Bioinform|质子展开熊昭平/西安交通大学刘冰等:超越直接结构建模的蛋白质功能注释多模态模型FAPM

Bioinform|质子展开熊昭平/西安交通大学刘冰等:超越直接结构建模的蛋白质功能注释多模态模型FAPM

智药邦
发布于 2024-12-09 14:37:51
发布于 2024-12-09 14:37:51
蛋白质是使地球生命正常工作的分子机器,几乎我们身体做的所有事情都会用到蛋白质:它们消化食物、收缩肌肉、激发神经元、探测光线以及增强免疫反应等等。因此,理解蛋白质的作用,对于理解身体是如何工作的、当它们不工作时会发生什么、以及如何修复它们至关重要。虽然蛋白结构的预测已经达到了生物实验的精度,但是蛋白质功能的识别依然耗时又耗力,尤其是面对测序技术带来的海量天然蛋白序列,亟需高通量的功能预测模型。
临港实验室与临港实验室与中国科学院上海药物研究所、质子展开科技有限公司以及西安交通大学合作,共同提出了基于多模态模型的预测蛋白质功能新方法FAPM(Functional Annotation of Proteins using Multi-Modal models)。FAPM在理解蛋白质属性方面表现出色,优于仅仅基于蛋白质序列或结构的模型。不同于把结构和序列作为输入的传统多表征模型,该多模态模型融合了蛋白序列预训练模型和大语言模型,以此理解GO(Gene Ontology)标签中蕴含的语义信息,从而实现符合语义逻辑的功能预测,改进了传统多表征模型预测出现冲突功能标签的问题。此外,该模型可以结合额外的文本提示信息,如蛋白质的分类信息,来提高其预测性能和可解释性。这种新颖的方法为依赖多序列比对的蛋白质注释提供了一种有前途的替代方案。
相关研究成果已在Bioinformatics期刊上发表,题为“FAPM: Functional Annotation of Proteins using Multi-Modal Models Beyond Structural Modeling”。
同时,该方法开放了在线测试,地址为:
https://huggingface.co/spaces/wenkai/FAPM_demo

1 背景
准确标注蛋白质的属性,以描述其功能和催化活性等特征,是一项充满挑战的工作,尤其是对于那些缺乏同源蛋白和只有少数已知案例的“罕见标签”蛋白质。传统方法主要集中于分析蛋白质的序列或结构特征,却往往忽略了功能标签中蕴含的丰富语义信息。
为了解决这一难题,研究人员提出了FAPM模型(图1)。模型预测的GO(Gene Ontology)标签是一个拥有50 000多个类别的功能描述体系。它包含三个子体系:MFO(Molecular Functions Ontology)、BPO(Biological Processes Ontology)和CCO(Cellular Components Ontology)。FAPM采用了预训练的大型语言模型Mistral来解析GO(Gene Ontology)标签中蕴含的深层语义信息,并利用ESM2——由Facebook团队开发的蛋白序列预训练模型——来提取蛋白质序列的关键信息。通过运用多模态技术,FAPM将自然语言与蛋白质序列语言相结合,揭示序列与功能之间的潜在联系,实现对蛋白质功能的预测。研究结果表明,FAPM在解析蛋白质属性方面具有显著优势,在公共基准测试中展现了卓越的性能,超越了那些仅依赖于蛋白质序列或结构信息的模型。此外,研究者还利用了一批内部实验标注的噬菌体蛋白数据进行测试。尽管这些蛋白质的已知同源物较少,FAPM依然能够准确预测出它们的关键功能,显示出其在蛋白质功能预测领域的强大潜力。
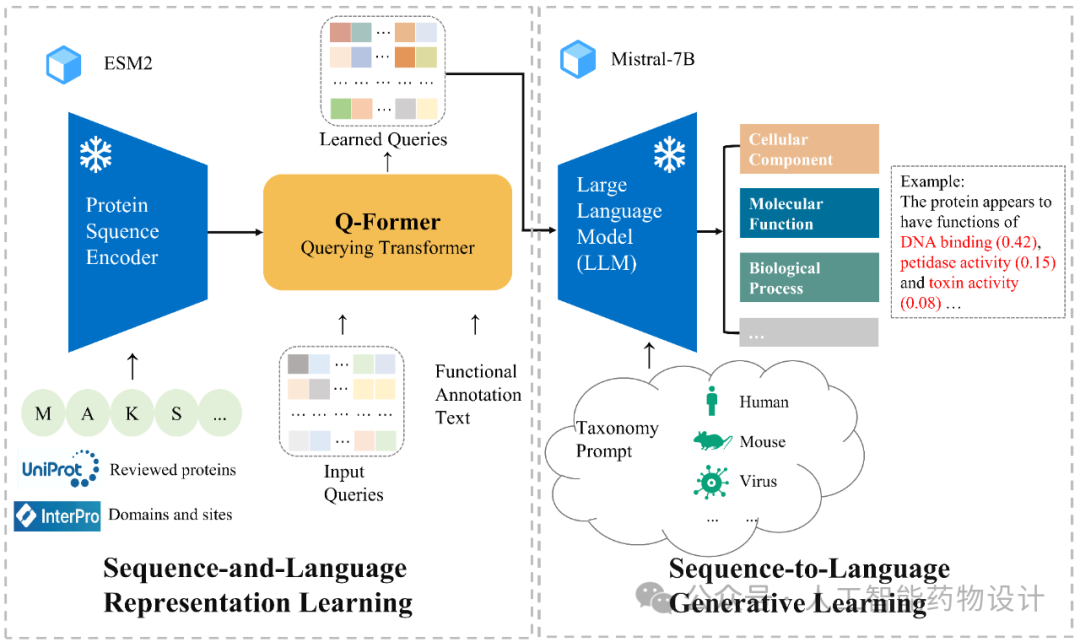
图1. FAPM的模型结构。左边为序列和语言表征学习阶段,FAPM使用ESM2对蛋白质序列进行编码,并使用Q-Former将其与功能文本(GO标签)对齐。右边为序列到语言的生成学习阶段,Mistral-7B语言模型处理前一阶段学习到的查询,并结合一些额外的提示信息,生成带有相关概率的GO标签预测。InterPRO数据库中的蛋白质功能域数据和UniProt数据库中的已验证蛋白质被用于训练模型。
2 结果与讨论
2.1 FAPM对比单模态大语言模型方法
鉴于FAPM框架集成了语言模型,一个自然而然的研究方向是将FAPM与那些直接利用语言模型进行功能预测的方法进行对比,从而评估其在蛋白质功能预测任务中的性能表现。研究人员利用Mol-Instructions定义的蛋白质指令数据集及其预定义的训练/测试分割,训练了一版专门用于对比的FAPM模型。图2(A)的雷达图展示了在功能分类、功能描述、催化活性以及功能域预测四项任务中,八种方法的Rouge-L指标,其中FAPM对应最外围的红线,次优方法Mol-Instructions对应中间的绿线。图2(B)中展示了一个具体的预测案例,可以看出,对“UMP-CMP激酶”的预测结果中,FAPM生成的内容错误更少,在功能描述上与真实结果能更好地对齐,并成功预测出Mol-Instructions未能识别的功能(“phosphorylation”和“nucleus”)。
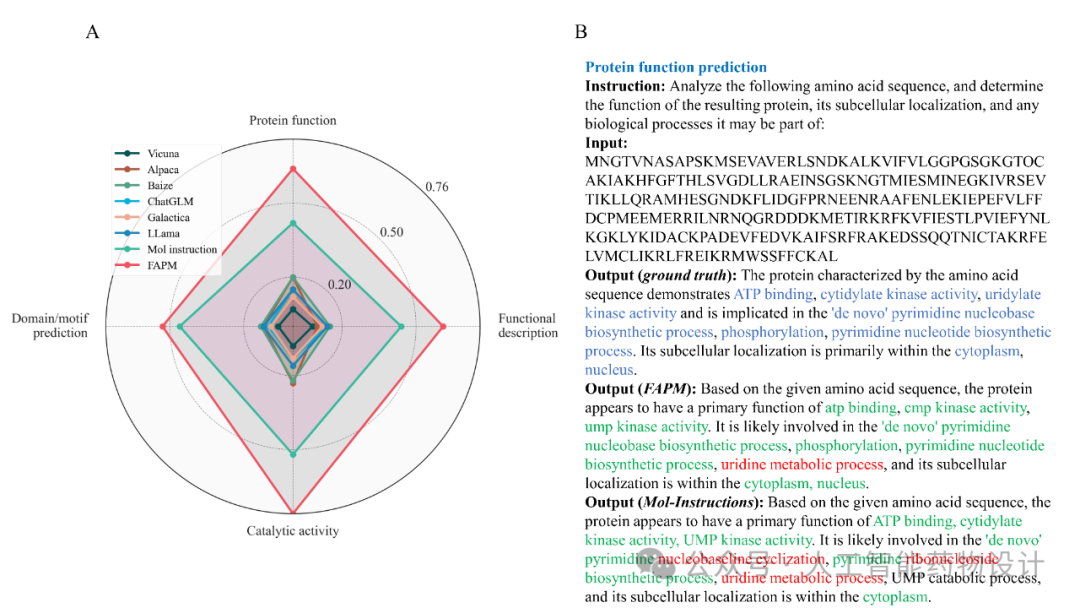
图2. FAPM与其它语言模型的比较。A. FAPM与其它语言类方法在四种任务上的Rouge-L指标对比。B. 与次优方法的对比案例。
2.2 在Swiss-Prot数据集上的预测效果分析
Swiss-Prot是专业的蛋白质序列数据库,由欧洲生物信息学研究所(EBI)维护,其中包含了蛋白质序列及其引用文献信息、分类学信息、注释等丰富信息,在蛋白质研究领域广受欢迎。这里,研究人员也将其作为训练和测试的主要数据集之一。
如图3所示,研究人员将FAPM与其他方法进行了比较,包括Naive、DeepGOCNN、DeepGraphGO、DeepGOZero和DeepGO-SE。图3(A)展示了六种方法在Swiss-Prot数据集测试集上的精确率-召回率曲线。值得注意的是,DeepGOCNN的性能并没有显著超越Naive方法,而其他深度学习方法则明显优于Naive方法。在这些方法中,FAPM的整体表现尤为突出。图3(B)展示了GO术语出现频率与模型预测性能之间的关系。研究人员统计了训练集中每个GO标签的出现次数,并将其分为五类:0-20, 20-50, 50-200, 200-1000,和1000+。然后计算每组中预测GO标签的平均F1分数,以比较四种模型的性能:DeepGraphGO、DeepGOZero、DeepGO-SE和FAPM。在预测高频GO术语(1000+)时,三种方法表现相似,FAPM略胜一筹。然而,对于出现次数少于1000的GO标签,FAPM表现出更显著的优势,特别是在BPO和CCO类别中,凸显了FAPM在预测稀有GO标签方面的强大能力。
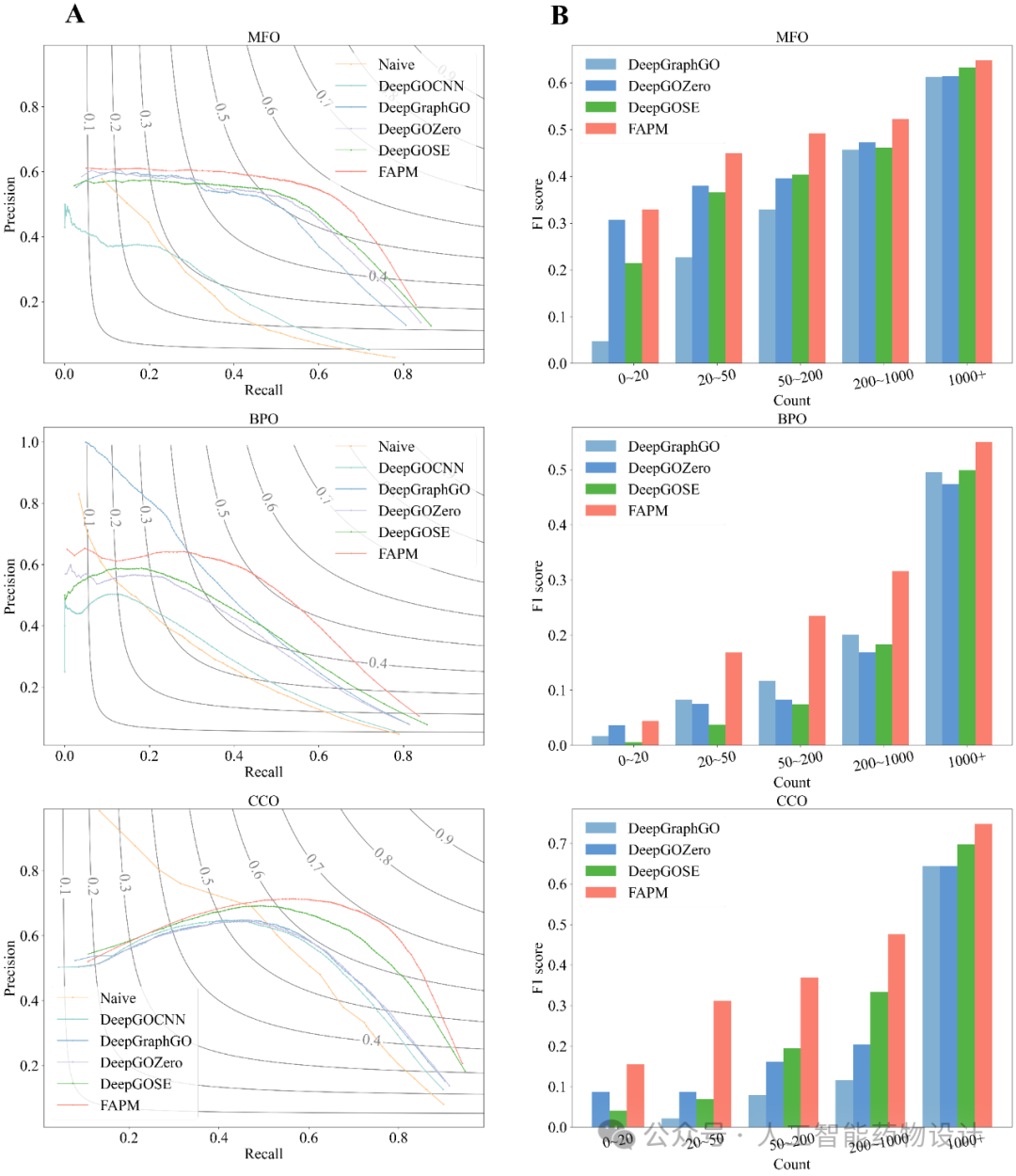
图3. 蛋白功能预测效果对比。A. 准确率-召回率曲线对比。B. 不同频率标签预测效果对比。
2.3 噬菌体蛋白质预测案例分析
预测缺乏同源物的蛋白质功能对于同源搜索和传统多表征模型是一项挑战。为了充分验证模型的潜力,研究人员选择了一些细菌和噬菌体蛋白质来实验验证预测结果。细菌是人类致病性疾病的主要原因,也是共生微生物。人类对细菌的理解仍需深入,比如大肠杆菌和枯草芽孢杆菌分别代表的革兰氏阴性和革兰氏阳性菌仍有超过一半的基因需要功能标注。噬菌体的数量估计为1031,超过了地球上所有其他生命的总和,庞大的人口和多样性使其基因产物成为未知功能蛋白质的最大储库,基于当前的实验技能不可能手动注释。研究人员选择了一系列细菌和噬菌体蛋白质,包括来自大肠杆菌、枯草芽孢杆菌、常见细菌的噬菌体以及稀有RNA噬菌体的蛋白质。在选择的29种蛋白质中(24种来自噬菌体,5种来自细菌),3种最近进行了功能分配,5种经过实验验证但未在蛋白数据库UniProt中描述。
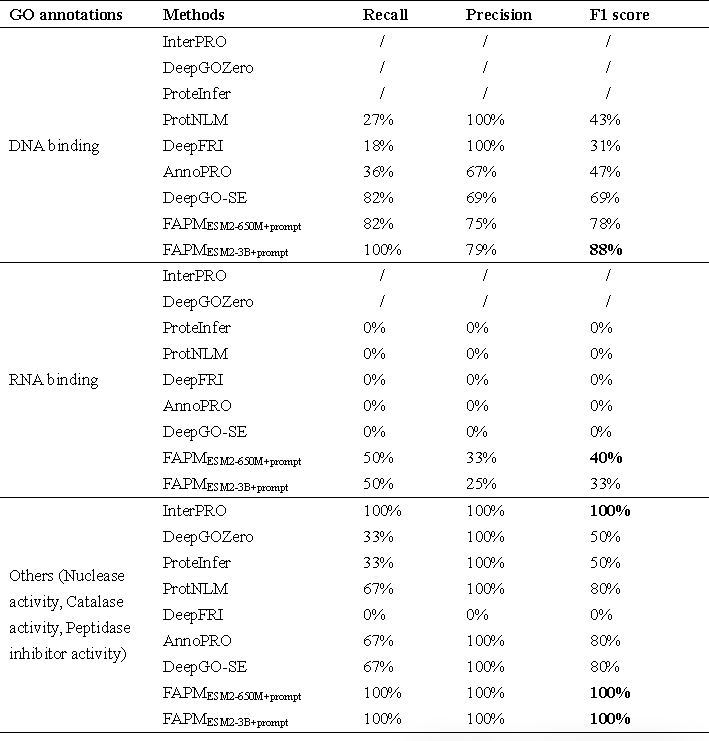
表1 展示了多种方法在这29中蛋白上的预测结果。在“DNA binding”等功能的预测中,FAPM均取得了不俗的表现,值得注意的是,FAPM是对比方法中唯一成功识别出“RNA binding”的方法。
表1. 预测噬菌体蛋白功能的召回率、精确率和F1分数
2.4 物种信息对模型影响的案例分析
研究人员观察到,引入物种提示信息能够提高预测的准确性,尤其是在BPO和CCO这两个类别中。一种可能的解释是,提示中的物种信息与特定的功能密切相关。这种猜测得到了图3中不同功能同源蛋白案例的支持。将分类信息(如“Homo”)作为提示添加到FAPM的语言端模型后,研究人员观察到模型生成能力发生了一些变化,成功避免了一些基本错误并提高了预测质量。图4展示了一对同源蛋白TRPV1_HUMAN和A0A452GR26_9SAUR,分别属于人类和野鸡。尽管这两个蛋白具有高度相似性,序列相似性为70.76%,结构RMSD值为1.593,然而,它们在作为辣椒素受体(TRPV1)的功能上存在关键差异。
TRPV1是一个受炎症因子调节的热激活阳离子通道,涉及急性和持续性疼痛,可以认为它控制了辣味的感知。通常来说,辣椒植物的种子主要由鸟类传播,这得益于鸟类中的TRPV1通道对辣椒素及相关化学物质无反应,换句话说,鸟类不怕辣。相反地,哺乳动物的TRPV1对其非常敏感,导致剧烈的辣味。在GO体系中,TRPV1的功能关联于“behavioral response to pain”(编号为GO:0048266),即对疼痛的反应。使用物种信息,FAPM正确地用GO:0048266注释了人类蛋白TRPV1_HUMAN,而没有为野鸡蛋白A0A452GR26_9SAUR注释该功能,这证明了鸟类和哺乳动物对辣味反应的差异。
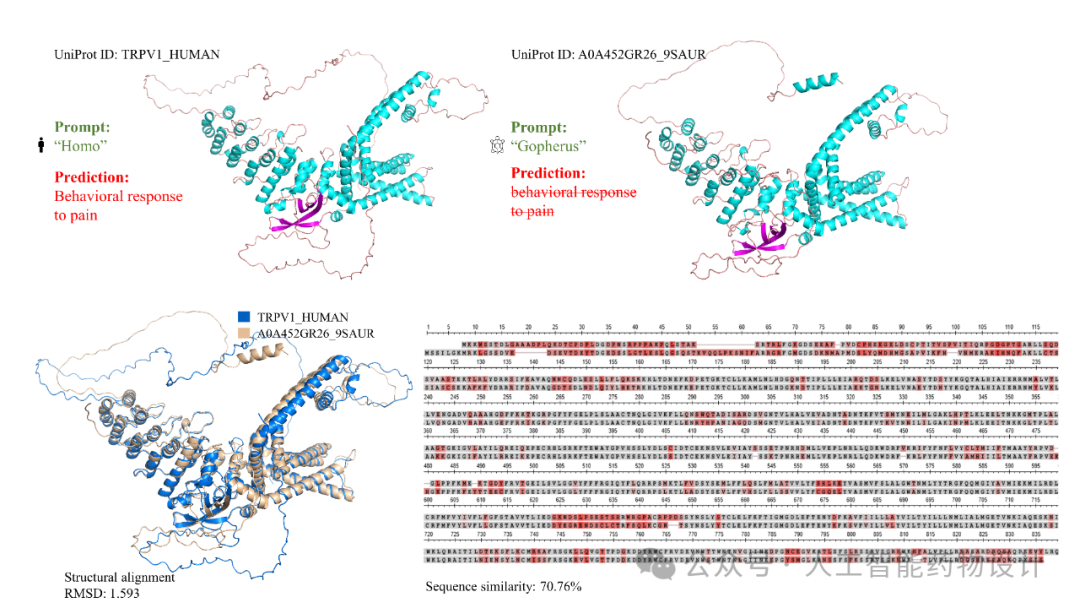
图4. 不同物种同源蛋白质的功能预测案例
2.5 多模态模型的可解释性分析
与预训练的蛋白质序列模型ESM2相比,FAPM在蛋白质特性表示方面表现更佳,因其对功能具有更好的区分性。图5展示了使用UMAP方法对Swiss-Prot测试集中具有特定功能的蛋白质进行的2D投影。该图分为三部分,图5(A)部分关注最常见的功能(移除具有多功能的蛋白质),而图5(B)和图5(C)分别展示了具有相似和对比功能的蛋白质。在所有三种情况下,ESM2的表示显示出较弱的聚类效应,而FAPM则产生了明显的聚类效应。更有趣的是,图5(A)右边部分显示了两个靠近的聚集簇,而图5(C)右边部分显示了两个相对分开的聚集簇,表明FAPM有效捕捉了蛋白质序列的功能关系,并用距离表达了功能之间的差异。总体而言,在功能方面,FAPM的蛋白表征优于ESM2,具备较强的解释性,侧面验证了该模型成功地融入了功能描述中的语义信息。
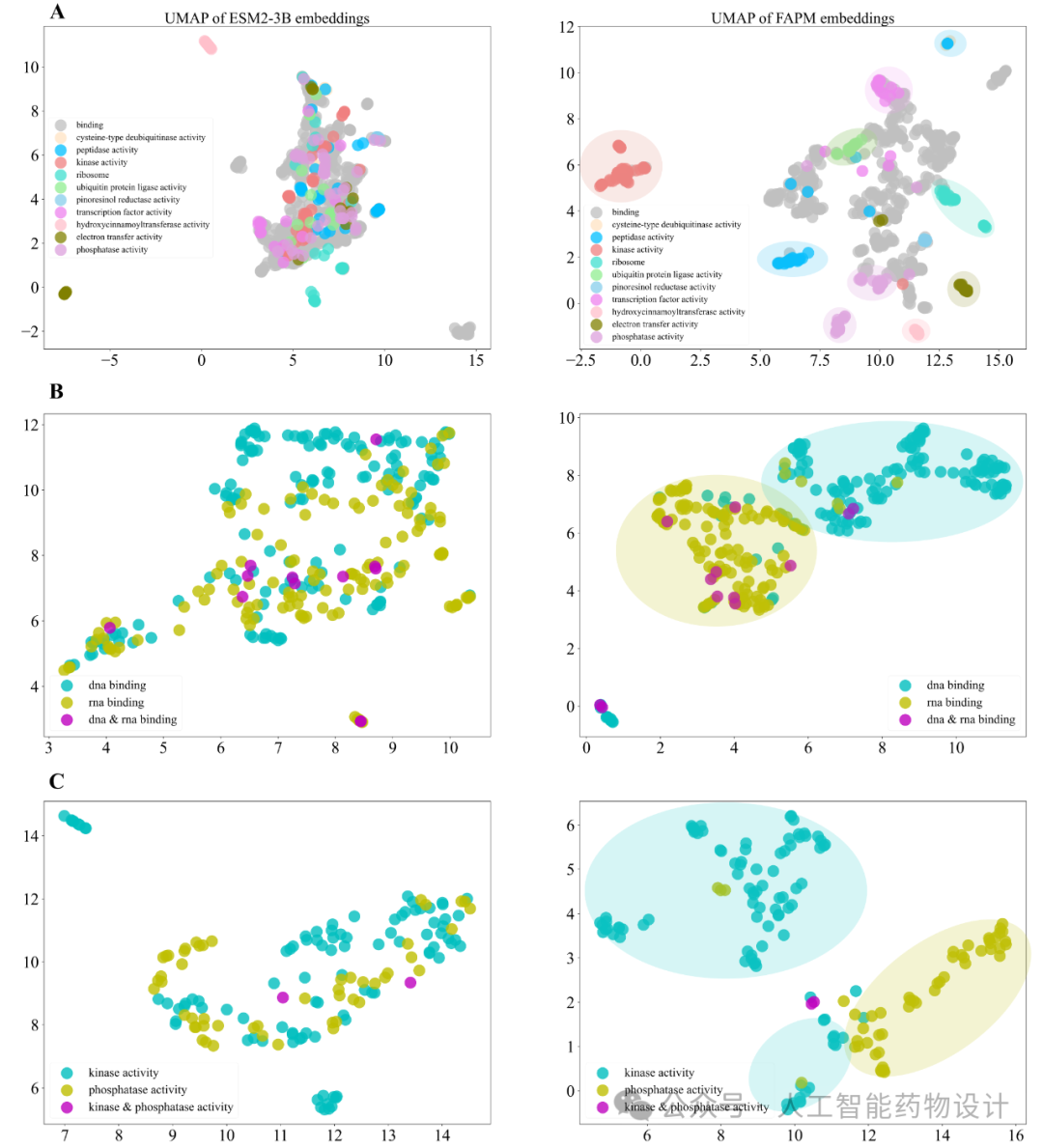
图5. ESM2与FAPM在特定GO功能上的蛋白质表征的差异。所有样本均来自Swiss-Prot数据集的测试集。A.具有十余中最常见功能中任意功能的的蛋白质的表征。B.具有DNA/RNA结合功能的蛋白质的表征。C.具有激酶/磷酸酶活性功能的蛋白质的表征。
3 结论
在该项研究中,作者提出了基于多模态学习的蛋白功能预测方法FAPM。FAPM仅需输入蛋白质序列,其语言模型的生成结果符合人类习惯,易于理解和解释。该方法使用了大量蛋白功能域数据和人工标注功能数据进行蛋白与自然语言大模型的对齐训练,相较于此前的单模态方法或多表征方法,展现出更优越的性能,尤其在对非同源蛋白质的预测准确性和泛化能力方面表现突出。研究还发现,将分类信息作为提示可以提升输出结果的可靠性。总的来说,FAPM为蛋白功能标注领域提供了一种新的思路和解决方案。
临港实验室研究助理项文凯、质子展开科技有限公司熊昭平博士和西安交通大学陈欢博士为本文的共同第一作者。临港实验室青年研究员史倩、质子展开科技有限公司熊昭平博士和西安交通大学刘冰教授为论文共同通讯作者。本研究得到了上海市启明星项目、国家自然科学基金、以及国家重点研发计划的资助。
参考资料
Wenkai Xiang, Zhaoping Xiong, Huan Chen, Jiacheng Xiong, Wei Zhang, Zunyun Fu, Mingyue Zheng, Bing Liu, Qian Shi, FAPM: Functional Annotation of Proteins using Multi-Modal Models Beyond Structural Modeling, Bioinformatics, 2024, btae680.
https://mp.weixin.qq.com/s/Q612iZSrqAlGABXkMSnCrA
--------- End ---------
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号