图像+声音+文本,多模态AI为什么让各行业都在追?
原创
图像+声音+文本,多模态AI为什么让各行业都在追?
原创
CoovallyAIHub
修改于 2025-07-08 09:57:30
修改于 2025-07-08 09:57:30
【导读】
当我们谈论“看懂世界”的AI,我们真的只是让它“看”吗?CVPR 2025给出了不一样的答案:未来的AI必须是多模态的——能“看”、能“听”、能“感知”,甚至能“推理”。本篇文章带你走进CVPR 2025的多模态研究精华,看看那些令人惊叹的新模型如何改变医疗、农业、环境监测等真实世界应用。同时,文末我们将介绍 Coovally 平台的创新服务 RaaS (Result-as-a-Service),它让 AI 开发变得前所未有的简单,直达应用结果。
一、什么是多模态AI?为什么它重要?

现实世界不是只有图像。我们每天接收的信息包括声音、文字、温度、深度、气味、振动……这些信息共同构成我们对世界的理解。同样的道理,AI如果只处理图像或文本,就注定看不懂“真实”。
多模态AI就是要打破这种局限,它可以融合来自不同传感器的数据,例如图像+文本、视频+语音、RGB+深度、图像+温度,甚至图像+临床记录……让AI更接近人类的理解方式,甚至超越人类感知的极限。
CVPR 2025上的多模态研究,无疑正在重塑AI的边界。
二、SegEarth-OV:开箱即用的遥感图像分割模型

遥感影像在城市规划、灾害评估、地理信息系统等领域广泛使用,但高质量语义分割任务通常需要针对性训练,这对小团队和应用落地来说极为不友好。但SegEarth-OV完全不同——它是一个“无需训练”的开词表分割方法。它基于CLIP特征,并引入了两个关键模块
技术亮点:
- 通过CLIP提取的图文对比特征,构建类语义标签的弱监督表示;
- 提出SynUp上采样模块,显著提升低分辨率Patch的表达;
- 引入内容保持模块(CRM),减少全局偏差、保留边缘细节。
表现:
- 在17个不同遥感数据集上均表现优异,支持建筑、道路、植被等复杂结构;
- 完全无需训练,具备极强的跨数据集泛化能力。
论文地址:https://arxiv.org/pdf/2410.01768
三、IceDiff:极地海冰预测的扩散式AI模型

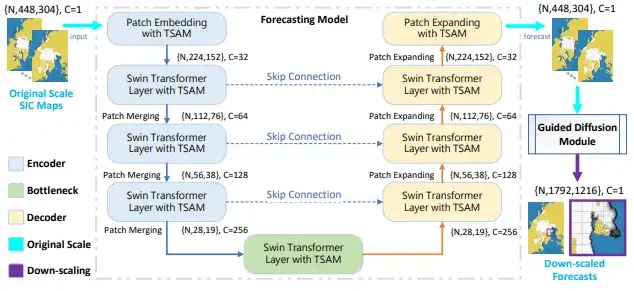
北极海冰变化对全球气候系统具有重要影响,但传统模型分辨率低、响应慢,难以应对极端事件。IceDiff结合了U-Net和引导扩散式超分辨模块,将粗略的25km网格预测下采样到更高精度。
技术亮点:
- 结合U-Net 空间预测器 + 扩散模型提升预测图像质量;
- 使用Patch-based Inference 提高推理速度;
- 动态控制“噪声引导”过程,增强对极端天气场景的鲁棒性。
表现:
- 将海冰预测精度从25km分辨率提升至亚公里级别;
- 时间连续性显著增强,有望用于灾害预警和极地研究。
论文地址:https://arxiv.org/pdf/2410.09111
四、Sensitivity-Guided Pruning:通道敏感性引导的检测适应

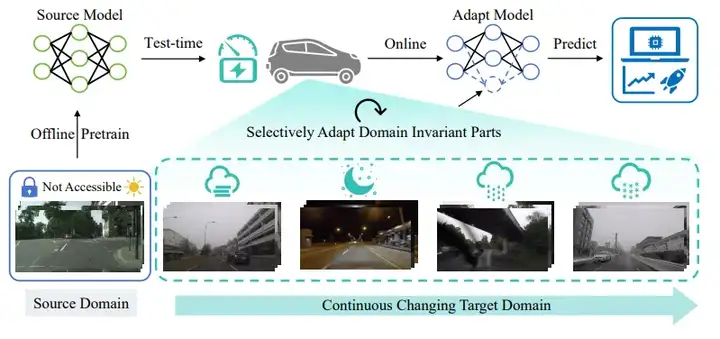
目标检测系统在现实环境中面临“昼夜切换、雾霾天气、风雪”等场景漂移,适应性差、成本高。该研究提出了通道敏感性评分机制。
技术亮点:
- 提出全局+目标特异的通道敏感性评分机制;
- 仅对鲁棒通道做微调,其余通道可裁剪;
- 不依赖源数据,适合“隐私敏感”或“源不可得”的行业应用。
表现:
- 测试中节省12%计算量,检测精度反而上升;
- 实现了对检测模型的轻量级在线适配。
论文地址:https://arxiv.org/pdf/2506.02462
五、Keep the Balance:高效RGB+X分割模型(参数仅为原模型4.4%)

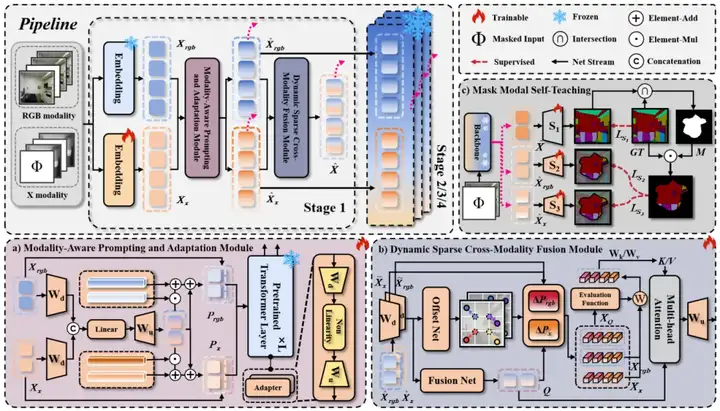
双模态(如RGB+热成像)的应用越来越多,尤其在安防、工业检测中。但现有模型普遍笨重,不适合部署。
技术亮点:
- 使用模态特定Adapter模块,避免冗余计算;
- 提出空间感知融合机制 + 动态模态掩码;
- 具备自我蒸馏机制,可在模态缺失情况下自动推理。
表现:
- 在NYUv2、FLIR等多模态数据集上达到SOTA;
- 模型仅为原始参数量的4.4%,特别适合边缘设备或实时应用。
- 这代表了多模态AI从“实验室”向“边缘设备”走出的重要一步。
论文地址:
六、M&M医疗工作坊:从研究走向临床
在M&M(Multimodal Models and Medicine)工作坊中,多位学者展示了医疗AI如何整合文本、影像、结构化数据:
Gemini for Biomedicine
Vivek Natarajan 展示的Gemini系统能同时处理CT影像和患者对话,支持多模态交互式诊断,是医疗对话系统和辅助诊断的一大突破。
RoentGen, Merlin, CheXAgent
- RoentGen:能从文本生成胸透图像;
- Merlin:一个基于15.5K CT数据训练的3D基础模型,已进入FDA审批阶段;
- CheXAgent:参数量达8B的胸片问答大模型,具备开放式诊疗推理能力。
这不仅是AI在“理解医学”,更是在“辅助医生”。
七、多模态AI+农业:真正的大挑战
农业是最复杂的多模态场景之一:土壤、气候、植物状态、农民经验……无一可忽视。CVPR 2025农业教程涵盖了:
Dr. Melba Crawford
展示如何融合多光谱、LiDAR等传感器,实现更精准的产量预测与病虫监测。
Dr. Alex Schwing
讲解了CLIP、SAM、DINO等基础模型的多模态架构机制,让农业AI具备“零样本学习”、“自动标注”等能力。
Dr. Soumik Sarkar
从实际案例出发:虫害监控、天气感知产量估计、农业对话系统……强调多模态数据整合才是解决方案的根本。
总结:多模态不只是“更强的AI”,它是“更接近真实世界的AI”
CVPR 2025让我们看到,多模态AI已经不再是实验室的前沿试验,而是正在成为新标准。AI不只是看图识物,而是能感知全局、理解人类、参与推理,真正成为跨模态的合作伙伴。
而像Coovally这样的平台,正试图把这些最前沿的技术带到普通开发者和企业面前——你不再需要理解模型结构、也不需要训练流程,只要有需求,就能用得上AI。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号