思维系列-如何系统性地构建人工智能知识体系并进行学习实践?

思维系列-如何系统性地构建人工智能知识体系并进行学习实践?

人月聊IT
发布于 2026-05-29 12:31:21
发布于 2026-05-29 12:31:21
大家好,我是人月聊IT。
最近刚好在知乎看到一个问题,就是对于数学专业的学生来说,如何系统性的构建人工智能知识体系。这其实是个特别普遍的问题。AI 这个领域过去十年膨胀得太快了,论文一年几万篇,工具一年换一拨,新模型每个月都出。如果你一头扎进去乱学,大概率半年下来还是云里雾里。
但如果你是数学系出身,你其实有别人没有的先发优势。这篇文章我想以数学系大学生为对象,聊一聊到底应该怎么一步一步把人工智能这套知识搭起来——前期要做什么准备、基本骨架长什么样、后面怎么靠学习和项目慢慢长成自己的体系。
所以结合这个问题,包括我个人知识体系构建的整体方法论,来谈下如何系统性的构建一个人工智能的知识体系结构。
一、数学系学 AI,你的起点比别人高
先说一个让你松口气的事实:
AI 这个领域,数学基础好的人是有结构性优势的。
你看现在大家学 AI,卡住的地方往往不是写代码,而是底层的数学说不清楚。神经网络的反向传播是怎么回事?为什么 Adam 比 SGD 收敛快?为什么 Transformer 里要除以根号 d_k?这些问题,本质上都是数学题。你数学系四年学的东西——线性代数、概率论、数理统计、最优化、微积分——几乎对应着 AI 的所有数学底座。
但是,数学好不等于会做 AI。这点也得说在前面。
我见过太多数学系的同学,论文公式推得飞起,但让他写一段 PyTorch 训练模型,他卡在数据加载那一步。也见过有人懂梯度下降,但完全不知道实际工程里怎么调超参、怎么排查训练不收敛的 bug。
所以数学系学 AI,真正要做的是三件事:
- 守住数学这个优势,把它转化成对算法的深度理解
- 补上工程能力,让你能动手把想法变成可运行的代码
- 建立全景视野,知道当下 AI 的整个生态长什么样,别钻进单点出不来
接下来这篇文章,基本就是围绕这三件事展开的。
二、动手之前,先做三件事
我观察过很多人学 AI 学不下去,问题往往不是出在学习能力,而是出在"还没想清楚就开始学了"。所以正式扎进去之前,强烈建议先花两三天做这三件事。
第一件:想清楚你到底想干嘛
AI 是个特别大的领域,大致可以分成三个方向,要求差别很大:
- 应用方向:用现成的模型和工具做产品。比如基于大模型做问答系统、做 RAG、做 Agent。这个方向门槛相对低,工程能力比数学能力更重要。
- 工程方向:训练和优化模型。比如做 LLM 训练、模型压缩、推理加速。这个方向需要数学+工程双强,数学系挺适合。
- 研究方向:推动 AI 算法本身的进步。比如发论文、做新架构、探索 AGI。这个方向数学要求最高,但前提是你打算读研甚至读博。
你不需要现在就锁死方向,但至少要知道这三条路的差别,这样你看资料的时候不会迷失。
第二件:画一张属于你自己的 AI 知识地图
不要急着翻书。先在白纸上(或者一个思维导图工具里),画一张 AI 知识地图。把你听说过的所有概念——监督学习、神经网络、Transformer、大模型、强化学习、CNN、RNN、Diffusion、Agent——全都填进去,然后试着把它们按你目前的理解归类。
这张图刚开始一定是乱的、错的、有大量空白的,这都没关系。这张图的真正价值不在于它当下准不准,而在于它给你一个"我大概知道哪些不知道"的参照系。每过一个月,你可以拿出来重画一遍,看看自己进步在哪里。
第三件:盘点你自己的基本盘
拿一张纸,左边写"已经会的",右边写"还不会的"。比如:
- 数学基础(微积分、线代、概率统计):多半已经会了
- 优化理论:看课程内容,大概率学过
- Python:可能学过一点,但不熟练
- 机器学习基础:几乎全是空白
- 深度学习框架:从零开始
这个盘点很重要,它直接决定你接下来三个月该重点补哪块。不要把时间浪费在已经会的东西上,数学系学生最常见的错误就是把线性代数又刷一遍,而 Python 工程能力一直跟不上。
三、AI 知识体系的骨架长什么样
地图画好之后,真正开始搭骨架。在我看来,人工智能这套知识体系,可以拆成五大块,从底到上:
第一块:数学基础(地基)
这块对你来说基本不用从零学,但要做一个"转化"动作——把数学知识跟 AI 概念对应起来:
- 线性代数 → 神经网络的矩阵运算、嵌入空间、注意力机制
- 微积分 → 反向传播、梯度下降
- 概率论 → 贝叶斯、生成模型、不确定性建模
- 数理统计 → 模型评估、假设检验、采样方法
- 最优化 → 损失函数、SGD/Adam 优化器
- 信息论(可能没专门学过) → 交叉熵、KL 散度、互信息
建议你找一本《Deep Learning》(花书)的前几章过一遍,主要不是为了学新东西,而是看看你已有的数学怎么映射到 AI 里。
第二块:编程与工具(手脚)
这是数学系最容易短板的地方。要补的内容:
- Python 熟练度:别只会写脚本,要会写类、会用装饰器、会读别人的代码
- NumPy / Pandas:数据处理的基本工具
- PyTorch:现在的主流深度学习框架,优先学这个,TensorFlow 可以暂时不管
- Git:版本管理,做项目必备
- Linux 基础命令:服务器跑模型必备
这块没什么捷径,就是写。每天写 200 行代码,坚持 3 个月,就能从"会写"到"熟练"。
第三块:算法与模型(主体)
这是 AI 知识体系的主干,可以分三层:
- 经典机器学习:线性回归、逻辑回归、决策树、SVM、聚类、PCA。这些是基础,虽然现在工业界用得少了,但底层思想必须懂。
- 深度学习:CNN(图像)、RNN/LSTM(序列)、Transformer(现在的主流架构)、GAN/Diffusion(生成模型)、强化学习。
- 大模型相关:LLM 原理、Prompt 工程、RAG、Agent、多模态。
数学系的同学有一个很好的学法:**每学一个模型,先看公式推导,再看代码实现,最后想想"这个模型背后的数学直觉是什么"**。这个过程会让你的理解比一般人深一两个层次。
第四块:工程与应用(场景)
光会算法不行,得知道怎么把模型用起来:
- 数据工程:数据采集、清洗、标注、增强
- 训练工程:分布式训练、混合精度、显存优化
- 部署工程:模型压缩、推理加速、服务化
- AI 应用工程:RAG 系统、Agent 工作流、AI 编程工具的使用
这块多半要在实习或项目中才能真正学到,光看书很难懂。
第五块:前沿与生态(视野)
这一块不是"系统学习",而是"持续关注":
- 顶会论文(NeurIPS、ICML、ICLR、ACL、CVPR)
- 行业重要博客和报告(OpenAI、Anthropic、DeepMind)
- 开源项目(HuggingFace、LangChain、各种新框架)
这块更多是"刷"出来的,不是"学"出来的。每周花两小时关注一下,长期下来对你的视野提升很大。
四、从入门到精通,按这六个节奏来走
骨架有了,具体怎么学?我自己的经验是按六个阶段来走,千万不要跳步。
第一阶段:先粗看个全貌(2 周左右)
什么都别钻,就找一本入门书或者一套视频课,从头到尾过一遍。推荐的入门资源:
- B 站李宏毅老师的机器学习/深度学习课程(讲得通俗,有大量例子)
- 吴恩达的深度学习专项课
- 《动手学深度学习》
这个阶段的目标只有一个:对 AI 整个领域有个大致印象,知道每个名词是干嘛的,不求懂细节。
第二阶段:找出主干,理清核心概念(1 个月)
这一步开始啃硬骨头。把这些核心概念彻底搞懂:
- 什么是损失函数?为什么要最小化它?
- 反向传播到底在做什么?
- 过拟合是怎么发生的?怎么避免?
- 梯度下降和它的各种变体差别在哪?
- Attention 机制为什么有效?
这些问题你能用自己的话讲清楚,数学公式自己能推一遍,这个阶段就过了。
第三阶段:动手跑一个小项目(2 周)
最重要的一步。没有动过手的人,前面学的全是浮的。
随便挑一个简单的项目:
- 用 sklearn 做 Kaggle 的泰坦尼克号预测
- 用 PyTorch 写一个 MNIST 手写数字识别
- 训练一个简单的文本分类器
要求很简单:从零开始,到看到模型输出结果,全程自己写一遍。中间一定会卡壳,卡壳的地方就是你的真实弱点,记下来回头补。
第四阶段:系统补齐知识树(2-3 个月)
跑过一个项目后,你才有了"知识挂钩"。这时候再回头系统学,效率会高得多。这个阶段要做的事:
- 找一个完整的教材或课程,从头到尾认真学一遍
- 每个章节学完都要做练习
- 每个模型都自己实现一遍(哪怕是简化版)
推荐资源:CS229(斯坦福机器学习)、CS231n(计算机视觉)、CS224n(NLP)。这些课程难,但学下来体系就成型了。
第五阶段:持续迭代,做更复杂的项目(长期)
这时候你已经入门了。接下来就是用项目驱动学习:
- 复现一些经典论文(从简单到复杂)
- 参加 Kaggle 比赛
- 找个自己感兴趣的方向深入做一个项目
第六阶段:融会贯通
这是质变。表现是:
- 看到一个新模型,能很快理解它的核心思想
- 出了 bug,大概能猜到原因在哪
- 能跟别人深度讨论 AI 问题,不再只是听别人讲
这个阶段不是你"学到"的,而是积累到一定程度自然涌现的。到了这一步,你才能说自己真的入门了。
五、找融合点:让你的数学和 AI 真正打通
数学系同学最大的优势,不是数学好,而是能在 AI 知识和数学知识之间建立深层连接。这种连接建立得好,你的理解深度会远超那些"只学过 AI"的同学。
举几个具体的融合点:
线性代数 ↔ 神经网络
神经网络的前向传播,本质上就是一连串的矩阵乘法加上非线性激活。你学过的特征值、奇异值分解、向量空间这些概念,直接对应 AI 里的嵌入空间、降维、注意力机制的低秩近似。
概率统计 ↔ 机器学习
朴素贝叶斯、最大似然估计、贝叶斯推断,这些你在概率论课上学过的东西,直接就是 AI 里很多算法的理论基础。变分自编码器(VAE)、扩散模型(Diffusion),核心数学就是概率分布的近似和采样。
微积分 ↔ 优化算法
反向传播 = 链式法则。梯度下降 = 沿梯度反方向走。Adam、RMSProp 这些优化器 = 二阶矩估计 + 自适应学习率。你学的多元函数微积分,几乎每一页都能在 AI 里找到对应。
最优化理论 ↔ 模型训练
凸优化、KKT 条件、对偶问题——这些在 SVM、约束优化、强化学习里都有直接应用。
数理统计 ↔ 模型评估
假设检验、置信区间、A/B 测试——做 AI 实验和评估时,这些都是你的硬通货。
这种打通有什么用?
简单说,就是让你看 AI 模型的时候不再"看个表面"。你能透过代码看到背后的数学结构,透过数学结构看到模型为什么这样设计。这是数学系最该走的路径,也是别人短期内追不上的护城河。
具体怎么打通?我的建议是:每学一个新模型,逼自己问三个问题:
- 它对应的数学概念是什么?
- 这个数学概念我是哪门课学的?
- 这个数学概念在 AI 里还在哪些地方出现?
这三问回答多了,你的知识体系就开始长出网络了。
六、广度和深度,到底该怎么选?
学到中期你一定会面临一个困惑:AI 领域这么大,我是该广撒网,还是深扎一个方向?
这里我用一个比喻——沙堆模型:你的知识就像一堆沙,沙堆能堆多高代表深度,沙堆的底面积代表广度。没有足够的底面积,堆不出高度;但只有底面积没有高度,这堆沙也没什么用。
所以广度和深度不是非此即彼,而是有先后顺序的。
我的建议:
学习前期(前 6 个月):广度优先
不要急着选定方向。把 AI 的几个主流分支——CV、NLP、推荐、强化学习、大模型——都接触一遍。每个方向跑一个小项目,感受一下你对哪个方向真正有兴趣。
学习中期(6 个月到 2 年):选定 1-2 个方向深入
挑你最感兴趣、或者就业前景最好的方向,集中火力。这个阶段要做的事:
- 把这个方向的经典论文读一遍
- 做几个有挑战性的项目
- 试着复现 SOTA 论文
学习后期(2 年以后):再次拓宽
当你在一个方向有了深度之后,再回过头去看其他方向,你会发现很多东西是通的。这时候横向拓展的速度会快很多。
AI 时代的一个特别建议
现在 AI 工具(比如 Cursor、Claude Code、各种 AI 编程助手)能帮你处理很多深度细节工作。**但 AI 不能替你做"场景判断"和"方向选择"**。所以在 AI 时代,广度和方向感反而更值钱。
具体到数学系学生,推荐走 T 字形路径:
- 横向的"一":数学基础 + AI 各个主要分支的基本认知
- 纵向的"|":选 1 个方向(比如 LLM、强化学习、生成模型)深扎
- 交叉点:在交叉点上做出独特的东西
七、靠项目把知识盘活:学习-实践-复盘的循环
到这里你可能注意到一件事:前面讲的所有内容,只有跟实践结合,才真正变成你的。看书、看视频、刷课程,这些都只是输入。真正让知识沉淀的,是学习—实践—复盘这个循环。
具体怎么走:
第一步:学一个新东西后,马上找项目验证
刚学完 CNN?马上找个图像分类任务跑一遍。刚学完 Transformer?马上自己写一个简化版的文本生成。绝对不要"等学完再做",因为你永远学不完。
第二步:从复现到改造,再到原创
项目能力是一层一层长出来的:
- 复现:照着别人的代码或教程跑一遍
- 改造:在别人的基础上改一些细节,看看效果变化
- 原创:自己提出一个想法,从头实现
刚开始一定是从复现做起。不要看不起复现,复现别人的论文是最快的成长方式之一。
第三步:周期性复盘
这是被绝大多数人忽视的一步,但也是真正拉开差距的关键。
每个月、每个学期、每年,花一两天时间,把你最近做的所有事情、学的所有东西、做的所有项目,放到一起回顾:
- 我这段时间到底学会了什么?
- 哪些是真的懂了,哪些是浮的?
- 哪些方法以后还能用?
- 哪些项目沉淀出了可复用的代码或思路?
复盘的真正价值,不是回顾过去,而是把零散经验抽象成你自己的方法论。比如做了三个 CV 项目之后,你应该能总结出"做 CV 项目的通用流程",这种东西就是你的私有资产。
第四步:把复盘的东西写出来
写博客、做笔记、画思维导图——什么形式都行,关键是强迫自己把思考显性化。我自己的经验是:写不出来的东西,其实就是没真懂。写作的过程,就是逼自己把思维理顺的过程。
八、长期看,从知识库走到模式库
最后说说更长期的事。一两年学下来,你可能会发现自己的状态在变化——从"什么都要查"慢慢变成"很多东西凭直觉就能做对"。这个变化背后的本质是:你的知识开始从知识库进化成了模式库。
我自己理解的个人知识演进有四个阶段:
第一阶段:资料库
你只是在收集资料——存了一堆 PDF、收藏了一堆链接、关注了一堆公众号。这个阶段的特征是:信息很多,但没成体系,用的时候找不到。
第二阶段:知识库
你开始系统整理,有自己的笔记结构,有自己的分类。这个阶段的特征是:知识有了体系,但还停留在"懂"的层面,实战上手会卡。
第三阶段:经验库
你做过很多项目了,踩过很多坑,知道哪些地方容易出问题。这个阶段的特征是:遇到具体问题能上手,但说不出"为什么这样做对"的通用规律。
第四阶段:模式库
你能从一系列经验里抽象出通用的方法论。看到新问题,你不再是从头思考,而是自动匹配到某个你已有的模式,稍作调整就能用。这个阶段的特征是:面对未知问题也有套路,你的判断和决策开始变得高效而准确。
绝大多数人停在第二、第三阶段,极少数人能到第四阶段。能到第四阶段的人,就是别人眼里"特别厉害"的那种人。
怎么走向模式库?
核心动作就一个:周期性的深度复盘 + 持续的显性化输出。
具体说:
- 每次做完一个项目,问自己:"这件事下次能不能更快做完?要总结出一个通用方法吗?"
- 每隔一段时间,把你做过的多个类似项目放在一起对比:"它们的共性是什么?能不能抽象出一个模板?"
- 把这些抽象出来的方法论,写成文档、画成图,变成你随时能调用的资产
这件事在 AI 时代尤其重要。因为 AI 工具能帮你处理具体任务,但真正决定你水平的,是你脑子里的模式库——它决定你能给 AI 提什么样的问题、能审视 AI 给出的什么样的答案、能在 AI 给出的多个方案里选哪个。
下面我们构建一个完整的AI知识体系架构并进一步说明。
人工智能知识体系架构图说明
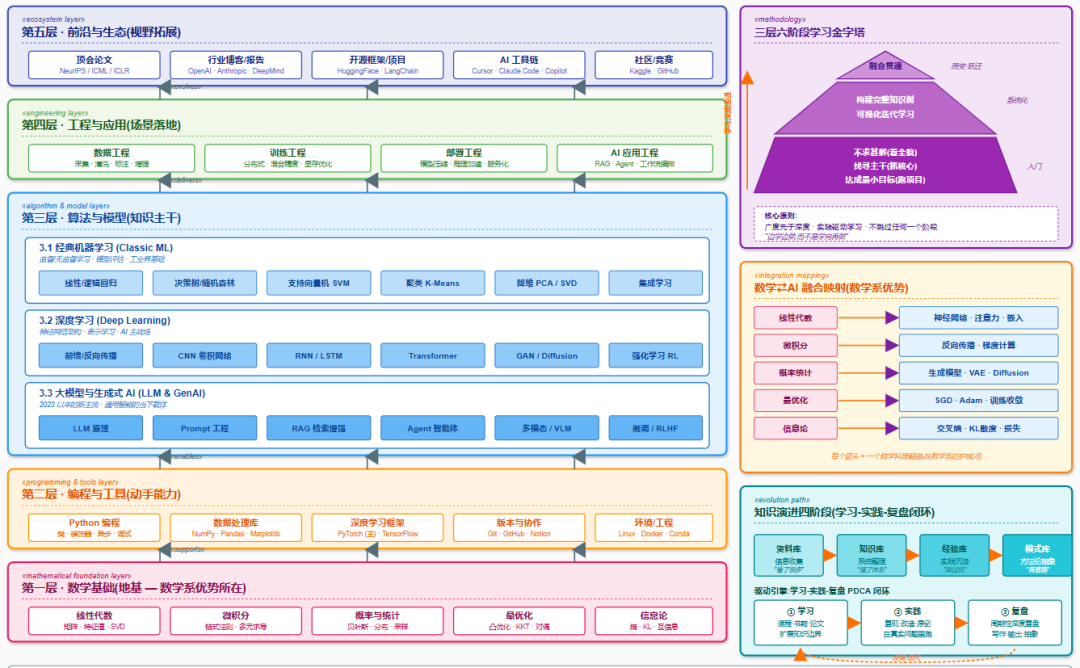
一、这张图想解决什么问题
学 AI 最容易遇到的一个困境是:网上资料太多,看着看着就乱了。今天看 Transformer,明天看 RAG,后天又被 Diffusion 吸引,到最后脑子里堆了一堆名词,但拼不出一张完整的图。
这张架构图想做的事其实很简单——用一张图把人工智能这个领域的整体结构画清楚:
- 哪些是地基,必须先打牢
- 哪些是主干,要花最多时间
- 哪些是应用,等基础有了再上
- 哪些是前沿,平时关注就行
- 不同模块之间是什么关系
- 学的时候按什么节奏走
- 怎么把已有的数学知识跟 AI 打通
整张图分成左边的 5 层主结构和右边的 3 个补充视图两大部分。左边告诉你"AI 有哪些东西",右边告诉你"应该怎么学"。两边合起来才是完整的方法。
下面一层一层来说。
二、左侧 5 层主结构 — AI 知识的金字塔
这 5 层是按"地基→主干→应用"的顺序堆起来的。底层是上层的基础,所以学习顺序也是从下往上。
第一层:数学基础(粉色 — 地基)
这一层是整个 AI 大厦的地基,包括五块内容:线性代数、微积分、概率与统计、最优化、信息论。
对数学系的同学来说,这一层基本是你已经会的——前四个都是必修课,信息论可能没专门学过,但概念上不难理解。
但要注意一件事:数学课本上的知识,和它在 AI 里的用法,是两件事。你需要主动把"教科书数学"翻译成"AI 数学":
- 矩阵乘法不只是练习题,它就是神经网络的前向传播
- 求导不只是为了算极值,它就是反向传播的核心
- 概率分布不只是公式推导,它就是生成模型的基础
这种"翻译能力",是数学系学生学 AI 的真正起点。
第二层:编程与工具(橙色 — 手脚)
这一层是把数学想法变成代码的能力,包括:**Python 编程、数据处理库(NumPy/Pandas)、深度学习框架(PyTorch)、版本管理(Git)、环境工程(Linux/Docker)**。
这块往往是数学系最大的短板。你可能数学推导很溜,但写代码卡在数据加载、调 bug、配环境上。这一层没什么捷径,就是写。我的建议是每天写 200 行代码,坚持 3 个月,差距会自然抹平。
特别注意 PyTorch 优先,TensorFlow 现在重要性下降很多,初学者别两个都学。
第三层:算法与模型(蓝色 — 主干)
这是整个架构图里最大的一块,也是你要花最多时间的地方。它内部又分成三个递进的子层:
3.1 经典机器学习:线性回归、逻辑回归、决策树、SVM、聚类、降维、集成学习。这些虽然在工业界用得少了,但底层思想必须懂——它们是你理解深度学习的基础。
3.2 深度学习:从最基础的前馈/反向传播,到 CNN(图像)、RNN/LSTM(序列)、Transformer(现在的主流架构),再到 GAN/Diffusion(生成模型)、强化学习。Transformer 是重中之重,所有现代大模型都建立在它之上。
3.3 大模型与生成式 AI:LLM 原理、Prompt 工程、RAG、Agent、多模态、微调/RLHF。这部分是 2023 年以来 AI 的新主战场,变化最快,但也是当下最值钱的方向。
这三个子层的关系是递进的:经典机器学习的思想被吸收到深度学习里,深度学习的架构(尤其 Transformer)被发展成了大模型。不要跳过经典机器学习直接学大模型,虽然能用但理解不深。
第四层:工程与应用(绿色 — 场景)
光会算法不行,得知道怎么把模型用起来。这一层包括四块:数据工程、训练工程、部署工程、AI 应用工程。
- 数据工程:采集、清洗、标注、增强。脏数据是 AI 项目最大杀手。
- 训练工程:分布式训练、混合精度、显存优化。模型一变大就用得上。
- 部署工程:模型压缩、推理加速、服务化。从训练到生产的关键一步。
- AI 应用工程:RAG、Agent、工作流编排。这是大模型时代的"新前端"。
这层多半要在实习或项目里才能真正学到,光看书很难懂。建议大三大四阶段通过实习补这块。
第五层:前沿与生态(靛蓝色 — 视野)
最顶层是开放视野,包括:顶会论文、行业博客、开源框架、AI 工具链、社区竞赛。
这一层的特点是"不需要系统学,但要持续刷"。每周花 2 小时关注一下,长期下来对你的方向感和判断力影响很大。
具体看什么?
- 顶会:NeurIPS、ICML、ICLR、ACL、CVPR
- 博客:OpenAI、Anthropic、DeepMind 的技术博客
- 开源:HuggingFace 模型库、LangChain、各种新框架
- 工具:Cursor、Claude Code、GitHub Copilot 这些 AI 编程工具(数学系也得用)
- 社区:Kaggle 比赛、GitHub 项目
三、层间关系 — 4 类支撑关系
架构图里 5 层之间不是孤立的,它们之间有 4 种递进的支撑关系,在图上用向上箭头加 «构造型» 标签表示:
关系 | 含义 | 通俗解释 |
|---|---|---|
数学 «supports» 编程 | 数学为编程提供理论支撑 | 你为啥要学这个库?因为它在算这个数学 |
编程 «enables» 算法 | 编程能力让你能跑算法 | 没有代码,算法只是纸上谈兵 |
算法 «delivers» 应用 | 算法被工程化交付到场景 | 模型只有用起来才有价值 |
应用 «evolves» 生态 | 应用反过来推动生态演进 | 真实场景的需求催生新论文新工具 |
理解这些关系最关键的一点是:下层是上层的必要条件,但不是充分条件。数学好不代表代码好,代码好不代表算法理解深,算法理解深也不代表能落地。每一层都要单独投入,不要以为前一层做好了下一层就自动会。
四、右侧三个侧边栏 — 学习方法的三大法宝
如果说左边告诉你"学什么",右边就告诉你"怎么学"。这三个侧边栏分别对应三个层次的方法论。
侧边栏 1:三层六阶段学习金字塔(紫色)
这是一个用真正的金字塔形状画出来的学习路径,从底到顶三层:
基础认知层(底) — 三个阶段:
- 不求甚解:先看整体全貌,不钻细节(用 2 周快速通读一本入门书)
- 找寻主干:抓住核心概念,搞清楚关键名词到底什么意思
- 达成最小目标:立马跑一个项目,哪怕是 MNIST 这种最简单的
体系构建层(中) — 两个阶段:
- 构建完整知识树:有了第一手经验后,系统补齐知识体系
- 可视化迭代学习:把进度、笔记、思维导图都呈现出来
跃迁突破层(顶) — 一个阶段:
- 融会贯通:量变到质变,知识真正内化成你的能力
这个金字塔最关键的原则是:广度先于深度、实践驱动学习、不跳过任何一个阶段。最容易犯的错误就是想直接跳到第 4 步——结果连第 3 步都没跑过,体系是搭不起来的。
侧边栏 2:数学⇄AI 融合映射(琥珀色)
这是数学系学生的"专属作弊码"。图里画了五条横线,每条线连接一个数学领域和一个 AI 概念,直接把你的数学优势映射到第三层算法核心:
数学(你已经会的) | → | AI(你要学的) |
|---|---|---|
线性代数 | → | 神经网络 · 注意力 · 嵌入 |
微积分 | → | 反向传播 · 梯度计算 |
概率统计 | → | 生成模型 · VAE · Diffusion |
最优化 | → | SGD · Adam · 训练收敛 |
信息论 | → | 交叉熵 · KL散度 · 损失函数 |
**每一条线都是一个"理解锚点"**。你学到任何一个 AI 概念,都应该回过头问自己:它对应我学过的哪个数学概念?这个动作做多了,你的理解深度会远超那些"只学过 AI"的同学。
这就是数学系学 AI 的护城河——别人是在背"这个公式干嘛用",你是在认"这就是我学过的那个东西"。
侧边栏 3:知识演进四阶段 + 学习-实践-复盘闭环(青色)
最后一个侧边栏讲的是长期的知识沉淀路径。
从资料库到模式库的四阶段递进:
- 资料库:信息收集阶段,看了很多 PDF、收藏了很多链接
- 知识库:开始系统整理,有自己的笔记结构
- 经验库:做过项目,踩过坑,有实战手感
- 模式库:能从经验里抽象出通用方法论,看到新问题自动匹配套路
绝大多数人停在第二、第三阶段,极少数能到第四阶段。能到第四阶段的人,就是别人眼里"特别厉害"的那种人。
下方的学习-实践-复盘三步闭环是驱动你从资料库走到模式库的引擎:
- 学习:课程/书籍/论文,扩展知识边界
- 实践:复现/改造/原创,在真实问题里跑一遍
- 复盘:周期性深度复盘,写作输出,完成抽象
特别强调周期性复盘——不只是做完一个项目复盘,而是每季度、每半年把多个项目放在一起共同抽象,这才是从经验跃迁到模式库的关键动作。
五、底部图例 — 怎么读这张图
图最下方的图例区把所有视觉元素都标出来了。简单说,看这张图有三步:
第一步,从下往上看左边主结构:先看清楚 5 层金字塔,理解"数学是地基、算法是主干、应用是落地"的支撑关系。
第二步,看右边三个侧边栏:理解学习方法(怎么学)、跨学科融合(怎么用数学优势)、长期演进(怎么沉淀)。
第三步,数学系特别提示:第一层是你的起点,通过中间的融合映射,直达第三层算法核心——这是你区别于普通学习者的捷径。
六、给数学系学生的具体使用建议
这张图不是看完就结束了。它真正的用法是当一张"地图",在你学习过程中不断对照。
入门期(前 3 个月) — 用图做盘点:
- 把图打印出来,在你已经会的模块上打勾
- 在你完全不会的模块上画叉
- 这就是你接下来要补的清单
进阶期(3-6 个月) — 用图找路径:
- 按第二个侧边栏(金字塔)的六阶段顺序走
- 每完成一个阶段,在图上对应的模块上标记进度
- 不要跳阶段,不要跳层
实战期(6 个月以后) — 用图找融合点:
- 重点看第二个侧边栏的数学融合映射
- 每学一个新算法,主动追溯它对应的数学根源
- 每过一段时间问自己:我的模式库里又多了什么?
长期(1 年以上) — 用图做迭代:
- 每个季度回顾一次这张图
- 看自己在哪些模块有了深入,哪些还浮在表面
- 把新发现的连接、新的工具、新的方向补到图上
- 这张图本身也应该跟着你一起进化
七、几个常见误区
最后聊几个数学系学 AI 最容易犯的错,也是这张图想帮你避开的:
误区一:数学好 = 会做 AI
很多数学系同学觉得自己数学好,学 AI 应该不难。结果一动手发现写代码、配环境、调超参全是坑。数学是必要条件,不是充分条件。这张图把编程工具单独列一层,就是为了提醒你这块不能省。
误区二:跳过经典机器学习直接学大模型
现在大模型这么火,很多人想直接学 LLM。但你跳过经典机器学习和深度学习基础,大模型的很多概念就是空中楼阁——你不懂梯度下降,怎么理解 RLHF?你不懂 Attention,怎么改进 Transformer?主干必须按顺序长。
误区三:只学不做
刷了 10 门课,做了 0 个项目。这是最常见的失败模式。架构图的金字塔里第 3 阶段就强调"达成最小目标",意思是学完任何一块都要跑一个最小项目验证,不要等"学完了再做"——你永远学不完。
误区四:只做不复盘
跟上一个相反,有些人项目做了不少,但从来不停下来抽象总结。这种人能解决具体问题,但永远到不了模式库这个层级。每隔一段时间一定要停下来周期性复盘。
误区五:沉迷工具忘了本质
这两年 AI 工具迭代太快,Cursor、Claude Code、各种 Agent 框架层出不穷。很多人成了"工具爱好者",每天追新工具但对底层算法越来越生疏。工具是表面,数学和算法才是核心。AI 工具帮你省时间,但不能替代你的底层理解。
八、结语 — 把图变成你自己的
这张架构图代表的是一个通用框架,不是终点。每个人的学习路径都不一样,你的兴趣、目标、时间分配都会让你的实际路径偏离这张标准图。
真正的目标是:用这张图作为起点,慢慢长出属于你自己的 AI 知识体系图。
一年以后,你应该有一张比这张更详细、更个性化、更适合你的图。上面标着你深入研究过的方向、踩过的坑、积累的项目、形成的方法。那张图才是你真正的核心竞争力。
人工智能这个领域大、变化快,谁都不可能"学完"。但只要方向对、节奏对、方法对,你就能持续生长出自己的体系。今天画下的第一笔,就是这个体系的起点。
祝你早日构建出真正属于自己的人工智能知识地图。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号