华为提出QA-LoRA:让微调大型语言模型‘轻装上阵’

华为提出QA-LoRA:让微调大型语言模型‘轻装上阵’

zenRRan
发布于 2023-10-09 14:54:58
发布于 2023-10-09 14:54:58
深度学习自然语言处理 原创 作者:Winnie
近些年,大型语言模型(LLMs)表现出了强大的语言理解能力。但是,想要将这些模型应用到不同的场景,并部署到边缘设备(例如手机)上,我们还面临一个重要的问题:这些模型通常参数众多,计算负担重,如何在不损失性能的情况下让它们变得“轻量”并适应不同需求呢?
今天为大家介绍一篇来自华为的最新研究——QA-LoRA技术,为微调LLMs带来了一个轻量又高效的新选择。

Paper: QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models Link: https://arxiv.org/abs/2309.14717
背景
LLMs在自然语言处理领域取得了令人瞩目的成果,成为了多种任务的先进技术。
但是,它们在实际应用中的部署受到了其在推理期间的高计算和内存需求的限制。
目前,有两种主流的解决方法解决这些问题:
- 参数高效的微调(PEFT):这种方法在微调模型的时,只调整其中一小部分参数,而大部分预训练的参数则保持不变。其中,低秩适应(LoRA)是最受欢迎的方法,它的主要思想是将适应器权重分解为两个低秩矩阵的乘积。尽管这样可以得到不错的性能,但模型的内存占用依然很大。
- 参数量化:量化旨在减少LLMs的参数或激活的位宽,从而提高其效率和可伸缩性。简而言之,就是将模型的权重参数从浮点数转化为整数,从而使模型更小更快。但当我们压缩得过猛,比如使用非常低的位数来表示时,模型的准确率会大打折扣。此外,还有一个主要的挑战是如何处理参数分布中的异常值,因为它们在量化时可能导致重大错误。
因此,很多研究者开始考虑如何将上述两种方法结合起来,即既微调又量化。一个简单的尝试是先进行PEFT微调,然后再量化,但这样做得到的模型准确性很差。而其他的尝试,要么在微调时计算太复杂,要么在微调后无法保持模型的量化状态。
最近,来自华为的研究人员提出一种新方法:量化感知低秩适应(Quantization-aware Low-rank Adaptation, QA-LoRA)。这个方法的核心思想是,为每一组预训练的权重参数引入一个调节因子,既可以增加量化的自由度,也可以减少微调的自由度。这样做有两个好处:首先,在微调过程中,模型的权重可以被量化,使得微调更加高效;其次,微调完成后,得到的模型更小,而且无需进行后续的量化处理。
实验结果表明,它不仅在各种语言理解任务上表现得很好,而且相比于其他方法,它的效果更加稳定且高效。与先前的适应方法(如LoRA和QLoRA)相比,QA-LoRA在微调和推断阶段都具有计算效率。更重要的是,由于不需要进行后训练量化,所以它不会导致准确性损失。因此,QA-LoRA为我们提供了一个简单有效的解决方案,帮助我们同时实现模型的量化和微调。

LoRA回顾
在介绍QA-LoRA之前,让我们先来回顾下LoRA方法。
LoRA(Low-Rank Adaptation)算法的主要思想是在预训练权重的基础上,通过引入一对低秩矩阵A和B,来在微调阶段对模型参数进行高效的调整。
在 LoRA 中,我们使用预训练权重形成一个矩阵
,并假定特征形成一个向量
。我们假设
的大小为
,并且
的长度为
,因此计算可以简写为
,其中
是一个长度为
的输出向量。
LoRA 的关键思想是引入一对矩阵A和B,作为
的补充。A和B的大小分别为
和
,因此它们的乘积AB与
具有相同的大小。中间维度
通常设置为一个较小的值,即
,使得AB成为一个与
相比的低秩矩阵。
在微调过程中,我们计算
,其中
是权重调整的系数,并且在微调时
是固定的,而A和B可以进行调整,从而达到参数高效微调的目标。在微调后,计算被重新表述为
,其中
被
替代,以便快速推断。
LoRA 算法的核心价值在于,通过A和B的调整而不是直接调整
,它能够在减少模型复杂性和计算成本的同时,实现模型微调的效果。特别在处理大型预训练模型时,LoRA提供了一种参数高效的微调策略。
低位量化
在减少计算成本方面,另一种有效方法是低位量化。在本文中,我们只考虑权重的量化。特别地,我们应用了一个简单的方法,叫做最小最大min-max量化。从数学上讲,给定位宽
和一个预训练的权重矩阵
,我们计算
所有元素的最小值和最大值,分别记为
和
。然后,通过计算
将
量化为
,其中
分别称为缩放因子和零点因子;
表示整数四舍五入操作。所有
中的元素都在集合
中,因此存储为B位整数。
计算
被近似为
。量化带来了两方面的好处,即
的存储量减少和
的计算变得更快。代价是
是
的近似,这可能损害语言理解的准确性。
为了减少
和
之间的量化损失,一种有效的策略是对
的每一列执行单独的量化。设
,其中
和
是迭代变量。
设
和
分别是在第
列,
上计算的缩放因子和零点因子。因此,方程更新为
,并且计算被重写为
。
与整体量化相比,计算成本不变,而缩放和零点因子的存储成本从2个浮点数增加到
个浮点数。与存储全精度
的减少成本相比,这是可以忽略的。
QA-LoRA概览
QA-LoRA旨在实现两个目标。首先,在微调阶段,预训练的权重W被量化为低位表示,使得LLMs可以在尽可能少的GPU上进行微调。其次,在微调阶段之后,经过微调和合并的权重W′仍然是量化形式,因此LLMs可以具有计算效率地被部署。
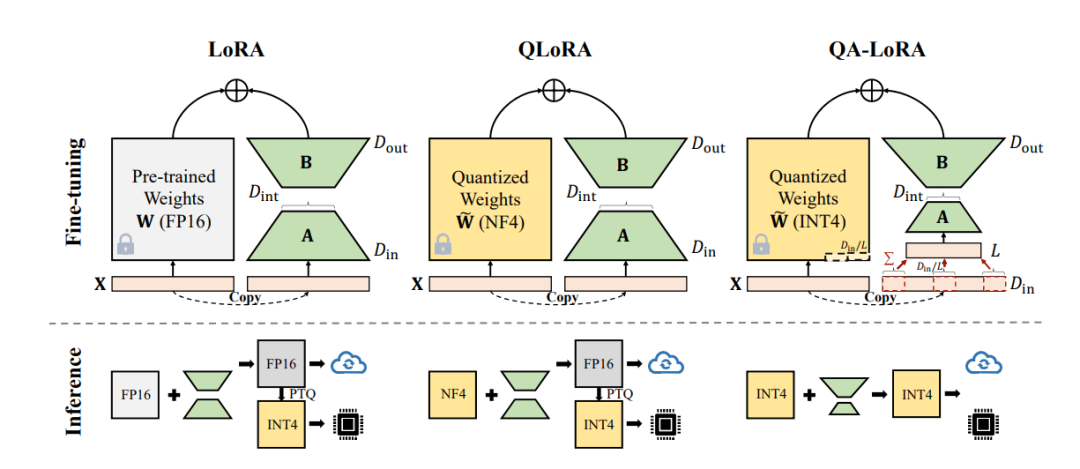
最近提出的LoRA变种QLoRA已经实现了第一个目标。其思想是在微调阶段将W从FP16量化为NF4(一种高度压缩的浮点数类型)。受到QLoRA的启发,LoRA和量化一起优化是可行的,因为W和W˜ 之间的准确性损失被低秩权重
补偿了。微调之后,
必须再次加回到W˜ 中,使得最终的权重W′为 FP16。实际上,人们可以对W′执行后训练量化(PTQ),但这种策略在位宽较低时可能导致准确性的大幅损失。此外,NF4还没有运算符级优化,这使得加速微调和推断阶段变得困难。简而言之,QLoRA带来的唯一好处是减少了微调的内存成本。
实现第二个目标的关键在于
(即量化的
)和
可以合并,而无需使用高精度数字。在原始设置中这是不可能的,即
按列方式量化为
,而
和
都是不受限制的。
由于
,
这里,对任意的
,所有
使用相同的缩放和零点因子集来表示,即存在
和
使得
在每个
加上
(简写为
)后,如果我们想保持量化的属性,我们必须保证对于任意
,所有可能的
值形成一个公差为
的等差集。在连续和基于梯度的优化中这是棘手的,除非我们要求
是一个常数,即
,对任意
。这等效于将
的所有行向量设置为相同的,即
,其中
表示两个向量之间的按元素等价。
上述策略虽然可行,但在实践中导致了显著的精度下降。特别是,当
的所有行都是相同的向量时,我们有
,因此
,而
的秩与在新数据中微调
的能力有关。为了解决这个问题,一个直接的想法是放宽量化和适应的约束。
我们将
的每一列划分为
组,为了方便实施,我们设
为
的一个因数。我们不是完全量化
的每一列,而是使用一对量化的缩放和零点因子,即第
组因子
和
,它们是为
-th列中的
个元素计算的。相应地,我们只要求
中同一组的行向量具有相同的值。在我们的实施中,这通过在输入向量
的每一组内做求和来实现。这个无参数的操作将
的维数从
减小到
,因此我们可以设
为
矩阵,而不需要进一步的约束。
提出的方法被命名为量化感知低秩适应(QA-LoRA)。与基线LoRA和QLoRA相比,它是通过插入/修改几行代码实现的,如下图所示。
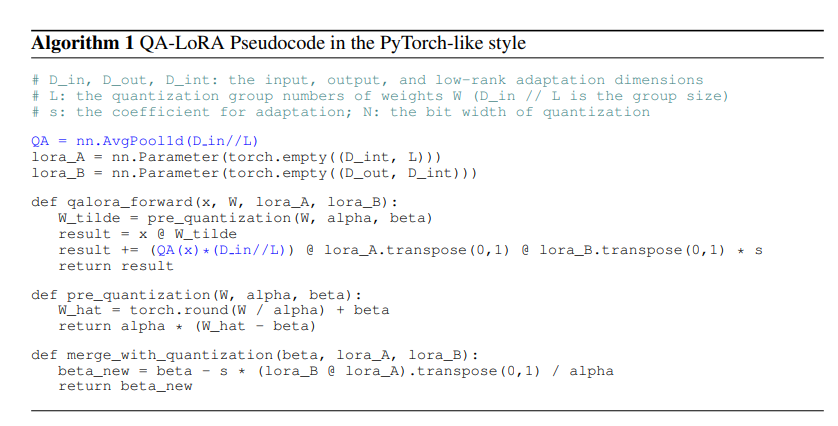
与LoRA相比,QA-LoRA在时间和内存消耗方面具有优势。与QLoRA相比,QA-LoRA需要额外的存储空间用于
对缩放和零点因子,但将
的参数数量从
减小到
——由于我们通常设
,上述变化是可以忽略的。与QLoRA相比,QA-LoRA的主要优势在于推理阶段,它更快、更准确。
下表中比较了LoRA、QLoRA和QA-LoRA的计算成本。

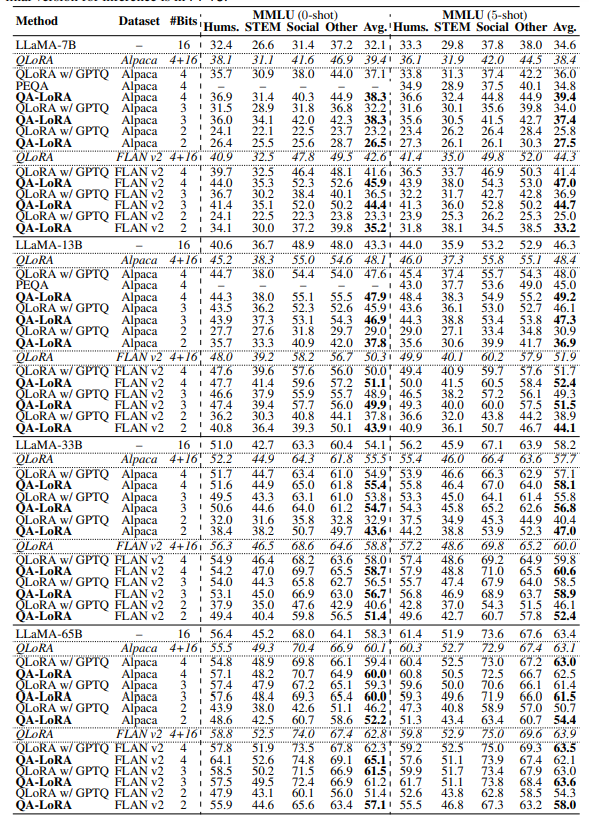
实验中将QA-LoRA应用于微调LLaMA模型,用于多模态语言理解。表格1总结了与不同模型大小、微调数据集和位宽相关的结果。除了基础的LLaMA模型外,研究还将QA-LoRA与最相关的研究QLoRA以及一个最近的不使用LoRA的量化方法PEQA进行了比较。报告中包含了原始的QLoRA(推理阶段涉及到FP16计算)和经过GPTQ之后的变体的结果。
QA-LoRA在0-shot和5-shot准确度方面一贯优于两个竞争对手(带GPTQ的QLoRA和PEQA)。当模型大小较小(例如,7B和13B)或位宽较小(例如,使用INT3或甚至INT2)时,这个优势更为显著,展示了QA-LoRA在需要计算效率的场景中是一个强大的解决方案。在某些情况下,QA-LoRA的INT4版本的表现甚至超过了原始版本的QLoRA,同时推理速度要快得多。
总结
这篇研究提出了一个叫做QA-LoRA的方法,目标是更加高效地在大型语言模型(LLMs)中实现低秩适应,同时引入低位量化。
简单来说,QA-LoRA的核心思想是进行分组操作,这既用于量化也用于低秩适应,找到一个平衡点,能够在这两者之间自由切换或调整。QA-LoRA不仅实施起来相对简单,还能广泛应用到各种基础模型和NLP中,而且无论是在微调阶段还是在推理阶段,它在计算上都展现出了高效性。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-10-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号