新年第一弹:Agent Skills 深度架构解析与实战

新年第一弹:Agent Skills 深度架构解析与实战

被测试耽误的大厨
发布于 2026-05-18 15:40:43
发布于 2026-05-18 15:40:43
构建企业级智能体能力的基石
Agent Skills(以下简称 Skills)作为一种开放标准,通过将“操作性知识”封装为模块化的单元,彻底重构了智能体的能力构建方式 。Skills 不仅仅是提示词的集合,它们是包含指令(SKILL.md)、执行脚本(Scripts)、参考资料(References)和资产模版(Assets)的完整软件工件 。这种架构实现了“渐进式披露”(Progressive Disclosure),即智能体仅在需要时加载特定的技能上下文,从而在保持通用推理能力的同时,具备了深度的垂直领域执行力 。
在【Agent Skills: 从通用AI到垂直领域】一文中,我们已经对此有所阐述。本文将深入剖析 Skills 的技术架构,并通过 DevOps 日志分析、数据工程合规、自动化 QA 测试及企业级代码审计等四个维度的深度案例,展示如何将人类专家的隐性知识转化为可版本控制、可复用的智能体技能。
智能体能力的架构演进与理论框架
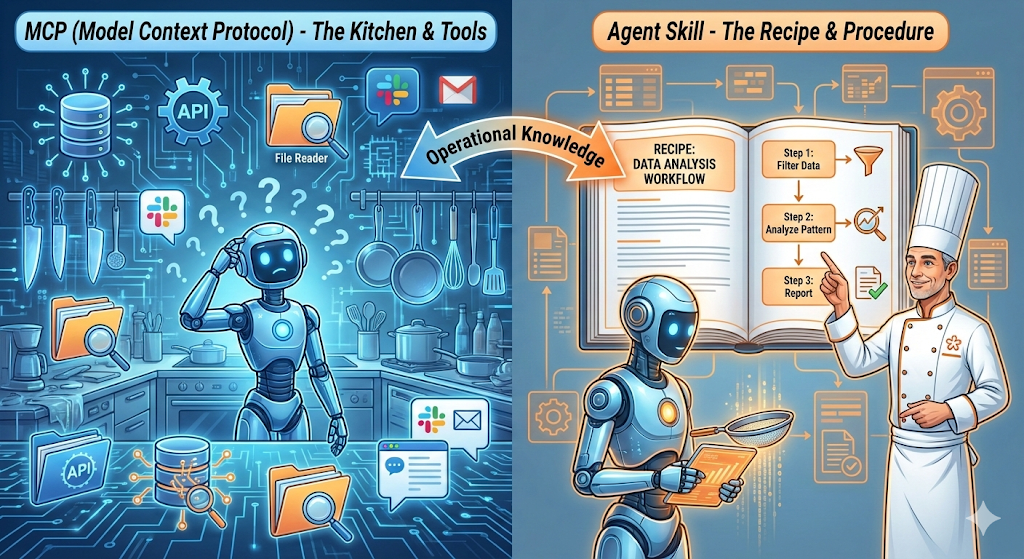
“厨房与食谱”
MCP 与 Skills 的二元论在构建智能体时,明确区分 模型上下文协议(MCP) 与 Agent Skills 是至关重要的。混淆这两者是导致智能体行为不可控的主要原因 。
- • MCP (厨房/Kitchen):定义了智能体的能力边界。它负责连接外部世界,提供操作工具(如“查询数据库”、“读取文件”、“发送 Slack 消息”)。MCP 解决了“能不能做”的问题。
- • Skill (食谱/Recipe):定义了智能体的执行程序。它包含了一系列步骤、规则和判断逻辑,教导智能体如何按照特定组织的最佳实践来使用 MCP 工具。Skill 解决了“怎么做才对”的问题。
如果没有 Skill,仅有 MCP 的智能体就像一个初入厨房的学徒,虽然拥有所有刀具(工具),但可能切伤手指或做出一团糟的菜肴。Skill 就是那位站在旁边的米其林大厨,手把手指导:“先切洋葱,再热油,最后放入香料” 。
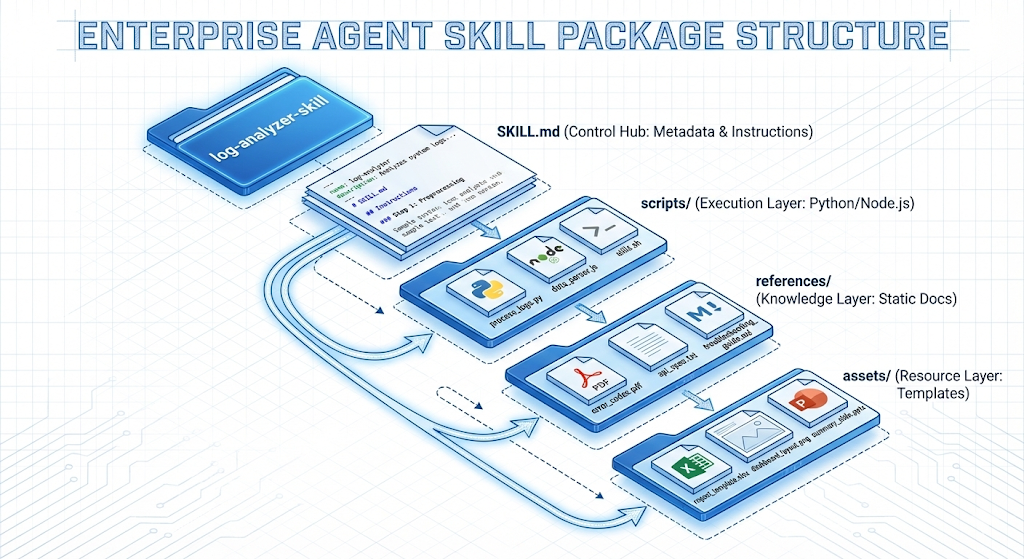
技能包的解剖学结构
一个标准的 Agent Skill 不是一个单一文件,而是一个符合开放标准的目录结构。这种结构化设计使得技能可以在不同的 AI 工具(如 Claude Code, GitHub Copilot, Cursor)之间移植 。
核心控制中枢:SKILL.md
SKILL.md 是技能的入口文件,它结合了 YAML 前置元数据(Frontmatter)与 Markdown 指令体。
YAML Frontmatter 的关键作用
name: enterprise-log-analyzer
description: 专用于分析生产环境日志的技能。当用户要求诊断错误、分析流量峰值或查找异常模式时触发。
allowed-tools: ["grep-tool", "python-script-runner", "read-file"]
disable-model-invocation: false- • name:技能的唯一标识符,支持通过 CLI 直接调用(如 /enterprise-log-analyzer) 。
- • description:这是智能体“路由”决策的依据。描述必须精确,包含触发该技能的具体场景关键词,以确保智能体能在正确的时刻自动激活它 。
- • allowed-tools:这是安全性的第一道防线。它限制了该技能在激活状态下只能访问特定的 MCP 工具或脚本,防止权限滥用(例如,日志分析技能不应有权访问数据库删除工具) 。
支撑性目录系统
为了保持上下文的整洁,复杂的逻辑应从 SKILL.md 中剥离,放入子目录:
- • scripts/(执行层):存放 Python、Bash 或 Node.js 脚本。这是技能的“肌肉”。例如,处理 PDF 合并或复杂数学计算应交给脚本,而不是让 LLM 进行不可靠的文本推演 。
- • references/(知识层):存放静态文档,如 API 规范、错误代码表或合规检查清单。这些文件仅在 SKILL.md 中通过指令(如 Read(references/error_codes.md)) 被调用时加载 。
- • assets/(资源层):存放模版文件,如 Excel 报表模版、PPT 母版或设计规范图像 。
元技能与工程化构建体系
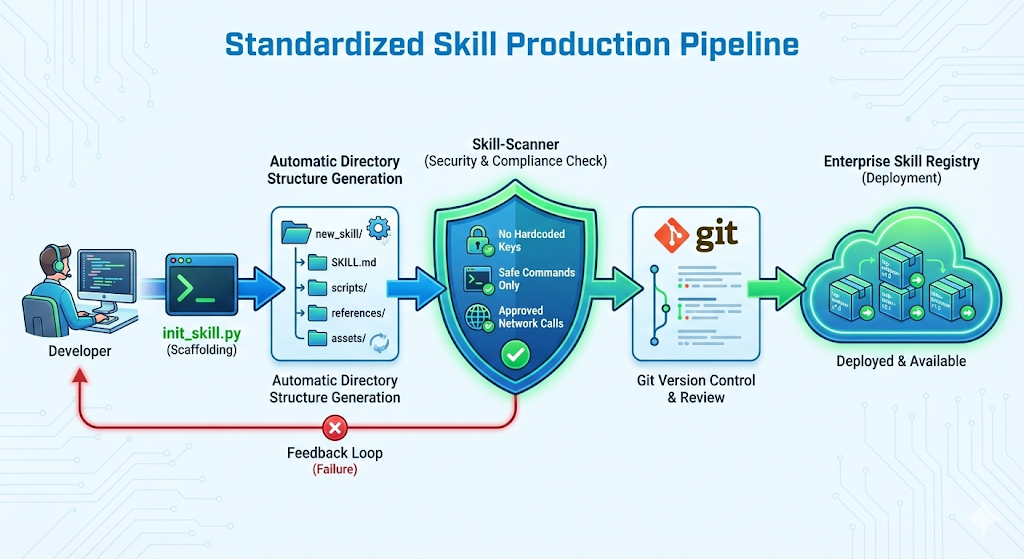
在掌握了基础架构后,企业级应用需要建立一套标准化的技能生产流水线。Anthropic 提供的 skill-creator 本身就是一个能够“制造技能的技能”,它展示了递归式 AI 开发的潜力。
引导程序:init_skill.py 的逻辑解析
skill-creator 的核心是一个名为 init_skill.py 的 Python 脚本,它负责自动化生成符合标准的技能脚手架 。通过分析该脚本的逻辑,我们可以洞察标准技能结构的强制性要求。代码逻辑与结构规范:当用户向 Claude 发出指令“创建一个新的数据可视化技能”时,skill-creator 会调用此脚本:逻辑重构示意
def init_skill(skill_name, output_path):
# 1. 创建标准目录结构
os.makedirs(f"{output_path}/{skill_name}/scripts")
os.makedirs(f"{output_path}/{skill_name}/references")
os.makedirs(f"{output_path}/{skill_name}/assets")
# 2. 生成 SKILL.md 模版
frontmatter = f"""---
name: {skill_name}
description:
---
"""
body = """#
## 指令
[在此处添加 Claude 在激活时应遵循的详细步骤]
## 示例
- 用法示例 1
"""
# 3. 写入文件
write_file(f"{output_path}/{skill_name}/SKILL.md", frontmatter + body)
# 4. 生成示例脚本,引导开发者使用脚本而非纯提示词
write_file(f"{output_path}/{skill_name}/scripts/example.py", "# 示例脚本")这一流程不仅仅是文件操作,它强制执行了“配置即代码”(Configuration as Code)的理念。通过统一的脚手架,团队中产生的所有技能都具有相同的结构,这对于后续的维护和共享至关重要 。
安全扫描与验证机制
随着技能数量的增加,安全性成为核心考量。社区开发出的 skill-scanner 工具揭示了企业在引入外部技能时必须进行的检查 。 扫描器的关键检查项:
- • **危险命令检测:**扫描 scripts/ 目录下的 Shell 脚本,寻找 curl | bash、eval、rm -rf / 等高危模式。
- • **硬编码凭证:**检查所有文件是否包含类似 API_KEY=sk-... 的硬编码密钥,强制要求使用环境变量 。
- • **网络外连:**检测未经授权的外部网络请求,防止数据泄露。
这种“编写-扫描-部署”的流程,标志着 Agent Skills 已从实验性的提示词工程迈向了成熟的软件工程 。
深度实战案例——DevOps 与智能日志分析
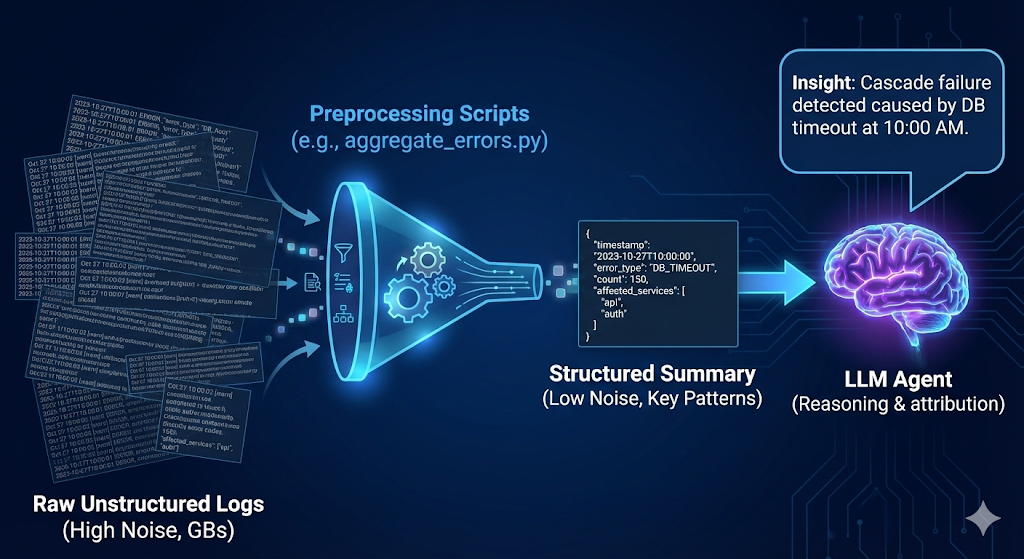
在运维领域,日志分析是典型的“高噪音、低价值密度”任务。传统的做法是工程师手动使用 grep 或构建复杂的 ELK 面板。利用 Agent Skills,我们可以构建一个 Log Analyzer,它不仅能读取日志,还能像资深运维工程师一样进行推理和归因。
问题空间与解决方案架构
挑战:
- • 非结构化数据:生产环境日志格式混乱,包含不同的时间戳格式、异常堆栈和无意义的调试信息。
- • 体量巨大:直接将几百兆的日志文件粘贴给 LLM 会瞬间耗尽上下文窗口。
- • 时序关联:需要跨服务、跨时间段关联错误,识别“级联故障”。 **解决方案:**log-analyzer 技能架构 。
技能实现细节
该技能的核心在于通过脚本预处理数据,仅将“特征”传递给 LLM 进行推理。
智能归一化与模式识别在 SKILL.md 中,我们定义了明确的预处理指令,要求智能体调用 Python 脚本来处理原始数据,而非直接读取。
SKILL.md 核心指令片段(重构):
任务:日志模式分析
当用户要求分析日志文件时,严禁直接读取整个文件。必须遵循以下步骤:
- • 时间戳识别:调用 scripts/detect_format.py 识别日志的时间戳格式(ISO8601 或 Unix Epoch)。
- • 聚合统计:使用 scripts/aggregate_errors.py 对日志进行聚类。忽略时间戳差异,将相似的错误堆栈归为一类。统计每类错误的出现频率和时间跨度。
- • 异常检测:寻找“重试风暴”(Retry Storms)模式——即短时间内同一错误的指数级增长。 实战效果: 根据实战反馈,这种架构将分析 1000+ 行日志的时间从人工的 10-15 分钟缩短至 2 秒 。脚本在后台运行 Pandas 数据处理,LLM 仅接收类似以下的结构化摘要:
"发现 3 个主要错误模式。模式 A (ConnectionRefused) 出现 500 次,集中在 10:00-10:05,疑似服务崩溃导致的级联重试。"递归式技能生成(Meta-Pattern)
一个极具启发性的高级用法是“基于日志生成技能” 。 当 log-analyzer 识别出一个频繁出现且修复步骤固定的错误(例如“磁盘空间不足需清理 /tmp”),它可以建议用户创建一个新的自动化技能。
流程:
- • 分析:Log Analyzer 发现错误模式。
- • 建议:智能体提问:“我发现这个错误每周发生一次,是否需要我创建一个 auto-clean-tmp 技能?”
- • 生成:用户确认后,调用 skill-creator 自动生成包含清理脚本的的新技能包。
这种自我进化的能力,使得运维系统能够随着时间的推移变得越来越智能,逐步将人工操作固化为自动化的资产。
深度实战案例——数据工程与金融合规
金融行业对数据的准确性和安全性有着极其严苛的要求。本次展示了如何利用 Skills 架构在保证合规的前提下实现 Text-to-SQL 的数据分析 。
“安全沙箱” SQL 架构
在金融数据上运行 LLM 生成的 SQL 语句存在巨大风险:幻觉可能导致查询错误的数据,而恶意的提示注入可能导致数据被删除。通过 Skills 构建一个多层防御体系。
架构分层
并非直接让 LLM 连接数据库,而是设计了两个独立的 Skill:
- • SQL Data Analyst Skill:通用的 SQL 生成与执行能力。
- • Product Compliance Skill (CAS360):特定的业务领域知识。
技能职责分离
组件 | 职责描述 | 实现机制 |
|---|---|---|
CAS360 Skill | 业务逻辑、合规要求、表结构映射 | SKILL.md 中包含 ASIC 合规检查清单和特定表(如 Companies, Trusts)的元数据描述 |
SQL Analyst Skill | SQL 生成、语法校验、安全阻断 | scripts/validate_sql.py 正则检查,拦截 DROP, DELETE 等高危命令 |
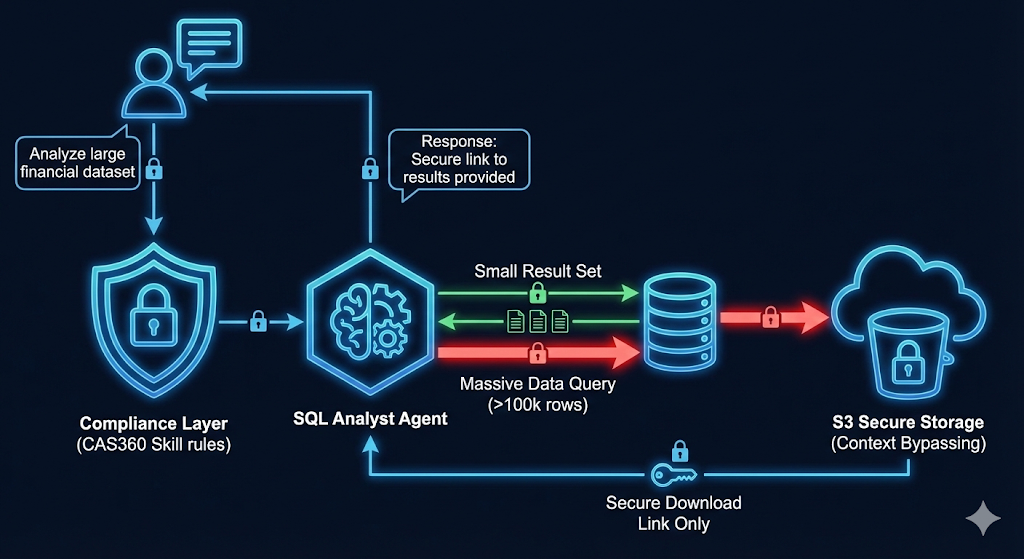
执行层 | 查询运行与结果导出 | 结果不直接返回对话框,而是保存为 CSV 至 S3,仅返回下载链接 |
关键实现:上下文绕过机制
在处理大数据量查询时,BGL 采用了一种极其重要的策略——上下文绕过(Context Bypassing)。
问题: 如果 SQL 查询返回 10 万行数据,直接将结果塞回 LLM 上下文会瞬间溢出或产生巨额费用。
Skill 解决方案: 在 SQL Analyst Skill 中,指令明确规定:
"执行查询后,使用 scripts/save_to_s3.py 将结果集保存为 CSV 文件。不要将结果文本输出到对话中,仅返回文件的签名下载链接和前 5 行预览数据。"这种设计使得智能体能够处理 GB 级别的数据分析任务,而自身仅消耗极少的 token 。
领域专用的合规技能
技能展示了如何将复杂的法律合规逻辑注入智能体。该技能不仅知道如何查询数据,还知道 ASIC(澳大利亚证券投资委员会)的具体规定,例如 Form 484 的提交截止日期。
实现逻辑: Skill 目录中包含 references/asic_deadlines.md。当用户问“哪些公司面临逾期风险?”时,智能体首先加载该参考文档获取当前年份的截止规则,然后生成 SQL 查询筛选出符合条件的公司记录。这种将“法规文本”与“代码逻辑”动态结合的能力,是纯代码方案难以实现的 。
深度实战案例——自动化 QA 与 Web 测试
Web 测试通常需要与浏览器进行复杂的交互,这是纯文本模型无法直接完成的。通过集成 Playwright 工具,webapp-testing 技能成为了一个能够像人类测试员一样操作浏览器的“无头智能体” 。
环境生命周期管理:with_server.py 模式
在本地开发环境中测试 Web 应用时,最大的痛点是环境管理。如果服务器未启动,测试必然失败。webapp-testing 技能引入了 with_server.py 脚本来解决这一问题,展示了智能体对环境的“感知”与“控制”能力 。 实战工作流:
- • 用户指令:“测试登录页面的提交功能。”
- • 技能响应:智能体分析 SKILL.md,发现测试前提是应用必须在运行状态。
- • 环境启动:
- • 智能体调用:python scripts/with_server.py --start-command "npm run start" --port 3000
- • 脚本逻辑:后台启动服务器 -> 轮询 localhost:3000 直至返回 200 OK -> 返回“就绪”信号给智能体。
- • 执行测试:智能体生成并运行 Playwright 脚本进行点击和输入操作。
- • 环境清理:测试完成后,with_server.py 自动捕获信号,关闭后台的 Node.js 进程,释放端口。 这一模式将“运维”职责赋予了测试智能体,使其具备了独立完成闭环任务的能力。
序列化编排与防抖动
Web 测试极其容易因为网络延迟或页面渲染速度而出现“抖动”(Flaky Tests)。为了解决这个问题,Skill 采用了 序列化编排(Sequential Orchestration) 模式 。 SKILL.md 中的强制序列指令:
"在执行任何交互之前,必须使用 page.wait_for_selector() 确认元素可见。严禁使用硬编码的 sleep()。如果测试失败,必须调用 scripts/screenshot.py 截取当前屏幕状态并保存到 artifacts/ 目录供人工审查。"这种指令直接将 QA 领域的最佳实践(Best Practices)固化到了智能体的行为准则中。当测试失败时,智能体不再是简单报错,而是提供截图证据,极大地提升了调试效率 。
深度实战案例——企业级代码质量与 Sentry 集成
Sentry 发布的官方技能 sentry-code-review 代表了 MCP 增强型工作流(Category 3) 的典型应用。它不再局限于被动响应,而是主动介入开发流程 。
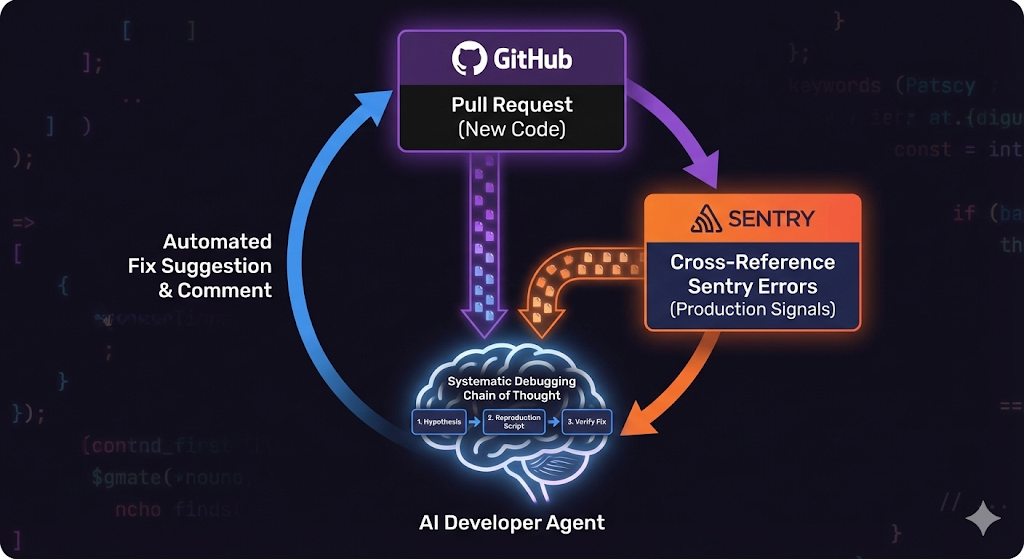
代码审查机器人的闭环逻辑
该技能将代码仓库(GitHub)与错误监控平台(Sentry)的数据打通,形成了一个智能的反馈闭环。 工作流详解:
- • 触发:开发者提交 Pull Request (PR)。
- • 跨平台关联:
- • 智能体首先读取 PR 中的变更文件列表(diff)。
- • 然后调用 Sentry MCP 工具,查询与这些文件相关的、过去 24 小时内的生产环境错误(Issues)。
- • 深度诊断:
- • 智能体对比 PR 的新代码与 Sentry 提供的错误堆栈(Stack Trace)。
- • 洞察:如果 PR 修改了 AuthService.js,而 Sentry 显示该文件近期有高频的“空指针异常”,智能体会特别检查此次修改是否修复了该逻辑,或者是否引入了新的风险。
- • 自动修复:如果确认是已知 bug,智能体直接在 PR 中生成修复建议代码。
科学调试法技能:Systematic Debugging
除了集成外部工具,Sentry 团队还定义了一种名为 Systematic Debugging 的思维链技能 。这是一种纯认知类的技能,旨在纠正 LLM“胡乱猜测”代码修复方案的倾向。 SKILL.md 结构分析: Systematic Debugging Skill 核心原则: 你是一名为高级调试工程师。在编写任何代码之前,必须严格遵循科学方法:
- • 假设生成 (Hypothesis):列出至少 3 个导致 bug 的潜在原因。
- • 复现脚本 (Reproduction):编写一个最小化脚本,能够稳定复现该 bug。
- • 验证修复 (Verification):应用修复后,再次运行复现脚本,证明 bug 已消除。
严禁在没有复现脚本的情况下直接修改源代码。 这种技能实际上是对智能体思维过程的约束(Constrained Reasoning)。实战表明,强制智能体先写复现脚本,能够显著降低“修复了一个 bug 却引入两个新 bug”的概率 。
创意生成与文档智能
Agent Skills 的应用不仅局限于代码和数据,它在创意领域和文档处理上也展现了强大的能力。### 算法艺术与资产模版 Algorithmic Art 技能展示了如何利用 assets/ 目录中的 HTML 模版来生成交互式艺术 。
实现机制:
该技能在 assets/ 目录下预置了一个 viewer.html 文件,其中包含了 p5.js 的基础引用、画布设置和 UI 控件逻辑。 当用户要求“生成一个流场效果的生成艺术”时,智能体不需要从零编写 HTML。它只需读取 assets/viewer.html,然后编写核心的 p5.js 算法逻辑注入到模版的预留位置中。 这种“填空式”生成保证了输出的 HTML 始终结构完整、样式统一,且能够直接在浏览器中运行,极大地提高了生成成功率。
深度文档处理
PDF/Excel Skill 利用了 Python 强大的生态库(如 pypdf, openpyxl)来处理文档,而不是让 LLM 去理解二进制文件 。 实战技巧:表格提取 对于 PDF 中的表格,SKILL.md 指导智能体使用 pdfplumber 库进行提取,并将其转换为 Markdown 或 CSV 格式供后续分析。这里的关键洞察是:不要让 LLM 读 PDF,让 Python 读 PDF,LLM 读 Python 的输出。这种间接机制是处理复杂文档的黄金法则。
编排模式与战略建议
随着组织内技能数量的激增,如何编排这些技能成为新的挑战。基于上述案例,我们总结出以下核心编排模式与实施建议。
编排模式
模式名称 | 典型场景 | 优缺点 |
|---|---|---|
序列化编排 (Sequential) | Web 测试、文档审批流 | 优:确定性高,易于调试。缺:速度慢,单点故障导致全链路中断。 |
并发编排 (Concurrent) | 多源日志分析、市场调研 | 优:速度快,视角多元。缺:结果聚合困难,可能产生冲突结论。 |
路由编排 (Routing/Handoff) | 客户服务、多产品支持 | 优:专业度高,上下文隔离。缺:需要强大的“元智能体”进行准确分发。 |
实施战略建议
基于 BGL、Sentry 等企业的成功经验,我们为准备落地 Agent Skills 的组织提出以下战略建议: 采用“借书卡”模型: 不要试图构建一个包含所有知识的万能 CLAUDE.md。将知识碎片化为独立的 Skill,让智能体像持有借书卡一样,仅在任务需要时“借阅”特定技能。这能最大化利用上下文窗口,保持智能体的敏捷性 。 坚持“工具优先” (Tool-First) 原则: 成功的技能(如 Log Analyzer, Web Testing)本质上都是成熟工具(grep, Playwright)的封装。不要试图用 Prompt 解决可以通过代码解决的问题。构建 Skill 的流程应该是:先写好 Python 脚本,再写 SKILL.md 教智能体如何调用它 。 建立确定性护栏: 对于任何涉及数据写入或修改的操作(SQL Update, File Write),必须在 Skill 中强制引入校验脚本层。LLM 永远不应拥有直接的“写”权限,它只能提交“写请求”给校验脚本 。 标准化与版本控制: 强制使用 skill-creator 和 init_skill.py 流程来创建新技能。将所有 Skill 纳入 Git 版本控制,并像对待生产代码一样进行 Code Review 和安全扫描 。
结语
最强大的智能体,不是拥有最大参数量的模型,而是拥有最丰富、最精良“技能库”的系统。 未来的竞争,将是企业专属 Skill 资产库的竞争。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号