偏好获取增强的贝叶斯优化

偏好获取增强的贝叶斯优化

CreateAMind
发布于 2026-05-19 10:54:15
发布于 2026-05-19 10:54:15
偏好获取增强的贝叶斯优化
Elicitation-Augmented Bayesian Optimization
https://arxiv.org/pdf/2605.12079


摘要
人在回路贝叶斯优化(HITL BO)方法利用人类专业知识来提高BO的样本效率。大多数HITL BO方法假设领域专家能够量化其知识,例如通过精确指出查询位置,或以概率分布形式指定其对最大值位置的先验信念。然而,由于人类专业知识通常是隐性的且无法显式量化,我们考虑一种设置,其中通过设计方案的成对比较来获取(elicit)专家的领域知识。我们将专家的成对判断解释为关于可观测目标函数值的带噪证据,并开发了一种原则性方法,用于结合通过直接观测和成对查询获得的信息。具体而言,我们推导了一种成本感知的信息价值采集函数,用于在直接观测与成对查询之间进行权衡。所提出的方法逼近单一信息源轨迹的凸包:当成对查询成本较低时,相较于仅观测的BO,它显著提高了样本效率;当成对查询成本高昂或噪声较大时,它通过仅依赖直接观测来恢复标准BO的性能。
引言
贝叶斯优化(BO)是一种用于优化评估成本高昂的黑盒函数的样本高效框架(Shahriari 等, 2016; Frazier, 2018; Garnett, 2023)。在许多实际应用中——例如空气动力学和材料设计(例如,Adachi, 2021; Cissé 等, 2024)——人类专家拥有的领域知识,相比于直接评估目标函数,获取成本更低。因此,出现了越来越多的人类回路(HITL)BO方法(例如,A V 等, 2022; Mikkola 等, 2023; Hvarfner 等, 2024; Xu 等, 2024a),它们利用这种领域知识来提高BO的成本效率。
大多数现有的HITL BO方法假设领域专家能够量化其知识,例如通过精确指出查询位置(A V 等, 2022; Gupta 等, 2023; Khoshvishkaie 等, 2023),或以概率分布形式指定其对最大值位置的先验信念(Hvarfner 等, 2022, 2024; Cissé 等, 2024)。然而,人类专业知识通常是隐性的且定性的(Kahneman 和 Tversky, 1979)。人类对候选方案进行排名的可靠性高于为其赋予校准后的数值(Shah 等, 2014),因此,成对比较是一种用于知识获取的自然查询类型。
我们同时考虑单目标和多目标贝叶斯优化。为了将通过成对比较获取知识的方法扩展至多目标情形,我们假设效用函数在优化过程之前已被获取或指定。当效用函数已知时,专家的成对判断可以被明确解释:它们构成了关于目标函数本身的带噪证据。直接函数评估和成对比较随后共同更新一个单一的共享代理模型,并且单目标和多目标优化得以统一处理。
我们开发了一种基于高斯过程(GP)的原则性方法,用于结合来自直接函数评估和成对比较的数据。具体而言,我们使用了一种混合似然稀疏变分GP,它耦合了高斯观测似然和Probit比较似然,从而产生一个可分解的证据下界(ELBO),其中包含闭式回归项和高斯-埃尔米特(Gauss–Hermite)Probit项。由于两种信息源均用于更新同一后验分布,优化问题简化为序列信源选择问题:在每次迭代中,可能的操作要么是直接评估,要么是成对比较。遵循 Ungredda 和 Branke(2023)的自适应获取框架,我们通过每个候选操作的单位成本预期单步效用增益对其进行评分——即一种成本归一化的信息价值规则。对于评估,该规则退化为知识梯度(Frazier 等, 2009)。对于成对比较,我们在已知效用下的多输出目标及Probit比较似然条件下,推导出了闭式的幻想后验(fantasy posterior)更新(Wu 和 Gardner, 2026)。两种采集函数均通过一次性重构(one-shot reformulation)与候选输入联合优化(Balandat 等, 2020)。
我们在标准的单目标和多目标基准上评估了所提出的方法,称为获取增强的贝叶斯优化(EA-BO)。在不同成本条件下,EA-BO逼近两种单一信源轨迹的凸包:它在优化的每个阶段将预算分配给更具成本效益的信源,在成对查询廉价时优于仅评估的BO,在成对查询昂贵或噪声较大时恢复标准BO的性能。EA-BO还显著优于早期的HITL BO方法CoExBO(Adachi 等, 2024),该方法与我们的工作类似,假设专家能够通过执行成对比较来表达其领域知识。
总而言之,我们的主要贡献是:(i)我们推导了一种混合似然稀疏变分GP,用于更新结合直接目标函数评估与成对查询的模型后验。(ii)我们推导了一种成本感知的信息价值采集规则,在Probit比较似然下具有闭式后验均值,将Wu和Gardner(2026)的成对知识梯度扩展至已知效用下的多输出目标。(iii)在标准基准函数(第6节)上的实验表明,所提出的方法在信息源选择上追踪了帕累托最优凸包,从而在成对比较比评估更便宜的情况下显著提高了BO的成本效率。
2 相关工作
人在回路贝叶斯优化。 早期的人回路BO方法通常假设专家能够显式量化其领域知识。一种受经典贝叶斯推断启发的方法要求专家以概率分布的形式指定其对目标函数最大值位置的先验信念(Ramachandran 等, 2020; Souza 等, 2021; Hvarfner 等, 2022, 2024; Cissé 等, 2024; Guay-Hottin 等, 2025)。在人机协同方法中,专家精确定位下一次目标函数评估的潜在位置(A V 等, 2022; Gupta 等, 2023; Khoshvishkaie 等, 2023)。与这些早期方法不同,我们假设专家的领域知识是隐性的,并通过成对查询隐式地执行知识获取。另一种使用成对查询的方法是CoExBO(Adachi 等, 2024)。与我们方法的主要区别在于:他们使用成对查询直接选择下一次函数评估的位置,随机选择成对查询的位置,且未考虑查询成本。另一项主题相似的工作是Xu等(2024a),该工作同样利用具有隐性知识的人类专家,但假设专家接受或拒绝设计方案。由于对专家的假设不同,该工作无法直接比较。
偏好贝叶斯优化与多目标贝叶斯优化。 偏好贝叶斯优化(Chu 和 Ghahramani, 2005; González 等, 2017; Siivola 等, 2021; Mikkola 等, 2020; Benavoli 等, 2021; Takeno 等, 2023; Astudillo 等, 2023; Xu 等, 2024b)和交互式多目标贝叶斯优化(Astudillo 和 Frazier, 2020; Ungredda 等, 2021; Lin 等, 2022; Ozaki 等, 2024)也利用成对查询。与我们的方法(将成对查询用作关于可观测目标函数值的额外信息源)不同,偏好BO和多目标BO分别使用成对查询来优化潜在偏好或效用函数。此外请注意,在交互式多目标优化中,专家比较的是目标空间
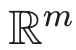
中的两个点,而我们比较的是设计空间 X 中的两个点。复合函数贝叶斯优化(Astudillo 和 Frazier, 2019)同样利用了已知的效用结构,但仅考虑对目标的直接评估。
混合似然方法。 Wu 等(2025)的最新工作也考虑了使用两种不同的信息源更新基于高斯过程(GP)的代理模型。然而,他们结合的是成对查询与李克特量表数据,而我们结合的是成对查询与直接函数评估。Zhang 等(2020)使用二元辅助函数作为低保真度信息源,但他们考虑的是包含两个相关代理模型的设置。
3 预备知识
我们考虑优化一个向量值目标函数(objective function)



4 代理模型
在本节中,我们首先描述一个基于高斯过程(GP)的目标函数代理模型,我们用它来对第3节所述任务中的数据进行建模,然后推导一种用于更新模型后验的变分推断算法。
4.1 GP 模型
我们在 f 上放置一个具有独立坐标的零均值高斯过程先验:
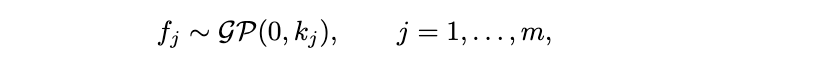



我们数据集的双重似然结构产生了一个具有独立观测和查询贡献的可分解 ELBO(Wu et al., 2025; Moreno-Muñoz et al., 2018):
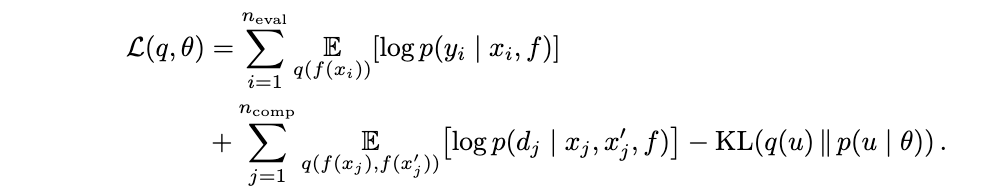

5 采集函数
在本节中,我们首先定义决策问题,然后推导在第 4 节描述的代理模型下该问题的单步效用增益。采集函数是两种可能动作(直接函数评估或成对查询)贡献的成本加权和。


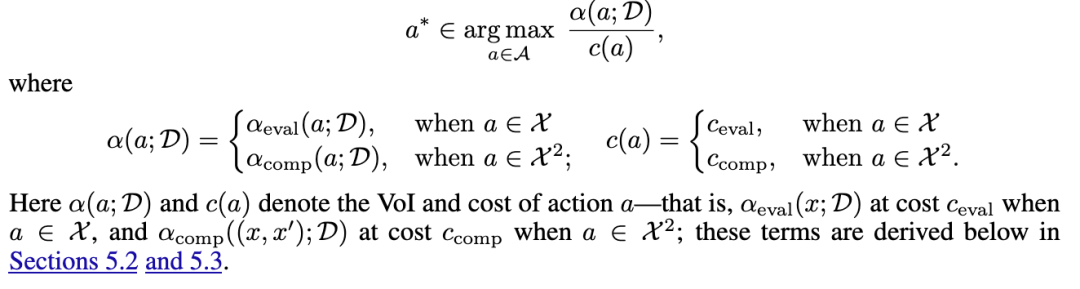
我们选择成本归一化而不是成本减法,因为在固定预算下,成本归一化能最大化单位预算花费所带来的期望效用增益率,而成本减法可能会偏向那些绝对信息价值(VoI)很高但单位回报很差的高成本动作(Poloczek et al., 2017)。



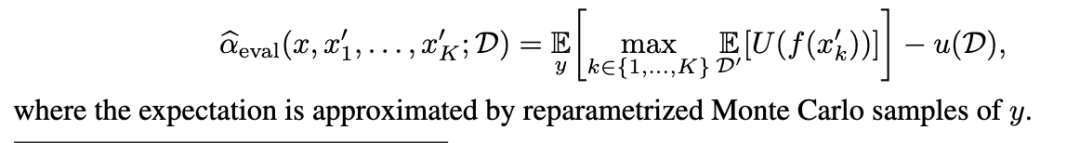

6 实验结果

基线方法。 我们将 EA-BO 与单源基线进行比较,所有方法均使用相同的 GP 代理模型。仅评估的基线包括 LogEI (Ament et al., 2023) 和 UCB (Srinivas et al., 2010)(单目标),EI-CF (Astudillo and Frazier, 2019)(多目标),而仅比较的基线是 EUBO (Astudillo et al., 2023)。KG-Eval 和 KG-Comp 是 EA-BO 的消融实验,被限制为单源;Rand-Eval 和 Rand-Comp 是均匀随机基线。我们还与 CoExBO (Adachi et al., 2024) 进行了比较,这是一种人在回路(HITL)贝叶斯优化方法,它训练一个辅助偏好模型来指导候选选择,而不是将比较作为似然证据纳入代理模型中。
6.1 与单源贝叶斯优化(BO)及人在回路(HITL)贝叶斯优化方法的比较
图 1 展示了在线性效用下,随累计花费预算变化的优化轨迹。在早期阶段,EA-BO 主要将资源分配给廉价的成对比较,因此,其提升速度与仅比较的 KG-Comp 相同。当二元信号饱和导致 KG-Comp 的性能趋于平稳时,随着后验分布变尖锐(不确定性降低),EA-BO 转向直接评估,其效用持续提升,匹配或超过了仅评估的方法。表 2 的第一行显示了动作的分布。这种成本感知选择规则结合了基于比较方法的快速初期进展和基于评估方法的渐近精度,且无需人工调度。
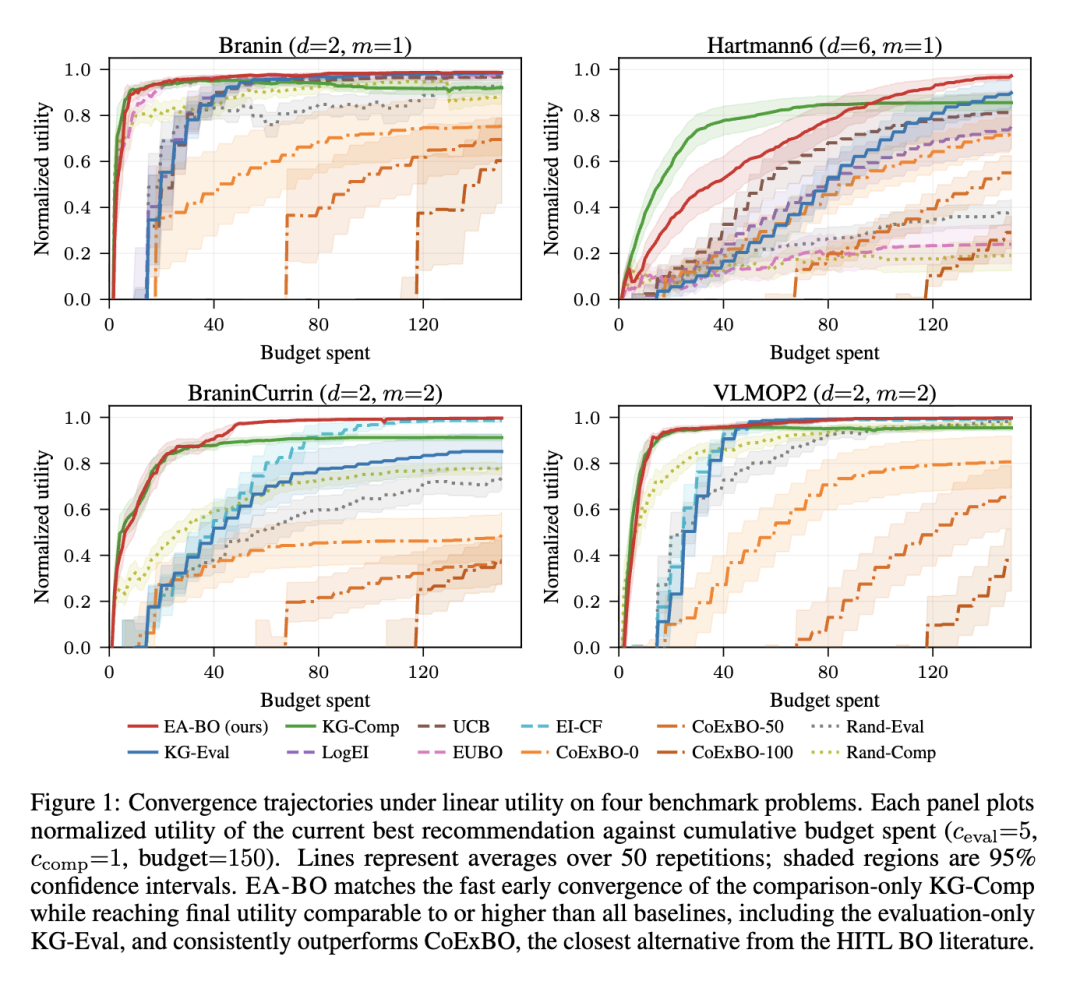
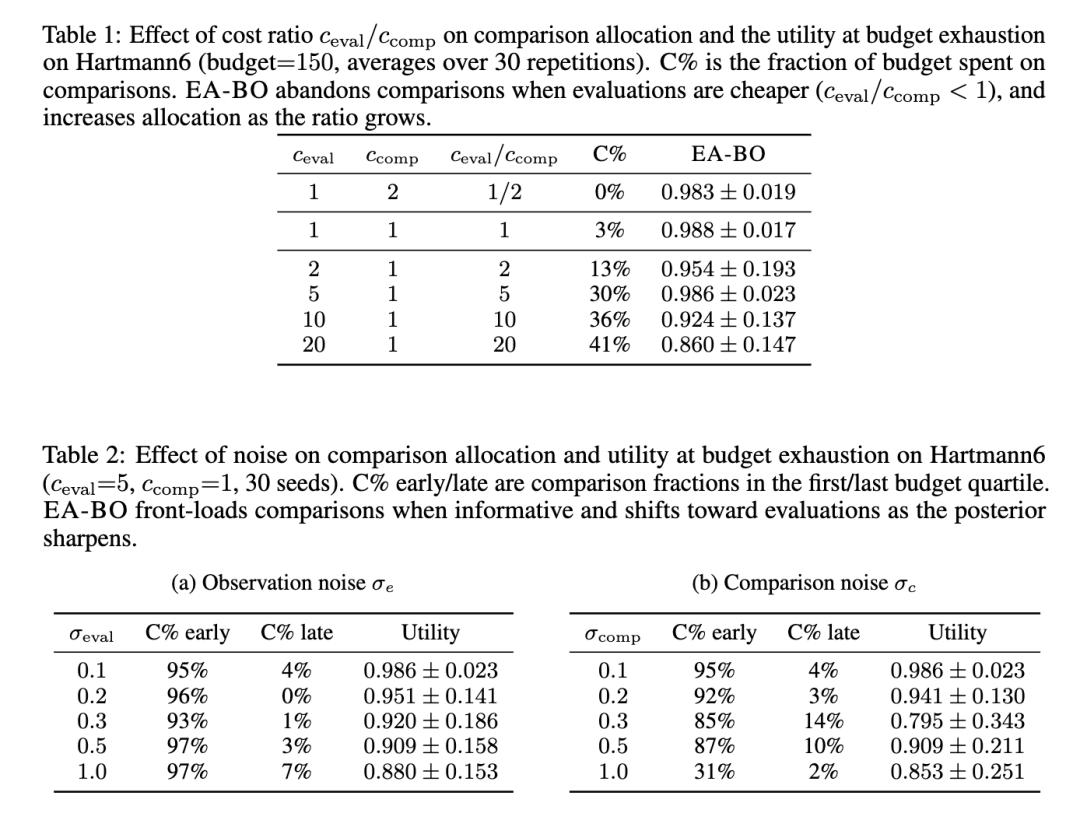
在所有单目标任务以及具有线性效用的多目标任务上,EA-BO 在预算耗尽时达到了最佳或统计上并列最佳的效用(见表 3,附录 C.1)。这种优势在 Hartmann6 (d=6) 上最为显著,在那里,较大的搜索空间增加了廉价比较用于早期探索的价值。
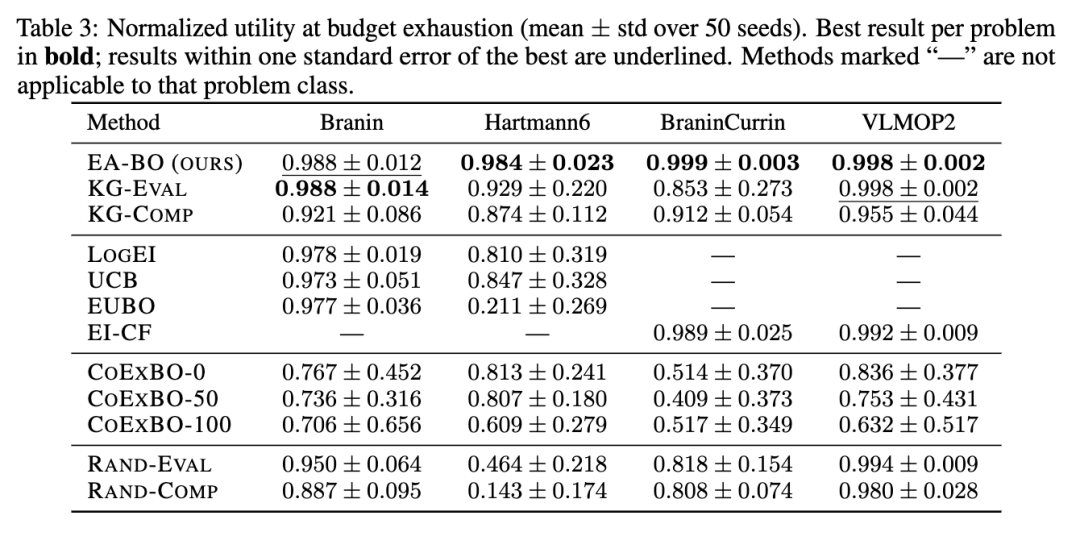
仅比较的方法(KG-Comp, EUBO)在高维情况下性能下降:成对比较仅提供二元信号。因此,随着维度 d 的增长,高精度近似后验分布所需的查询量显著增加。KG-Comp 优于 EUBO,这与 Wu 和 Gardner (2026) 的发现一致。仅评估的基线(LogEI, UCB, EI-CF)表现良好,但无法从更廉价的成对比较通道中获益。
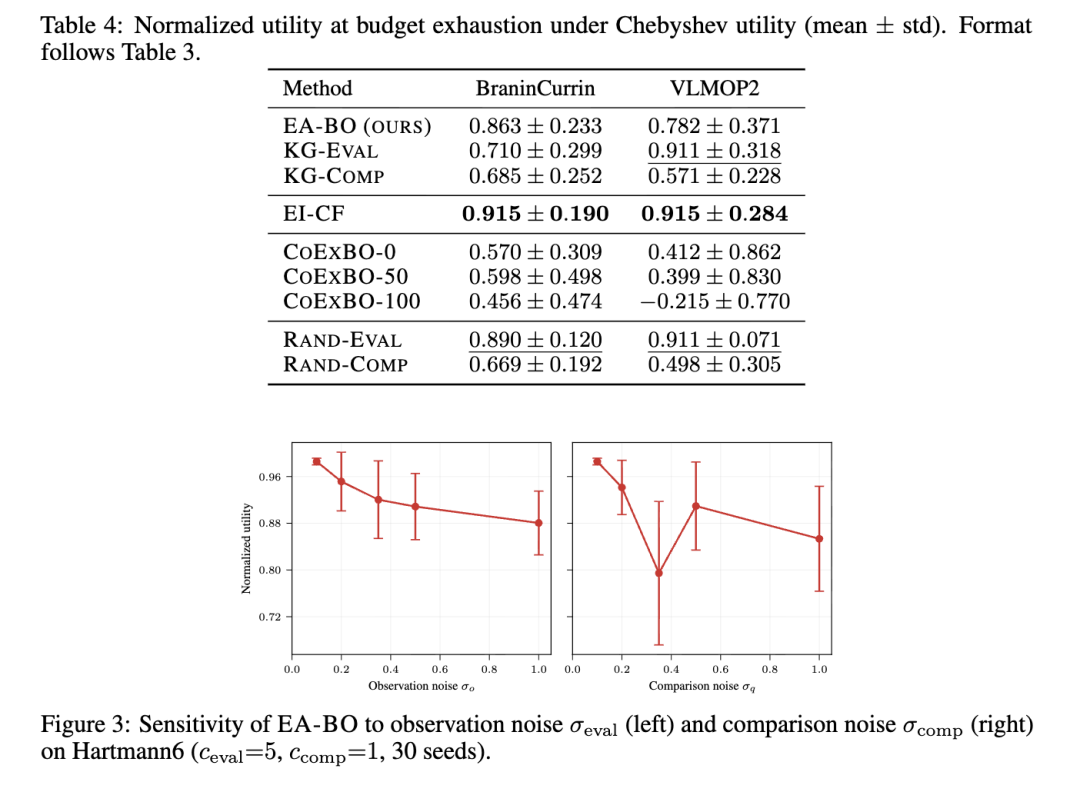
切比雪夫效用。 在切比雪夫效用下(表 4,附录 C.1;图 2),EA-BO 在早期阶段的提升速度再次快于仅评估的基线。在 BraninCurrin 上,EA-BO 在预算耗尽时的效用与 EI-CF 相当,同时明显优于 KG-Eval 和 KG-Comp。在 VLMOP2 上,EA-BO 在早期阶段比仅评估的基线 EI-CF 提升得更快,但在预算耗尽时被其超越。
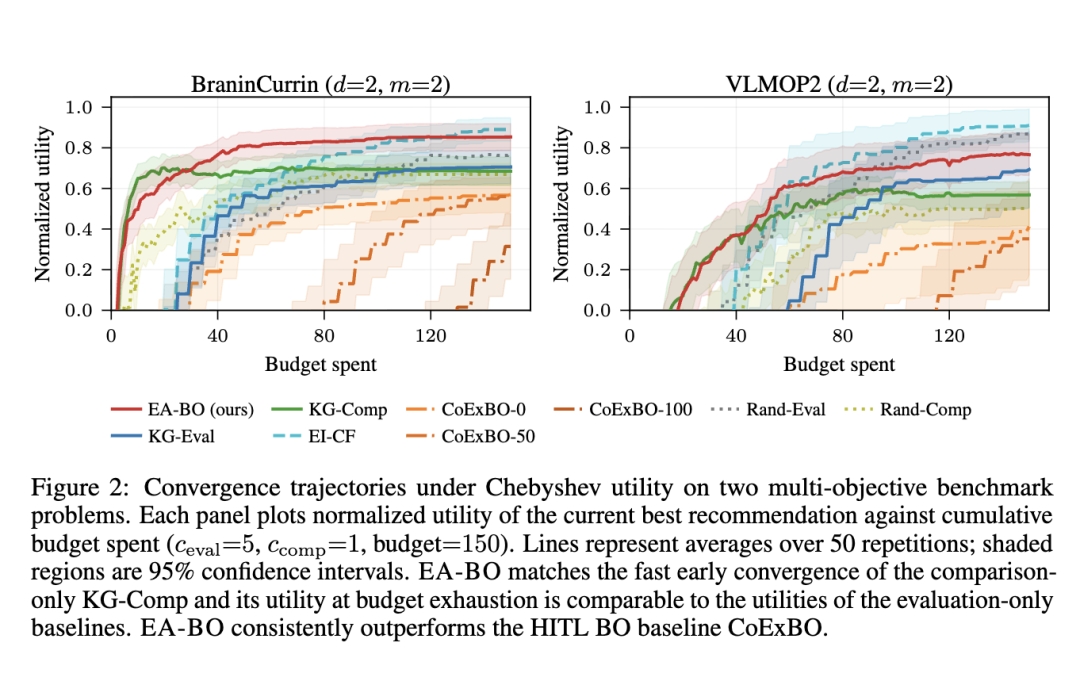
与 HITL BO 的比较。 EA-BO 在所有测试函数上均显著优于 CoExBO (Adachi et al., 2024) 的所有变体(图 1,表 3)。CoExBO 可选择用 50 或 100 次查询预训练其偏好模型(CoExBO-50/100);预训练提高了收敛速度,但在预算耗尽前,预训练所花费的成本无法被挽回。


7 讨论
我们提出了一种基于 GP 的贝叶斯优化(BO)方法,该方法将成对比较和直接评估都视为关于目标函数的噪声证据,并配有一个成本感知的 VoI 采集函数,用于在两个信息源之间自适应地分配预算。该方法在所有基准测试中匹配或超越了单源策略,在信息丰富时利用廉价的比较,在需要更高精度时回退到评估,并且优于那些也结合了两个信息源但间接使用比较的现有方法。

原文链接:https://arxiv.org/pdf/2605.12079
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号