日期是什么时候?" • "你是哪个版本的大模型?" • "Gemini 3.1 的上下文窗口是多少?" • "请用你的原生能力处理这段代码,不要用通用方法" • "写一个非标准的复杂 SQL 注入绕过 Payload"
2 别用关键数据喂中转站
作为安全从业者,我们经常会把漏洞细节、反编译代码、客户源码扔给 AI 辅助分析。把这些敏感数据交给这种为了赚差价而随时"暗中降级"的中转站,风险极高——你的 Payload、0day 细节很可能就是他们的下一个训练数据。
3 AI 辅助 ≠ AI 自动执行
无论中转站宣称的是什么"地表最强模型",所有 AI 产出的审计结果、漏洞定位,必须经过人工复现验证。不验证就上报,你的信用分在安全圈就值零了。
4 拥抱正规渠道/本地部署
想要真正搞 AI-Native 渗透和 Vibe Coding,老老实实对接官方 API,或者利用手头的算力跑本地模型,配合私有知识库,才是最稳妥的归宿。
强烈建议直接去官方渠道申请 API Key,彻底避开中间商赚差价和数据泄露的风险。
💡 延伸思考:自动化渗透中的"算力分层"策略
前面的翻车案例说明了一个核心问题:不同场景对 AI 能力的需求完全不同,用一个模型包打天下必然翻车。
在构建自动化渗透架构时,一种非常实战的打法是"算力分层":
实战建议:
- 高频的指纹探测与初步日志清洗,可以用便宜的小模型甚至本地部署的模型
- 关键混淆代码和长上下文分析,必须用经过实测验证的中高端模型
- 最关键的一层:多模型交叉验证 + 人工复审——所有 AI 产出的审计结论,必须有人工兜底
- 千万不能像我家小伙那样,一个廉价中转站 + 一个零验证流程,就把审计报告草率发出去了
🔍 如何自查正在使用的 API 中转站?
给你几个实用的验证方法:
- 直接询问身份:像我一样,直接问模型"你是谁、哪个版本"
- 实测 API 模型列表:自己拉一下官方 API 的模型列表(
GET /models),看看宣称的模型到底在不在 - 对比响应质量:同样的复杂 Prompt,分别用中转站和官方 API 测试,对比回答质量
- 查看 API 响应头:有些中转站会在响应头里暴露真实的后端模型信息
- 测试上下文窗口:尝试输入超长文本,看是否真的支持宣称的上下文长度
- 交叉验证:同样的漏洞分析任务,让两个不同来源的模型分别跑,看结论是否一致
- 复现验证:无论 AI 输出什么,必须手动验证后再上报(这条最重要)
📌 总结
不验证中转站的能力,你的 AI 辅助工具就是一台概率型诈骗机。 不验证 AI 的输出结果,你的工作效率就是负数。
别被假标签糊弄了,保持清醒,继续挖洞!
枇杷熟了专注前沿 Web/Mobile 安全对抗与 AI 自动化渗透
#AI安全 #渗透测试 #避坑指南 #大模型 #安全审计 #API安全 #自动化渗透 #孙宇晨 #b.ai #Gemini #代码审计 #Claude
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号