超越UNet:TP-UNet引入时间Prompt实现高级医学图像分割 !

超越UNet:TP-UNet引入时间Prompt实现高级医学图像分割 !

未来先知
发布于 2024-12-19 19:00:55
发布于 2024-12-19 19:00:55

医学图像分割技术的进步推动了深度学习技术的应用,尤其是基于UNet的方法,这些方法利用语义信息来提高分割的准确性。 然而,当前基于UNet的医学图像分割方法忽略了扫描图像中器官的顺序。此外,UNet的固有网络结构并没有直接提供集成时间信息的能力。 为了有效地集成时间信息,作者提出了TP-UNet,该方法利用时间 Prompt ,包括器官构建关系,来指导分割UNet模型。 具体而言,作者的框架具有基于无监督对比学习的自注意力机制和语义对齐,以有效地结合时间 Prompt 和图像特征。 在两个医学图像分割数据集上的广泛评估表明,TP-UNet的性能达到了最先进水平。作者的实现将在 Acceptance 后开源。
I Introduction
医学图像分割在现代医学领域占有重要地位,在疾病诊断、手术计划和治疗监测等方面发挥基础作用 [1]。该任务的主要目标是准确地分离和 Token 医学图像中呈现的特定结构或组织,以便医疗专业行人能够进行细致分析并实现精确诊断。值得注意的是,随着深度学习技术的进步,一些基于UNet及其变体的网络已经展示了通过提取医学图像中的语义信息来实现令人称赞的分割准确性 [2]。
尽管已经报道了令人鼓舞的结果,但现有的基于UNet的算法在扫描医学图像时缺乏对时间信息的考虑[3]。为了更好地理解时间信息,作者在图1中进行了可视化。将时间信息(表示一系列医学图像的序列)纳入其中,有可能提高医学分割的准确性。例如,在一个患者的一系列N切片(表示为Ni^th/N)中,特别地,某些器官(如胃、大肠和小肠)在给定的时间区间(Ni^th/N,Ni^th/N)内表现出特定的时间模式,通常遵循正态分布。具体来说,它们的正常分布可以分别表示为Nstomach(μstomach, σstomach),Nlarge(μlarge, σlarge)和Nsmall(μsmall, σsmall)。在成像模式如MRI或CT扫描中,成像过程通常从上到下进行,胃主要出现在早期的至中期的时段,而小肠在中期时段更为常见,大肠主要出现在后期时段。因此,作者有μstomach≤μsmall≤μlarge。因此,在特定的时间间隔内,早期阶段应优先考虑胃分割,而后期阶段应专注于大肠分割,以提高医学分割模型的性能。尽管时间信息在提高分割准确性方面具有明显的重要性,但其在当前研究中的考虑往往被忽视。
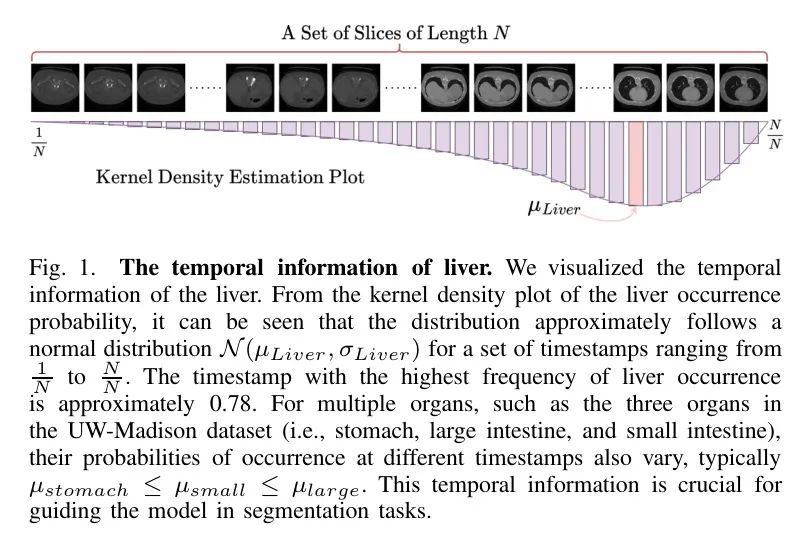
为了利用医学影像中固有的时间信息,作者提出了一种名为TP-UNet的框架,该框架利用时间 Prompt 来指导UNet模型的学习过程。时间 Prompt 提供文本信号,用于引导分割模型从医学影像中学习语义和顺序信息。这些文本信号首先通过一个经过良好训练的编码器进行高维嵌入,然后与图像编码器的特征图进行交互。由于文本和图像的编码过程不同,仅使用图像嵌入和文本嵌入之间的线性映射进行交互可能导致次优的融合结果,甚至降低模型性能[4]。为了解决这个问题,作者在文本和图像模态之间的交互之前进行语义对齐操作,利用无监督对比学习来缩小文本表示和图像表示之间的语义差距。最后,在进行模态融合时,作者采用交叉注意力机制来聚合上述更新的文本表示和图像表示。这个过程产生了一个统一的表示,作为UNet模型解码器的输入。
作者的主要贡献可以总结如下:
- 作者提出TP-UNet,这是一个简单而有效的医学图像分割框架,该框架可以通过文本 Prompt 引导分割模型在医学图像中学习时间信息。
- 作者提出了一种两阶段的语义对齐和模态融合过程,以缩小时间 Prompt 和图像特征之间的语义差距,并有效地将它们聚集到一个统一表示中。
- 作者在两个医学图像分割数据集上进行了广泛实验,包括LITS 2017数据集和UW-Madison数据集。实验结果表明,作者的方法实现了最先进的性能(SOTA)。
II Related Work
Prompt Learning
Prompt 学习是自然语言处理(NLP)领域的一个重要研究方向。它专注于设计有效的 Prompt 或问题,引导模型为特定任务生成准确、相关的输出。通过针对任务定制 Prompt , Prompt 学习有助于模型专注于关键信息,减少搜索空间,从而提高模型性能。这种技术已在各种NLP任务中取得成功,包括文本分类、命名实体识别和机器翻译。
最近,这种方法已应用于医学图像分割,旨在通过文本 Prompt 提高模型的分割能力。例如,贾磊等基于需要分割的器官名称构建 Prompt [5]。另一方面,吴俊杰等基于器官的文本描述,包括其功能、形状和外观构建 Prompt ,实现了分割性能的显著改善 [6]。然而,这两种方法都没有利用医学图像的时空信息。在本研究中,作者设计了基于医学图像时空信息的 Prompt ,旨在利用时空信息引导分割模型以获得更好的性能。
Multimodal Contrastive Learning
多模态对比学习是多模态学习领域的一种强大技术,它考虑了多种模态如文本、图像和音频等。该方法的目标是通过最大化同一类别样本之间的相似度,最小化不同类别样本之间的相似度,来学习有意义的表示。在多模态学习的背景下,这涉及将不同模态的表示映射到共享的嵌入空间,以捕捉它们之间的关系和交互。多模态对比学习利用多个模态的互补信息,增强模型对整体数据的理解和表示学习能力。
这种方法已在医学领域得到广泛应用。张裕豪等人提出了ConVIRT [7],它使用双向对比目标函数最大化真实匹配和随机图像文本对之间的一致性,实现无监督训练。该方法利用跨域配对文本数据,无需额外专家输入。在图像分类任务中,ConVIRT实现了高数据效率,仅用10%的 Token 训练数据即可达到与使用ImageNet初始化的模型相当或更好的性能。
黄世成等人提出了GLoRIA [8]框架,通过使用全局和局部对比损失函数最大化医学图像与文本之间的相关性,从而在下游任务中提高性能。
总之,多模态对比学习可以提高数据效率,在不同的模态之间对语义信息进行对齐,并提高下游任务的表现。本文中使用的对比学习解决了不同模态之间的相似性问题,从而在下游医学图像分割任务中实现更好的泛化和分割性能。
III Methodology
在本节中,作者介绍了TP-UNet模型(如图2所示),该模型通过设计Temporal Prompt模块来解决医学图像分析中的时间信息遗忘问题。此外,作者还利用Semantic Align模块来弥合时间 Prompt 和图像模态之间的语义鸿沟。这两个关键组件的组合显著提高了TP-UNet在医学图像分割方面的性能,使得动态图像的分割更加精确和一致。
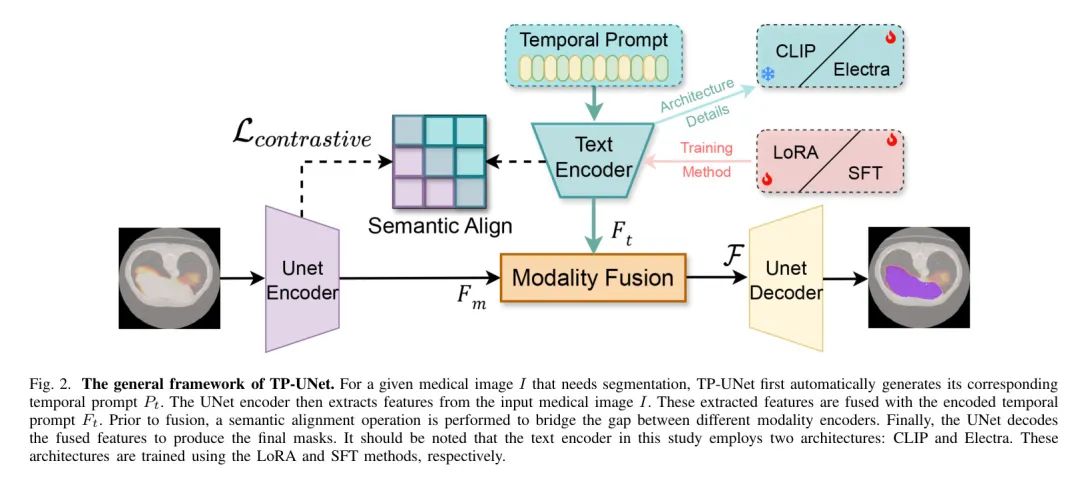
Temporal Prompt
时间信息在提高模型分割性能中起着关键作用。作者制定了一套 Prompt 来指导模型理解医学图像的时间信息。在本研究中,时间信息表示为 ,表示该信息映射到区间 [0, 1]。器官的发生概率在这个区间内遵循正态分布,使模型能够理解不同时间戳器官出现的不同概率,从而相应地调整对不同器官的关注度。本研究中定义的时间 Prompt 模板如下: "这是(MRI / CT)的[器官]的[]。" 在这里,可以选择医学图像类型和器官,而 由一组切片的尺寸决定。
在本研究中,时间 Prompt 是自动生成的。在将 Prompt 输入到 TP-UNet 之前,使用 numpy 和 pandas 库根据医生选择的图像类型自动创建一套 Prompt 。
在某些情况下,放射科医生可以通过拖动选择所需的时间戳范围,从而选择分割范围。这使得 TP-UNet 在推理过程中节省大量时间,只需为指定切片范围生成 Prompt 。为单个切片生成时间 Prompt 所需的时间不到 1ms,这对放射科临床应用具有非常重大的意义。
Multimodal Encoder
首先,作者将输入医学图像定义为I,生成的时空 Prompt 定义为P_t。对于需要分割的文本式时空 Prompt 和医学图像,作者设计了一个多模态编码器。对于输入文本模态P_t,作者采用了两种编码方法。第一种方法利用了流行的多模态文本编码器CLIP[9]。
然而,CLIP在处理通用自然语言时表现良好,但直接将其应用于医学文本可能会引入一个领域差距。因此,作者使用参数高效的微调(PEFT)[10]和LoRA[11]方法,以更有效地适应CLIP到作者的任务。作者使用的第二种文本编码器是Electra[12],另一个流行的文本编码器。作者在实验部分比较了这两种编码器的性能。作者在预训练的Electra模型上进行了有监督微调(SFT)[13]。两种微调的文本编码器都表现出良好的性能。
在医学图像模式下,作者使用传统的UNet方法进行分割。作者将UNet提取的低级语义与时间 Prompt 相结合,以引导模型在时间信息的基础上进行更有效的分割。融合方法的详细内容将在第三部分D节中介绍。
Semantic Align
在这个背景下,作者定义了编码图像特征 和文本时间 Prompt 编码特征 。在模态融合之前, 经过一个 UNet 编码块,而 通过文本编码器。由于两个模型的网络结构不同,它们来自不同的语义空间,可能导致融合后性能下降。因此,在模态融合之前对 和 的语义对齐变得至关重要。为了实现这一点,作者引入了一个语义单模块,旨在在批处理中将语义相似的 和 更靠近,同时将语义不同的 和不对应的 推得更远。因此,第一个对比损失函数是针对第 i 对的图像到文本对比损失:
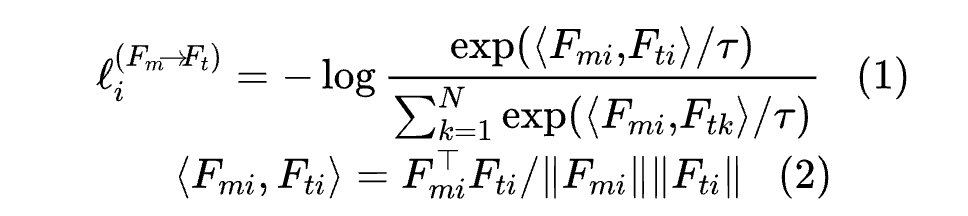
其中, 表示一个温度参数。
第二损失函数是针对第i对的文本到图像对比损失:
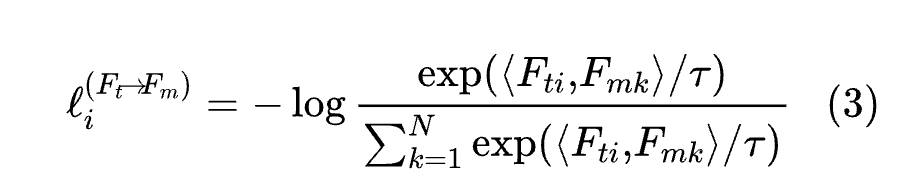
最后,作者需要优化的损失函数是:
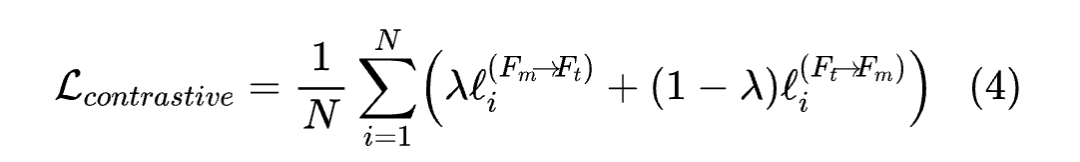
当是一个标量权重时,通过语义对齐模块,不同模态的语义表示被对齐。这为后续模态融合奠定了坚实的基础。
Modality Fusion
temporal prompt 对模型的分割性能至关重要。因此,应加大对时间 Prompt 模态与视觉模态之间模态融合设计的关注度。因此,作者设计了交叉注意力机制,其表示如下:
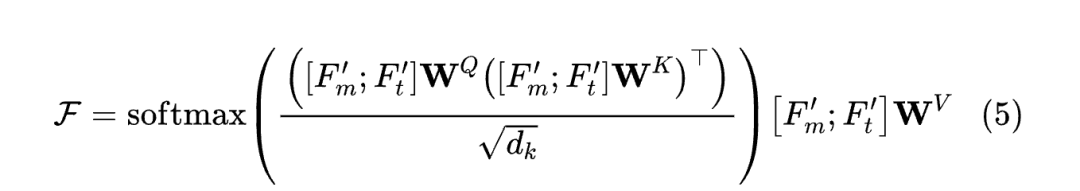
其中 表示连接操作, 是像素级注意图, 是一个缩放因子。 和 是 和 的投影。, 和 是相应的权重矩阵。最后,将特征图 与 UNet 的第一级 Shortcut 特征图进行拼接。在经过卷积层和 ReLU 激活函数后,通过 1×1 卷积层生成最终分割图像。
IV Experiments
Experimental Settings
Iv-A1 Dataset
UW-Madison数据集收集:1 该数据集来源于威斯康星大学麦迪逊分校卡罗琳癌症中心的多位患者的MRI扫描图像。它主要由结肠和胃区域的MRI图像组成。
作者称之为UW-Madison数据集[24],并将其按照7:1:2的比例划分为训练、验证和测试集。其中,训练集包含26746张图像,验证集包含3820张图像,测试集包含7642张图像。
LITS数据集收集: LITS[25]是肝肿瘤分割基准测试的缩写。数据和分割由世界各地的多个临床站点提供。该数据集包含130名患者的CT扫描。但是这些扫描是3D nii文件,作者需要的是2D切片。作者将LITS数据集分为58638个2D切片,但其中许多2D切片也是冗余的。作者最终选择了具有序列信息的10967个2D切片,并按照7:1:2的比例将其划分为训练、验证和测试集。
Iv-A2 Implementation details
作者选择 Adaptive Momentum Estimation with a weight decay of 0.000001作为训练优化器。同时,初始学习率为0.00003,权重随余弦退火学习率变化;初始温度为25,最大温度为96.875。作者使用PyTorch训练框架和一些数据增强方法,如CoarseDropout、HorizontalFlip和ShiftScaleRotate。损失函数统一采用二进制交叉熵()和Tversky损失(),是解决不平衡分类问题的损失函数。
Iii-A3 Evaluation metrics
作者使用Jaccard系数和Dice系数来评估模型的性能,这些系数可以通过计算 GT 标注和预测标注之间的相似度来衡量模型的性能。它们的计算可以表示如下:
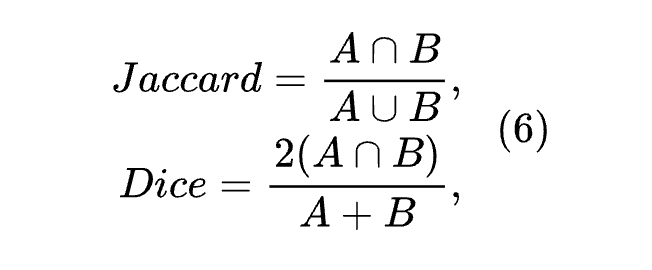
Comparison with the Baselines
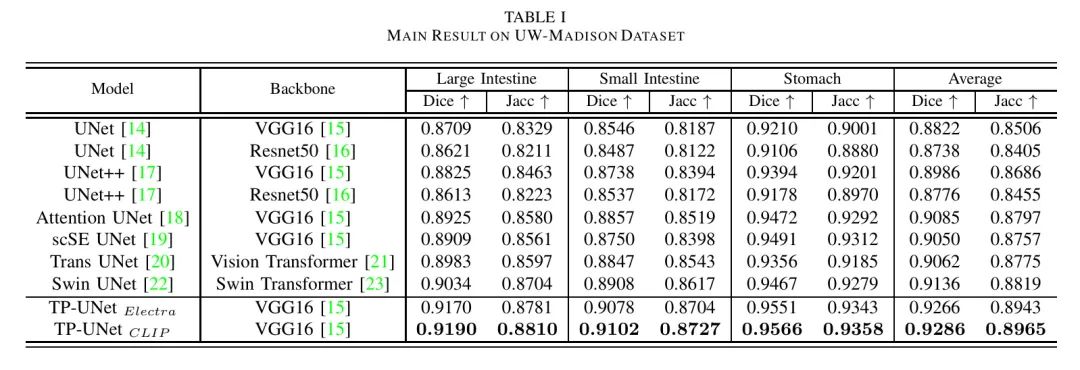
为了证明TP-UNet的有效性,作者在两个不同的数据集上进行了广泛的实验。作者选择了几种常用的医学图像分割模型进行实验比较。作者使用Jaccard系数和Dice系数来评估性能。
如图I所示,TP-UNet在UW-Madison数据集的三个器官类别(大肠、小肠和胃)以及整体平均性能上都取得了最佳性能。与UNet相比,Dice分数提高了平均4.44%,其中在小肠类别上取得了5.32%的最大提高。除了UNet之外,作者还与其他表1中列出的几种方法进行了比较。在Dice分数上,TP-UNet比当前最先进的状态(Swin UNet [22])提高了1.3%,其中在小肠类别上取得了1.7%的最大提高。
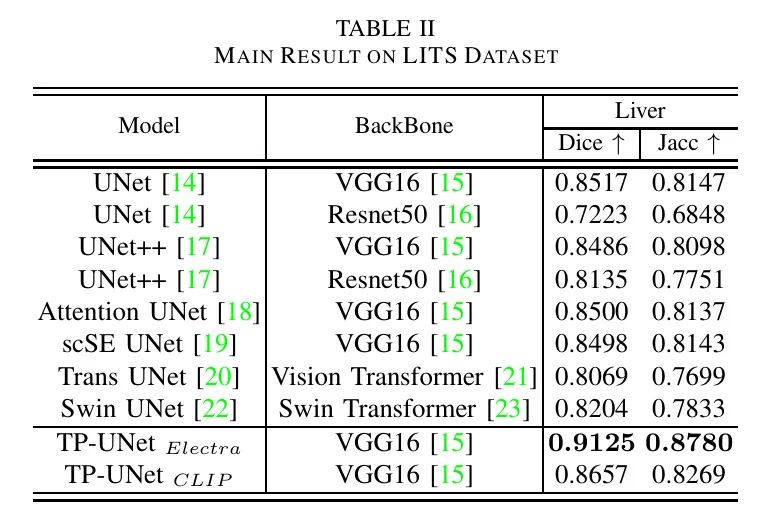
作者还在LITS 2017数据集上进行了实验。如表2所示,作者的方法在肝脏分割任务上取得了最高的Dice和Jaccard分数。与UNet相比,肝脏的Dice分数提高了6.08%,Jaccard分数提高了6.33%。在LITS 2017数据集上,TP-UNet在Dice分数上比当前最先进的方法提高了9.21%,在肠道类别中实现了9.47%的最大改进。
Case Study
本案例研究对TP-UNet与其他基准方法进行了比较分析,如图3所示。作者提出的TP-UNet在CT扫描分割方面优于传统的U-Net和基于 Transformer 的TransUNet。
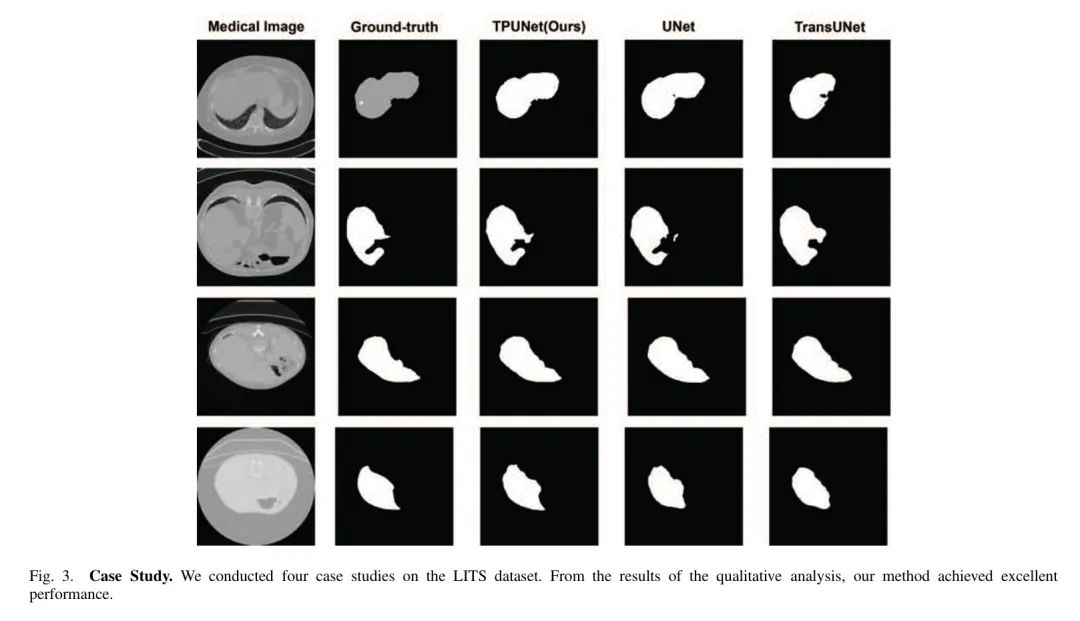
作者在LITS2017数据集上观察了三个分割结果,包括作者方法的结果。从视觉效果来看,作者的结果与真实值非常接近。作者的算法在许多常用分割技术失效的区域表现出优越性能,特别是在处理肉眼难以察觉的细节方面。
Ablation Study
作者在UW-Madison数据集和LITS2017数据集上进行了消融实验,以证明TP-UNet方法的有效性。
实验结果如表3所示,得分较低表示模块对TP-UNet模型的贡献更大。首先,作者通过从时间 Prompt 中删除时间戳,并将 Prompt 模板固定为“这是某个器官的MRI/CT”,来验证时间信息的有效性。在其他设置不变的情况下,作者在UW-Madison数据集上观察到mDice分数降低了2.1%。这进一步证实了引入时间信息的有效性,它显著有助于指导模型提高分割性能。
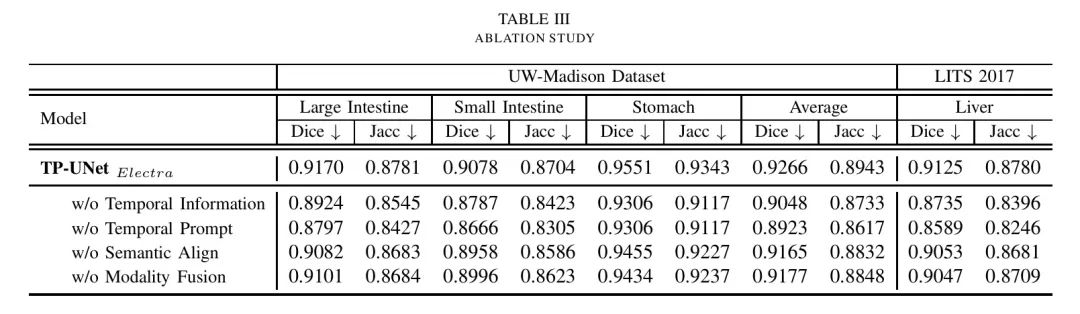
接下来,作者移除了整个时间 Prompt ,并未使用文本编码器。因此,模态融合改变为自注意力机制。从结果中,作者观察到在LITS数据集上的mDice分数降低了5.36%。这表明时间 Prompt 不仅提供了有价值的时序信息,而且选择的器官和图像类型对分割有益。
此外,作者还研究了语义对齐模块的有效性。在未进行语义对齐之前,作者直接进行了模态融合。结果显示,在UW-Madison数据集上的mDice得分降低了1.01%。这表明语义对齐对于多模态融合至关重要,因为它有助于减少不同模态编码器之间的领域差距。这种改进提升了多模态融合的效率和模型的总体性能。
作者还研究了模态融合模块的性能。作者将模态融合模块替换为在最终分割解码器之前的输入的直接 ConCat 。结果表明,模态融合模块对于TP-UNet框架至关重要。本文提出的模态融合方法既具有高效性,又具有优越性能。
通过上述四组实验,作者可以确定时间 Prompt 的有效性,语义对齐模块的必要性以及模态融合模块的高效性。这三个组件对于TP-UNet来说是不可或缺的,并且对于其卓越性能至关重要。
V Conclusion
在本文中,提出了一种用于医学图像分割的时间提示引导框架,该框架通过直接的时间提示,引导分割模型学习扫描图像的固有时间信息。
此外,作者还进一步提出了一个两阶段过程,包括语义对齐和模态融合,通过多模态对比学习和跨注意力机制,将时间提示的文本表示和图像表示进行聚合。
作者提出的框架还通过有希望的结果验证了在医学图像分割任务中时间信息的必要性。在未来的工作中,将把提出的框架扩展到更复杂的情况。
参考文献
[0]. TP-UNet: Temporal Prompt Guided UNet for Medical Image Segmentation.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号