
如何规范混淆矩阵?
我使用confusion_matrix()为我的分类器计算了一个混淆矩阵。混淆矩阵的对角线元素表示预测的标签与真实标签相等的点数,而非对角线元素则表示被分类器错误标记的点数。
我想规范我的混淆矩阵,使它只包含0到1之间的数字。我想从矩阵中读取正确分类样本的百分比。
我找到了几种方法来规范矩阵(行和列规范化),但我对数学不太了解,也不确定这是否是正确的方法。
回答 9
Stack Overflow用户
发布于 2014-01-04 14:35:02
我假设M[i,j]代表Element of real class i was classified as j。如果是相反的话,你需要把我说的每句话都转过来。我还将使用以下矩阵作为具体示例:
1 2 3
4 5 6
7 8 9基本上,你可以做两件事:
查找每个类是如何被分类的
您可以问的第一件事是,实际类i中的元素百分比被归类为每个类。为此,我们使用一行修复i,并将每个元素除以行中元素的总和。在我们的例子中,类2的对象被分类为1 4次,正确地被归类为2 5次,被归类为3 6次。为了求百分比,我们只是把所有的东西除以4+5+6= 15。
4/15 of the class 2 objects are classified as class 1
5/15 of the class 2 objects are classified as class 2
6/15 of the class 2 objects are classified as class 3找出哪些类负责每种分类
您可以做的第二件事是查看分类器中的每个结果,并询问这些结果中有多少来自每个实际类。它将类似于另一种情况,但列而不是行。在我们的示例中,我们的分类器返回"1“1次,当原始类为1,4次,当原始类为2,7次时,当原始类为3。
1/12 of the objects classified as class 1 were from class 1
4/12 of the objects classified as class 1 were from class 2
7/12 of the objects classified as class 1 were from class 3--
当然,我给出的这两种方法一次只适用于单个行列,我不确定在这种形式中修改混淆矩阵是否是个好主意。但是,这应该会给出您正在寻找的百分比。
Stack Overflow用户
发布于 2014-01-05 06:22:24
假设
>>> y_true = [0, 0, 1, 1, 2, 0, 1]
>>> y_pred = [0, 1, 0, 1, 2, 2, 1]
>>> C = confusion_matrix(y_true, y_pred)
>>> C
array([[1, 1, 1],
[1, 2, 0],
[0, 0, 1]])然后,要了解每个类有多少样本收到了正确的标签,您需要
>>> C / C.astype(np.float).sum(axis=1)
array([[ 0.33333333, 0.33333333, 1. ],
[ 0.33333333, 0.66666667, 0. ],
[ 0. , 0. , 1. ]])对角线包含所需的值。计算这些值的另一种方法是认识到,您正在计算的是每个类的召回量:
>>> from sklearn.metrics import precision_recall_fscore_support
>>> _, recall, _, _ = precision_recall_fscore_support(y_true, y_pred)
>>> recall
array([ 0.33333333, 0.66666667, 1. ])类似地,如果除以axis=0上的和,则得到精度(具有基本真理标签k的类-k预测的分数):
>>> C / C.astype(np.float).sum(axis=0)
array([[ 0.5 , 0.33333333, 0.5 ],
[ 0.5 , 0.66666667, 0. ],
[ 0. , 0. , 0.5 ]])
>>> prec, _, _, _ = precision_recall_fscore_support(y_true, y_pred)
>>> prec
array([ 0.5 , 0.66666667, 0.5 ])Stack Overflow用户
发布于 2019-08-11 11:03:01
使用Seaborn,您可以轻松地使用heathmap打印一个标准化的、相当混乱的矩阵:
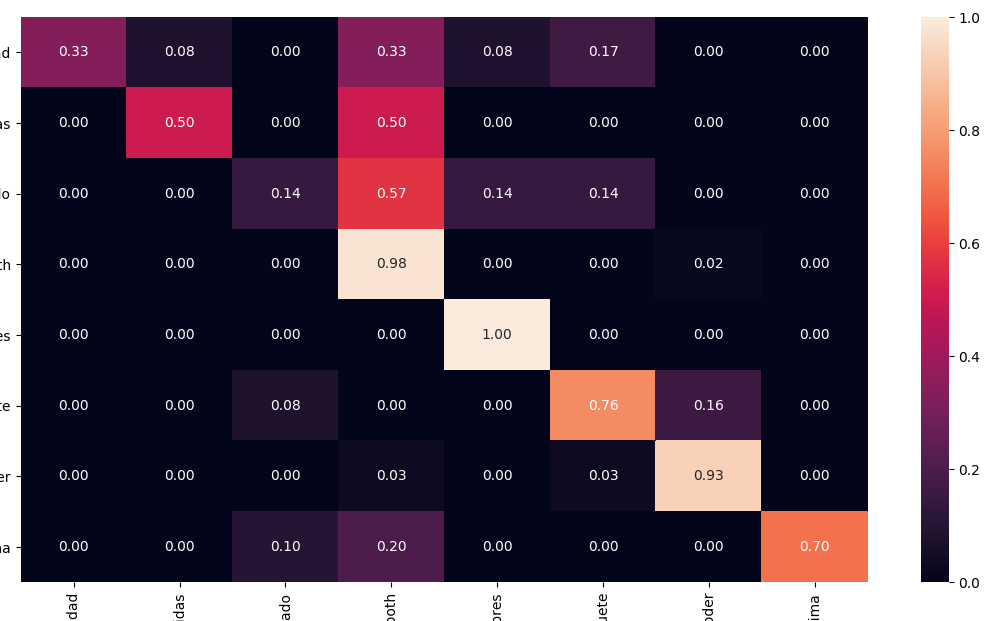
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_test, y_pred)
# Normalise
cmn = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(cmn, annot=True, fmt='.2f', xticklabels=target_names, yticklabels=target_names)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.show(block=False)https://stackoverflow.com/questions/20927368
复制





![【Groovy】Groovy 方法调用 ( 使用 对象名.成员名 访问 Groovy 类的成员 | 使用 对象名.‘成员名‘ 访问类的成员 | 使用 对象名[‘成员名‘] 访问类成员 )](https://developer.qcloudimg.com/http-save/yehe-2542479/0c0ed16739e62d10b7d93e184bffaf88.png)
相似问题
如何在json数据中动态添加属性和值
如何在字典值中添加前缀和后缀
Map<String,String[]>;属性(如键和值对)的JSON
在json属性名中添加下划线前缀
前缀JSON值- JSON/JQuery
腾讯云开发者
