Spikformer脉冲神经网络学习


碎碎念
这篇文章鸽的比较久,也不是说懒(其实就是懒),主要是这两天实在太忙了(试图找借口),比如实习,每天都在办公室坐着(坐着摸鱼),老师也会不断地布置新任务以小组方式实现(其实根本没啥任务),而这个脉冲神经网络是我们六月底进行的研究,在研究的过程中感觉比较有意思(又能水一篇了)。所以还是决定将其分享到这里,可能稍微有些地方有问题(菜就多练),欢迎大家指正!
注意:本篇文章可能稍微有些枯燥乏味,因为是以实验报告的内容,可能没有一些华丽的辞藻,更多是关于相关领域的一些术词,可能仅供专业人士研究。
背景
在当前的深度学习领域,脉冲神经网络(Spiking Neural Networks, SNNs)和Transformer架构的融合正成为一种新的研究趋势。这些模型在各种任务中显示出显著的性能提升。本文的研究对象Spikformer即是一种结合了SNNs和Transformer架构的混合模型,旨在利用两者的优势来实现更高效的计算和更优异的性能
脉冲神经网络
脉冲神经网络(SNNs)是模仿生物神经系统的一类神经网络,与传统的人工神经网络(ANNs)不同,SNNs通过离散的脉冲信号进行信息传递。每个神经元在接收到其他神经元的脉冲信号时,积累电压,一旦电压达到一定阈值,神经元就会发出一个脉冲信号。这种基于事件驱动的计算方式,使得SNNs在理论上能够实现更高效的计算和更低的能耗。
SNNs的主要优点在于其生物启发的计算方式,这使得它们在处理稀疏和非结构化数据时具有独特的优势。然而,SNNs也面临着一些挑战,如训练的复杂性和硬件实现的难度。近年来,随着脉冲神经网络训练算法的发展,如脉冲时间依赖可塑性(STDP)和基于梯度的优化方法,使得SNNs在实际应用中变得更加可行。
Transformer模型
Transformer 是一种基于自注意力机制的模型,最早应用于自然语言处理任务,如机器翻译。其核心是自注意力机制(Self-Attention),能够有效捕捉输入序列中各元素之间的依赖关系。近年来,Transformer 在计算机视觉任务中也取得了显著成果,如图像分类、目标检测和语义分割等。自注意力机制通过计算查询(Query)、键(Key)和值(Value)之间的点积来加权特征,从而捕捉全局依赖关系。
尽管 Transformer 在视觉任务中的表现优异,但其计算复杂度较高,尤其是在处理大规模图像时。这促使研究者们探索改进自注意力机制的方法,例如使用卷积层进行特征提取、简化自注意力计算等。
Spikformer
脉冲神经网络(SNNs)是第三代神经网络,与传统的人工神经网络(ANNs)相比,SNNs 模仿生物神经元的活动方式,通过脉冲序列来传递信息。SNNs 中的神经元会在接收到足够的电信号后发出脉冲(spike),这种方式不仅生物学上更具可解释性,而且在硬件实现上能显著降低能量消耗。SNNs 的低功耗和事件驱动特性使其在需要高能效的应用场景中表现出色,如嵌入式系统和物联网设备。
SNNs 的研究主要集中在两个方面:一种是将传统的 ANN 转换为 SNN(ANN-to-SNN conversion),另一种是直接训练 SNN(direct training)。转换方法通过替换 ANN 中的激活函数为脉冲神经元实现高效的性能移植,但需要较多的时间步长来逼近 ANN 的输出,从而导致较高的延迟。而直接训练方法通过时间步长展开 SNN 并采用反向传播算法训练模型,尽管在事件触发机制上存在非连续性,但可以通过替代梯度法进行训练。
本文中的Spikformer 是将 SNN 与 Transformer 结合的一种新型架构,旨在结合两者的优势,既保留 SNN 的低功耗特性,又利用 Transformer 的全局特征捕捉能力。Spikformer 引入了脉冲自注意力机制(Spiking Self Attention, SSA),其创新点在于:
- 脉冲自注意力机制(SSA):传统的自注意力机制需要进行浮点数运算并通过 softmax 函数归一化权重,而 SSA 使用脉冲形式的查询、键和值(仅包含 0 和 1),避免了乘法运算,使得计算更加高效,能耗更低。
- 无 softmax 的脉冲自注意力:由于脉冲形式的查询和键计算出的注意力图天然非负,因此不需要 softmax 进行归一化,从而减少了计算开销。
- 架构设计:Spikformer 的设计考虑了 SNN 的计算特性,利用逻辑与操作和加法进行注意力计算,进一步降低了计算复杂度和能耗。
原理
脉冲神经网络
脉冲神经网络(Spiking Neural Networks, SNNs)的核心原理在于模拟生物神经元通过电脉冲进行信息传递的过程。在生物神经系统中,神经元通过膜电位的变化来响应外界刺激,当膜电位达到一定阈值时,神经元会发放一个动作电位,即脉冲,随后膜电位迅速复位。SNN正是基于这一机制进行建模的。
在SNN中,一个基本的神经元模型是Leaky Integrate-and-Fire(LIF)模型。该模型描述了神经元膜电位随时间的变化情况,其动态可以用以下微分方程表示:
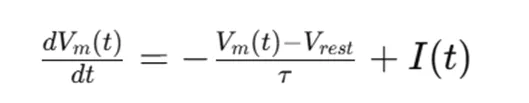
微分方程
其中:
- Vm(t)代表神经元在时间t的膜电位
- Vrest是静息膜电位
- t是膜时间常数
- I(t) 是输入电流
当膜电位Vm(t) 达到一个预设的发放阈值Vthresh时,神经元发放一个脉冲,并将膜电位重置到一个较低的值,如静息膜电位。
LIF模型中的“leak”效应模拟了膜电位自然衰减的过程,即使没有新的输入,膜电位也会逐渐向静息状态衰减。这种leak效应是必要的,因为它防止了膜电位的无限积累。
在SNN中,突触的权重更新通常遵循Spike-Time-Dependent Plasticity(STDP)规则。STDP是一种基于脉冲时间差异的突触可塑性机制,其基本思想是:如果前突触神经元的脉冲紧接着后突触神经元的脉冲之后到达,那么突触权重会增强(Long-Term Potentiation, LTP);反之,如果后突触神经元的脉冲先于前突触神经元的脉冲到达,突触权重会减弱(Long-Term Depression, LTD)。这种权重更新机制可以用以下公式描述:
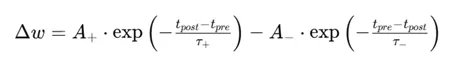
权重更新机制
其中:
- A+和A-是LTP和LTD的强度参数
- tpre和tpost分别是突触前和突触后脉冲的时间
- t+和t-是LTP和LTD的时间窗口参数
STDP规则的实现通常依赖于突触后神经元脉冲发放时的短期变化,这可以通过引入两个状态变量来实现,分别对应突触前和突触后的活动痕迹。当突触前或突触后神经元发放脉冲时,相应的痕迹变量会更新,从而影响突触权重的调整。
SNN的另一个关键特性是其对时间的编码能力。神经元发放脉冲的时间点和频率都可以携带信息。这种时间编码机制使得SNN能够处理时序数据,并且在某些任务中展现出比传统人工神经网络(ANN)更优越的性能。
- 时间编码通过脉冲发放的时间间隔来表示信号的强度。例如,较短的时间间隔表示较高的信号强度。
- 频率编码通过脉冲发放的频率来表示信号的强度。例如,较高的脉冲频率表示较高的信号强度。
- 相位编码通过脉冲相对于某一参考时间点的相位来表示信号的强度。相位编码在处理周期性信号时特别有效。
脉冲神经网络的结构可以是前馈网络、反馈网络或递归网络。不同的结构适用于不同的任务,前馈网络是最简单的网络结构,信息从输入层传递到输出层,中间可以有多个隐藏层。每一层的神经元只接收前一层的脉冲输入,递归网络包含环路,神经元不仅可以接收来自前一层的输入,还可以接收来自本层或前几层的反馈输入。递归网络适用于处理时间序列数据,因为它们能够保留之前的状态信息,混合网络结合了前馈和递归网络的特点,能够同时处理静态和动态数据。它们通常在生物神经网络的建模中使用。
与传统的人工神经网络相比,脉冲神经网络具有更高的能量效率和生物合理性。SNNs 通过脉冲的离散发放和事件驱动的计算方式,显著减少了计算和存储的开销。这使得 SNNs 特别适用于低功耗设备和实时应用,SNNs 的事件驱动计算方式意味着只有在脉冲发放时才进行计算,避免了大量的无效计算。每个脉冲的发放都是一个事件,触发相关神经元的状态更新,由于 SNNs 只在脉冲事件发生时进行计算,这种计算方式极大地降低了功耗。生物神经元也是通过类似的方式实现高效的能量利用,从而支持复杂的认知功能。
注意力机制&Transformer
Transformer架构中的注意力机制是其核心组件之一,对其性能和能力的提升至关重要。Transformer模型主要由编码器和解码器组成,而注意力机制在这两个模块中都扮演了关键角色。
在Transformer中,自注意力机制(Self-Attention)是用于捕捉序列中元素之间关系的主要方法。与传统的序列处理模型不同,自注意力机制能够并行处理整个输入序列,并且可以灵活地建模长距离依赖关系。
计算过程:
- 给定输入序列X={x1,x2,x3,……},首先通过线性变换将每个输入xn映射到查询(Query)、键(Key)和值(Value)向量:
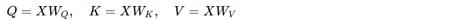
- 计算注意力得分:接下来,计算查询向量和键向量的点积,得到注意力得分矩阵E,E=QK^T,这种点积操作可以高效地计算序列中每个元素对其他所有元素的相关性。
- 归一化得分:为了使得得分更具可比性,通常使用softmax函数将其归一化,得到注意力权重矩阵A,这一步确保了每个查询向量的注意力权重之和为1。
- 最后,将注意力权重矩阵A应用于值向量V,得到输出表示,从而捕捉到序列中元素之间的全局依赖关系。
Transformer中的自注意力机制进一步扩展为多头注意力机制(Multi-Head Attention)。多头注意力机制的基本思想是使用多个独立的注意力头,每个头在不同的子空间中学习序列元素之间的关系。
- 对于每个输入序列,通过不同的线性变换得到h组查询、键和值向量:
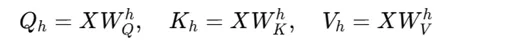
- 独立计算注意力:每个注意力头独立计算自注意力,得到一组输出:
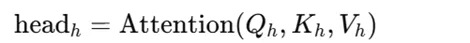
- 连接和线性变换:将所有注意力头的输出连接起来,形成一个新的表示,随后通过线性变换得到最终输出:
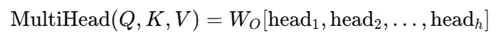
其中,W0是用于整合不同头输出的权重矩阵。
在编码器中,自注意力机制用于每一层的输入表示,捕捉输入序列内部的依赖关系。编码器中的每一层包括两个子层:多头自注意力机制和前馈神经网络(Feed-Forward Neural Network)。
多头自注意力子层:通过多个注意力头,并行处理输入序列的每个元素,捕捉到序列中不同位置的关系。
前馈神经网络子层:对注意力机制的输出进行进一步的非线性变换,以增加模型的表达能力。
每个子层之后都加了残差连接(Residual Connection)和层归一化(Layer Normalization),确保了梯度的稳定传递,并加速了训练收敛。
解码器中除了自注意力机制外,还引入了编码器-解码器注意力机制(Encoder-Decoder Attention),以便在生成每个输出时参考编码器的表示。
自注意力子层:与编码器类似,用于捕捉解码器内部生成序列的依赖关系。
编码器-解码器注意力子层:将解码器的查询向量与编码器的键和值向量进行注意力计算,结合编码器的全局信息生成当前输出。
Spikformer
Spikformer结合了脉冲神经网络(SNN)和Transformer架构,旨在利用两者的优势来提升处理复杂时序数据的能力。其整体架构由三个主要部分组成:脉冲补丁切割模块(SPS)、Spikformer编码器块和线性分类头。
首先,输入图像经过脉冲补丁切割模块(SPS)处理。该模块包括一个卷积层(Conv2D),用于提取输入图像的初始特征。然后,通过批归一化(Batch Normalization,BN)对特征进行归一化处理,批归一化在SNN中替代了常用的层归一化,因为层归一化不适用于SNN。接下来,最大池化(Max Pooling,MP)用于对特征进行下采样,最终生成脉冲特征。这一步的输出是一个脉冲序列,包含时序信息的脉冲特征。
进入Spikformer编码器块后,首先对脉冲序列进行脉冲位置嵌入(Spiking Position Embedding),以保留时序信息。嵌入后的脉冲序列被输入到脉冲自注意力机制(Spiking Self Attention,SSA)中。自注意力机制的核心是计算输入序列中各元素间的相关性,从而在全局范围内捕捉数据特征。SSA在Spikformer中专门为脉冲序列设计,包含线性变换层和批归一化层,通过矩阵点积(Matrix Dot-Product)计算序列间的相似度,并通过缩放(Scale)和软最大(Softmax)函数对相似度进行归一化。然后,将归一化后的相似度与输入序列相乘,生成新的脉冲序列表示。
脉冲自注意力机制的输出通过多层感知器(Multi-Layer Perceptron,MLP)进行进一步处理。MLP由多个线性层和激活函数组成,能够对数据进行非线性变换,从而增强模型的表达能力。在Spikformer中,MLP模块同样采用批归一化来稳定训练过程。最终,经过多个Spikformer编码器块堆叠,得到高维的脉冲序列表示。
在模型的最后阶段,经过编码器块处理后的脉冲序列被送入线性分类头。线性分类头将高维脉冲序列映射到分类标签空间,生成最终的分类结果。这一步的输出可以用于各种任务,如图像分类或时序数据分析。
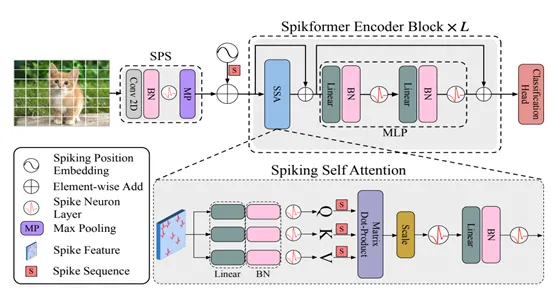
SkipFormer
在SNN的基本原理中,脉冲神经元的膜电位随时间变化的动态过程可以用Leaky Integrate-and-Fire(LIF)模型描述,其微分方程如下:
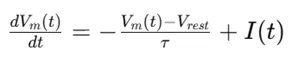
在Spikformer中,脉冲自注意力机制(SSA)是关键组件之一。自注意力机制通过以下步骤计算输入序列的注意力权重:
- 线性变换:将输入脉冲序列映射到查询(Query),键(Key)和值(Value)表示。
- 矩阵点积:计算查询和键之间的相似度,公式为:
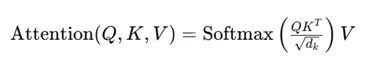
- 其中,Q是查询矩阵,K是键矩阵,V是值矩阵,dk是键的维度。通过矩阵点积计算得到的相似度矩阵经过缩放和软最大处理,生成归一化的注意力权重 加权求和:将归一化的注意力权重与值矩阵相乘,生成新的脉冲序列表示。
尝试实现
环境
- 硬件
本地训练(Baseline模型训练)
- CPU: 13th Gen Intel(R) Core(TM) i5-13490F
- GPU: NVIDIA GeForce RTX 4070 Ti SUPER
阿里云(Spikformer与SDTv2训练)
- CPU: Intel(R) Xeon(R) Platinum 8168 Processor
- GPU: NVIDIA A10
AutoDL(Spikformer与SDTv2训练)
- CPU: Intel(R) Xeon(R) Platinum 8352V
- GPU: 2 * NVIDIA GeForce RTX 4090
- 软件
高性能并行计算平台: NVIDIA CUDA
- CUDA提供了对NVIDIA GPU的直接访问,允许我们利用GPU的并行计算能力来加速深度学习模型的训练过程。
机器学习框架: PyTorch
- PyTorch是一个开源的深度学习框架,提供了灵活且高效的张量计算和动态计算图支持,方便我们构建和训练复杂的深度学习模型。
图片分类框架(Baseline模型选用): mmpretrain
- mmpretrain是一个专注于图像分类任务的框架,提供了许多预训练模型和训练工具,使得Baseline模型的训练更加高效和便捷。
数据集
CIFAR-10数据集
CIFAR-10数据集是一个常用于图像分类任务的标准数据集。它由60,000张32×32的RGB彩色图片组成,这些图片分属于10个不同的类别。每个类别包含6,000张图片,类别包括飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。数据集进一步划分为训练集和测试集:
- 训练集:50,000张图片,每个类别5,000张
- 测试集:10,000张图片,每个类别1,000张
CIFAR-10数据集因其规模适中和分类任务的多样性,成为评估图像分类算法性能的一个重要基准。
ILSVRC2012 (ImageNet)数据集
ILSVRC2012数据集,通常称为ImageNet数据集,是一个大规模的图像数据集,用于图像分类和物体检测任务。该数据集包含超过1,300,000张RGB彩色图片,分为1,000个类别。每个类别包含约1,300张图片。数据集同样分为训练集和测试集:
- 训练集:1,300,000张图片,每个类别约1,300张
- 测试集:50,000张图片,每个类别50张
Baseline训练
在正式复现论文代码前,我们实现了基于残差模型的Baseline模型作为基准参考。该基准模型的详细配置和训练策略如下:
在模型选型方面,我们选择了ResNet-101作为主干网络。ResNet-101是一种深度残差网络,通过引入残差连接,有效缓解了深层网络中的梯度消失问题,从而使得网络能够在更深的层次上进行训练和优化。在分类颈部分,我们采用了GlobalAveragePooling层。GlobalAveragePooling层将每个通道的特征图的平均值作为输出,从而减少参数数量,降低过拟合的风险,并提高模型的泛化能力。分类头方面,我们使用了LinearClsHead。LinearClsHead是一个简单的全连接层,用于将全局平均池化后的特征映射到最终的类别预测上。
为了扩增数据量,提高模型的泛化能力,我们在训练过程中采用了多种数据增强技术。首先,我们使用了RandomResizedCrop,该技术通过随机裁剪并调整图片大小,有助于模型学习不同的尺度和视角的特征。其次,我们引入了RandomFlip,通过随机水平翻转图片,增加训练数据的多样性。此外,ColorJitter技术用于随机改变图片的亮度、对比度、饱和度和色调,使得模型对颜色变化更加鲁棒。为了进一步增加训练数据的多样性,我们使用了Mixup技术,通过将两张图片及其标签按一定比例混合,提供了一种正则化效果。最后,我们还采用了CutMix技术,将一张图片的部分区域替换为另一张图片的相应区域,从而进一步增加训练数据的多样性和模型的鲁棒性。
在优化器和学习率策略方面,我们选择了Adam优化器。Adam优化器结合了动量和自适应学习率的方法,能够更快地收敛并且对学习率的选择不那么敏感。初始学习率设为0.001。在学习率策略上,我们使用了MultiStepLR。在训练的过程中,学习率在特定的训练轮数后进行衰减。具体地,学习率在第30、60、90轮时降低10倍,这样的策略有助于模型在初期快速收敛,同时在后期进行微调以达到更好的性能。
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=101,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=100,
in_channels=2048,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
),
train_cfg=dict(augments=[
dict(type='Mixup', alpha=0.8),
dict(type='CutMix', alpha=1.0),
])
)Spikformer模型复现
在复现论文提供的Spikformer源代码时,我们选择了以下参数配置:
首先,输入图片的尺寸设定为224像素乘以224像素。这一尺寸与许多图像分类任务中的标准输入尺寸一致,有助于确保模型的通用性。Embedding尺寸被设定为512维,这意味着输入图片在经过初步处理后将被映射到一个512维的特征空间中。
在Spikformer的结构中,我们使用了SPS Patch尺寸为16像素乘以16像素。这意味着输入图片将被划分为若干个16x16的补丁,每个补丁将被单独处理。Spikformer的层数设定为8层,这为模型提供了足够的深度,以便能够捕捉到图像中的复杂特征。每一层中的注意力头数目为8个,这允许模型能够在多个子空间中并行地关注不同的特征,从而提升模型的表现能力。
MLP隐藏层的比例被设定为4倍,即2048维。这意味着在多层感知机(MLP)部分,隐藏层的维度是输入维度的四倍,这样的设计有助于增加模型的非线性表示能力,从而增强模型的分类性能。分类头部分,我们选择了一个线性分类头,用于将特征映射到最终的类别预测上。
在优化器的选择上,我们使用了AdamW优化器。AdamW是一种结合了Adam优化器和权重衰减技术的优化器,能够有效防止过拟合,并且在许多任务中表现优异。初始学习率设定为0.0005,训练的前20轮作为预热轮,学习率从0.000001逐渐增大到0.0005,之后使用余弦学习率调度进行调整。这样的学习率策略有助于模型在训练初期稳定收敛,并在后期通过逐渐减小学习率来达到更好的性能表现。
整个训练过程共进行了300轮。在数据增强技术方面,我们选用了与之前基准模型训练相同的技术,包括RandomResizedCrop、RandomFlip、ColorJitter、Mixup和CutMix等。这些数据增强技术能够有效扩充训练数据,提高模型的泛化能力。
通过上述参数配置和训练策略,我们成功复现了论文中的Spikformer模型,并通过详细的训练和评估过程,确保模型能够达到预期的性能表现。
@register_model
def spikformer(pretrained=False, **kwargs):
model = Spikformer(
img_size_h=224, img_size_w=224,
patch_size=16, embed_dims=512, num_heads=8, mlp_ratios=4,
in_channels=3, num_classes=100, qkv_bias=False,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=8, sr_ratios=1,
**kwargs
)
model.default_cfg = _cfg()
return modelSDTv2模型
运行SDTv2模型源代码时,我们选择了以下参数配置,以确保模型能够在不同的任务中表现出色:
首先,输入图片的尺寸设定为224像素乘以224像素。这一尺寸与许多标准图像分类任务的输入尺寸一致,确保模型能够处理常见的数据格式。在Embedding尺寸方面,SDTv2模型采用了多种不同的维度:128维、256维、512维和640维。不同的Embedding尺寸允许模型在不同的层次上捕捉到图像的多尺度特征,从而提高模型的整体表现。
与Spikformer类似,SPS Patch的尺寸设定为16像素乘以16像素。这意味着输入图片将被分割成若干个16x16的补丁,每个补丁将被单独处理,以提取局部特征。SDTv2模型的深度为8层,每层包含8个注意力头。这些注意力头允许模型在多个子空间中并行地关注不同的特征,从而提高模型的特征表示能力。
MLP隐藏层的比例设定为4倍,这意味着在多层感知机(MLP)部分,隐藏层的维度是输入维度的四倍。这种设计有助于增强模型的非线性表示能力,从而提高模型的分类性能。分类头部分,我们同样选择了一个线性分类头,用于将特征映射到最终的类别预测上。
在优化器的选择上,我们使用了AdamW优化器。AdamW结合了Adam优化器和权重衰减技术,能够有效防止过拟合,并在许多任务中表现优异。初始学习率设定为0.0005,前20轮作为预热轮,学习率从0.000001逐渐增大到0.0005,之后使用余弦学习率调度进行调整。这种学习率策略有助于模型在训练初期稳定收敛,并在后期通过逐渐减小学习率来达到更好的性能表现。
整个训练过程共进行了200轮。数据增强技术方面,我们选用了与之前基准模型训练相同的技术,包括RandomResizedCrop、RandomFlip、ColorJitter、Mixup和CutMix等。这些数据增强技术能够有效扩充训练数据,提高模型的泛化能力。
CUDA_VISIBLE_DEVICES=0,1 torchrun --standalone --nproc_per_node=2 \
main_finetune.py \
--batch_size 64 \
--blr 6e-4 \
--warmup_epochs 10 \
--epochs 200 \
--model metaspikformer_8_512 \
--data_path /root/autodl-tmp/ ILSVRC2012 \
--output_dir outputs/55M \
--log_dir outputs/55M \
--model_mode ms \
--dist_eval结果展示
评估结果
模型 | 数据集 | Top-1 (%) | Top-5 (%) | 轮数 (epoch) |
|---|---|---|---|---|
ResNet-101 | CIFAR-10 | 80.99 | / | 100 |
Spikformer | CIFAR-10 | 94.82 | 99.62 | 300 |
ResNet-101 | ImageNet-100 | 72.90 | 91.29 | 200 |
ResNet-101(aug) | ImageNet-100 | 78.26 | 92.70 | 200 |
Spikformer | ImageNet-100 | 82.80 | 96.26 | 200 |
SDTv2 | ImageNet-100 | 84.46 | 95.82 | 200 |
结果分析
在CIFAR-10数据集上,我们比较了ResNet-101和Spikformer的表现。ResNet-101在没有数据增强的情况下,经过100轮训练,达到了80.99%的Top-1准确率。而Spikformer在经过300轮训练后,取得了显著提升,达到了94.82%的Top-1准确率和99.62%的Top-5准确率。这个结果表明Spikformer在处理小规模图像数据集时,表现出色,显著优于传统的卷积神经网络ResNet-101。
在ImageNet-100数据集上,我们对比了ResNet-101、ResNet-101(使用数据增强技术)和两种新的架构模型Spikformer和SDTv2。结果显示,标准的ResNet-101在没有数据增强的情况下,经过200轮训练,达到了72.90%的Top-1准确率和91.29%的Top-5准确率。加入数据增强技术后,ResNet-101的表现有所提升,达到了78.26%的Top-1准确率和92.70%的Top-5准确率。
Spikformer在ImageNet-100数据集上的表现比ResNet-101更为优越。经过200轮训练,Spikformer达到了82.80%的Top-1准确率和96.26%的Top-5准确率。相比于使用数据增强的ResNet-101,Spikformer在Top-1和Top-5准确率上分别提升了4.54%和3.56%。
SDTv2则表现得更加出色。在相同的训练条件下,SDTv2在ImageNet-100数据集上达到了84.46%的Top-1准确率和95.82%的Top-5准确率。这一结果表明,SDTv2在处理大规模图像数据集时,能够提供更高的分类准确率,超过了Spikformer和ResNet-101。
我们的实验结果表明,Spikformer和SDTv2在处理图像分类任务时,表现优于传统的卷积神经网络ResNet-101。特别是在使用数据增强技术和优化训练策略后,Spikformer和SDTv2展示了更强的特征提取和分类能力。Spikformer在小规模数据集CIFAR-10上的出色表现,以及SDTv2在大规模数据集ImageNet-100上的优越性能,证明了它们在不同场景下的广泛适用性。未来,我们可以进一步优化这些模型,探索它们在更多任务和数据集上的潜力。
总结
在本项目中,我们着重研究并复现了Spikformer模型,通过与传统的卷积神经网络ResNet-101以及另一种新型架构SDTv2进行对比实验,验证了Spikformer在图像分类任务中的性能优势。我们选用了CIFAR-10和ImageNet-100两个数据集,采用不同的训练策略和优化方法,全面评估了各个模型的表现。
在CIFAR-10数据集上,Spikformer显著超过了传统的ResNet-101模型。经过300轮训练,Spikformer达到了94.82%的Top-1准确率和99.62%的Top-5准确率,远高于ResNet-101的80.99%(Top-1准确率)。这表明Spikformer在处理小规模图像数据时,具有更强的特征提取和分类能力。同时,这一结果展示了Spikformer在小规模数据集上的卓越表现。
在ImageNet-100数据集上,我们发现数据增强技术对ResNet-101的性能有显著提升。在没有数据增强的情况下,ResNet-101的Top-1和Top-5准确率分别为72.90%和91.29%;而使用数据增强后,准确率提升至78.26%(Top-1)和92.70%(Top-5)。这说明数据增强技术能够有效提高模型的泛化能力。然而,即使在使用数据增强的情况下,ResNet-101的表现依然不及Spikformer。
在ImageNet-100数据集上,Spikformer同样展示了优越的性能。经过200轮训练,Spikformer的Top-1准确率为82.80%,Top-5准确率为96.26%。相较于使用数据增强的ResNet-101,Spikformer在Top-1和Top-5准确率上分别提升了4.54%和3.56%。这一结果表明,Spikformer在处理大规模数据时依旧具备强大的学习和分类能力。同时,SDTv2在相同数据集上的表现也十分出色,其Top-1准确率为84.46%,Top-5准确率为95.82%,略高于Spikformer,但差距不大。
通过这些实验,我们验证了Spikformer在图像分类任务中的优越性能,特别是在处理不同规模的数据集时,均展现出强大的特征提取和分类能力。与传统的卷积神经网络相比,Spikformer在多个方面均具有显著的优势。
参考文章
Spikformer: When Spiking Neural Network Meets Transformer
Spikformer V2: Join the High Accuracy Club on ImageNet with an SNN Ticket
ICLR 2023 Spikformer: When Spiking Neural Network Meets Transformer
developer.volcengine.com@架构师带你玩转AI
声明
- 以上内容仅供学术研究和学习交流使用,如有侵权,请联系我进行删除处理。
- 若有任何问题或需要进一步讨论,请随时联系我的邮箱:01@liushen.fun。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-07-06,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号