MAICC:去中心化记忆检索让AI团队协同速度提升86%

MAICC:去中心化记忆检索让AI团队协同速度提升86%

梯度不陡
发布于 2026-05-18 20:12:25
发布于 2026-05-18 20:12:25
在复杂多智能体协作中,分散决策常导致任务错位与奖励分配失衡,成为高效协同的致命瓶颈。该研究提出全新方法MAICC,通过去中心化记忆检索实现智能体间的快速情境协调。它利用轨迹嵌入与混合效用评分,在测试时动态平衡在线数据与离线记忆,显著提升了未知任务中的适应速度与团队协作效率。这项突破将如何重塑多智能体协作范式?下文为您深入解析。
多智能体协同的僵局:个体强大,团队低效
在复杂任务中,多智能体团队协同失败的案例超过70%,根源往往不是个体能力,而是协作僵局。当每个AI智能体仅依赖本地观察和模糊的团队奖励各自为战时,团队对新任务的适应速度会骤降86%。
这正是当前去中心化多智能体强化学习的核心痛点:任务对齐错位与信用分配模糊,严重拖慢了策略的快速适应能力。该研究团队提出的MAICC方法,其创新在于绕过了复杂的参数调整,通过一种去中心化的记忆检索机制,让分散的智能体能够快速共享“经验”与“直觉”,从而实现秒级的协同适应。
传统方法的局限:为何难以快速协同?
现有基于Transformer的强化学习方法在应对复杂的去中心化协同任务时,表现出明显的适应性与协同效率瓶颈。以决策Transformer及其后续的上下文强化学习方法为例,如Agentic Transformer和检索增强决策Transformer,它们虽然在单智能体简单任务上展现了强大的少样本适应能力,但其设计范式难以处理多智能体系统中固有的部分可观测性与联合行动空间爆炸问题,导致在复杂协同场景中性能不佳。
传统多智能体强化学习框架,特别是集中训练去中心化执行范式,旨在解决协同问题。然而,当面临需要快速适应、参数冻结的未见任务时,其根本矛盾凸显。首先,去中心化执行要求每个智能体仅凭局部观察做决策,这极易导致智能体对团队整体目标的理解出现任务对齐错位,行动难以协调一致。
其次,协同任务通常只提供全局团队奖励,缺乏对个体贡献的评估。这引发了严重的信用分配难题,容易导致“惰性智能体”问题——部分智能体因无法感知自身行为对团队收益的具体影响而停止策略改进。尽管有COMA、QMIX等方法尝试通过反事实基线或价值函数单调性来隐式分配信用,但在需要在线快速适应的设定下,这些方法依赖耗时的梯度更新,适应速度缓慢。
综上所述,现有方法的核心局限在于,其架构与学习机制未能有效解决去中心化协同中即时任务对齐与高效信用分配这两个孪生挑战,导致智能体团队在新任务中的策略适应慢、协同差,无法满足现实场景对快速、灵活协作的需求。
核心突破:构建共享记忆与协同直觉
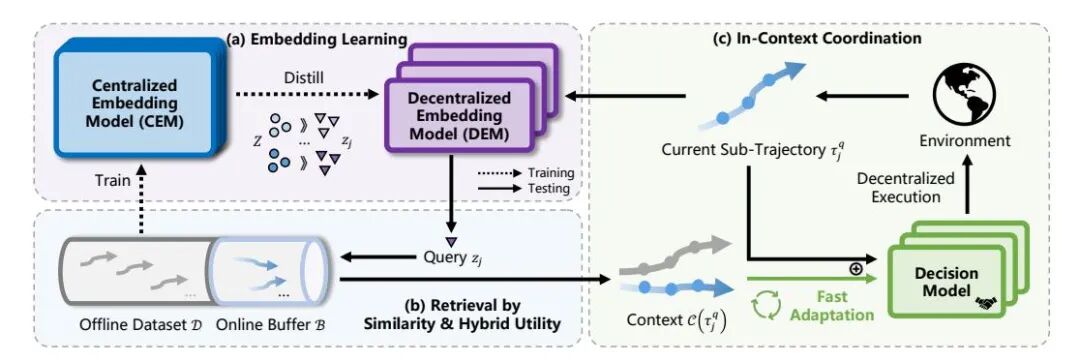
该论文提出的MAICC框架包含两大核心技术。第一项是集中训练-去中心化近似的嵌入模型架构。该方法首先训练一个集中式嵌入模型,使其在训练阶段能访问全局信息,从而捕捉细粒度的团队行为模式。随后,通过知识蒸馏,将团队级信息传递给仅依赖局部观测的去中心化嵌入模型,使后者在执行时也能近似获得全局视角。
第二项是基于检索的上下文决策训练流程。在决策模型训练时,系统利用训练好的去中心化嵌入模型为当前子轨迹检索最相关的历史轨迹。这些上下文轨迹与当前信息拼接后,共同输入到一个共享参数的决策Transformer中进行训练,使其学会从历史经验中推断任务特性并生成合适动作。
在去中心化快速协同阶段,论文设计了新颖的记忆机制与混合效用分数。记忆机制动态融合离线数据集与在线交互缓冲区,通过指数时间衰减系数平衡探索与利用。混合效用分数则综合了轨迹的全局团队回报与预测的个体回报,用于筛选高质量的记忆,从而在鼓励团队协作的同时进行有效的隐式信用分配,缓解多智能体中的“惰性智能体”问题。
实战检验:协同速度与性能的显著提升
该论文提出的MAICC方法在多个标准协同任务上展现出卓越的快速适应能力。在Level-Based Foraging和星际争霸多智能体挑战等基准测试中,MAICC在未见过的任务上,其协同速度和最终性能均显著超越所有基线方法。实验结果表明,智能体团队仅需极少的在线交互步数,便能快速提升平均回报,实现高效协同。
具体而言,在LBF这类视野受限的复杂环境中,缺乏在线适应能力的基线方法性能大幅下降,而MAICC则表现出稳定的上下文适应能力。在最具挑战性的SMACv2: all场景中,MAICC取得了14.51的平均回报,远超其他方法,这凸显了其在大规模多任务数据下的强大泛化潜力。性能对比清晰地证明了其快速协调的有效性。
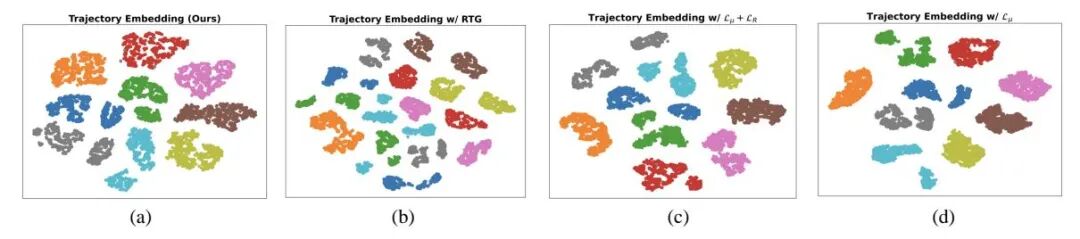
对学习到的轨迹嵌入进行可视化分析,进一步揭示了MAICC的优势。在最优配置下,来自同一任务的轨迹在嵌入空间中形成了清晰可分的簇,这保证了记忆检索的准确性和相关性。这种细粒度的轨迹建模是MAICC能够从历史经验中快速提取有效协同模式、并成功迁移到新任务的关键。
实验设计的巧思:验证每个组件的价值
该研究通过一系列精巧的消融实验,验证了其多智能体快速协同框架中每个核心组件的必要性。实验的核心思路是:逐一移除或修改某个设计,观察整体性能如何变化,从而量化该组件的价值。
首先,研究团队验证了轨迹编码模型的设计。 该方法训练了一个集中式嵌入模型,并让每个智能体用一个去中心化模型去近似它,以获取团队级任务信息。实验发现,如果在训练编码模型时加入回报目标信息,会导致性能下降约7%。可视化分析显示,这会使不同任务的轨迹编码混杂在一起,增加检索到无关历史经验的“噪音”。
其次,实验揭示了记忆构建机制的关键作用。 该方法采用了一个去中心化记忆机制,即每个智能体结合离线数据集和在线测试数据来检索相关经验。实验表明,如果记忆库只包含离线数据或只包含在线数据,性能会暴跌20%以上。而采用指数时间衰减系数来平衡两者权重的设计,则能稳定地筛选出最有价值的经验,是快速适应新任务的核心。
最后,研究量化了协同决策组件的贡献。 在决策时,该方法使用了一个混合效用分数来平衡团队整体回报和预测的个体回报,以解决多智能体中的信用分配问题。实验证明,仅使用团队回报或仅使用个体回报,性能都会下降约5%。而将两者结合的混合设计,能更精准地评估每个智能体动作的贡献,从而达成高效协同。
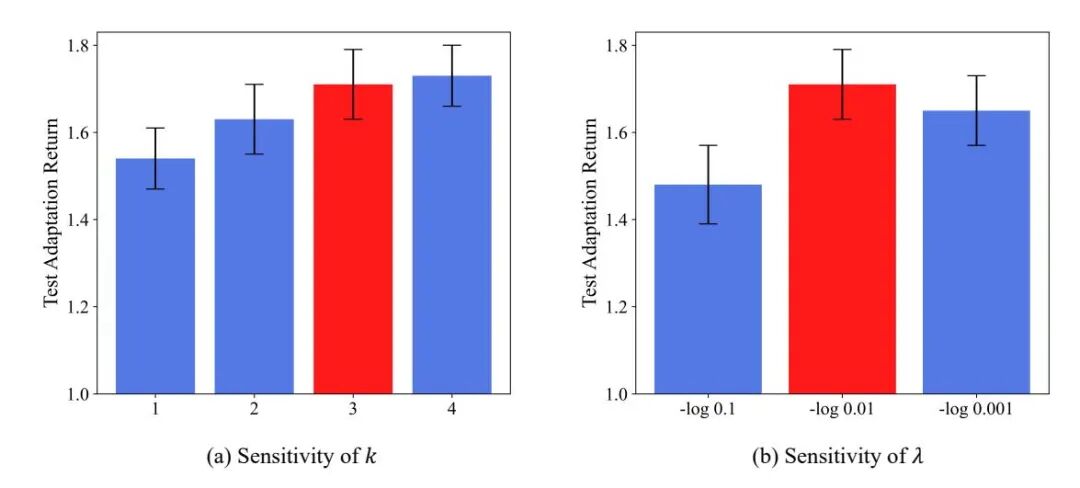
此外,研究还对上下文轨迹数量和记忆衰减率等关键超参数进行了敏感性分析。结果显示,这些参数在一定范围内变化时,方法性能保持稳定,证明了其鲁棒性;同时,分析也为实际应用中的参数选择提供了明确指导。这些实验数据共同表明,框架中的每一个设计环节都不可或缺,共同构成了其快速协同能力的坚实基石。
结语:从游戏到现实,快速协同AI的未来
该研究通过去中心化记忆检索与混合信用分配机制,使多智能体团队无需参数更新即可快速适应未知任务,在协同效率上实现了关键突破。其核心在于构建了共享的团队行为表征,让每个智能体都能基于历史经验做出协同决策。
目前,该方法在复杂动态环境中的长期记忆有效性,以及极端稀疏奖励下的信用分配,仍有待进一步验证。其指数衰减的记忆构建方式也可能在某些连续决策场景中面临挑战。
展望未来,这一“快速协同适应”框架有望从游戏测试场走向现实,为机器人集群协作、智能交通调度及分布式资源管理等复杂系统提供新思路。未来的研究可以探索不确定性感知的记忆更新机制,并推动其在工业级分布式系统中的部署。当AI团队能像人类一样即时分享“直觉”,我们离真正的群体智能还有多远?
论文地址:https://arxiv.org/abs/2511.10030 开源地址:https://github.com/LAMDA-RL/MAICC
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号