基于YOLOv11的CF-YOLO,如何突破无人机小目标检测?
原创
基于YOLOv11的CF-YOLO,如何突破无人机小目标检测?
原创
CoovallyAIHub
发布于 2025-07-10 10:15:38
发布于 2025-07-10 10:15:38
【导读】
在无人机图像中进行小目标检测,始终是计算机视觉领域的一大挑战。由于拍摄高度高、背景复杂、目标尺寸小、易遮挡等因素,现有检测算法往往难以取得理想效果。本文将为你详细介绍一款专为解决这一问题设计的模型——CF-YOLO。它基于YOLOv11构建,并在多个模块上进行了深度优化,特别适用于遥感、小目标、高复杂场景的检测任务。接下来,我们将一一揭示它背后的技术细节与实验成果。

论文标题: CF-YOLO for small target detection in drone imagery based on YOLOv11 algorithm 论文链接: https://www.nature.com/articles/s41598-025-99634-0
一、模型主要突破
CF-YOLO在YOLOv11的基础上进行了多项创新优化,主要突破包括:
- CS-FPN跨尺度特征金字塔网络:解决多次上采样和下采样造成的小目标信息衰减问题。
- FRM特征重校准模块 与 Sandwich融合模块:提升特征对齐与多尺度语义-边缘信息融合效率。
- RFAConv感受野注意力卷积模块:增强对复杂背景中目标的辨别能力。
- LSDECD轻量检测头:在保持高精度的同时显著降低参数量和计算量。

二、模型方法详解
为了应对无人机遥感图像中小目标检测中存在的特征信息缺失、多尺度融合效率低、背景干扰强等问题,CF-YOLO在YOLOv11的基础上进行模块级重构与多项关键设计优化。其核心方法体现在以下五个关键模块的构建与组合中。
CS-FPN:跨尺度特征金字塔网络
传统PANet在特征融合中采用逐层上采样和下采样的策略,易导致浅层细节在传递中逐步损失。CF-YOLO中提出的Cross-Scale Feature Pyramid Network(CS-FPN)旨在解决这一问题,构建更有效的小目标语义-细节联合表达路径。
具体而言,CS-FPN采用了双向融合机制(bottom-up 和 top-down),并在结构上引入四个不同尺度的检测头(相较于YOLOv11的三个),以增强对高分辨率、小尺寸目标的感知能力。每层特征不仅融合上下邻层信息,还通过下采样引入深层语义,再通过融合模块完成重建。
该结构的优势在于,它显式保留了更完整的高分辨率特征信息,同时借助上下文语义增强目标表征能力,对多尺度目标的检测更加稳健。
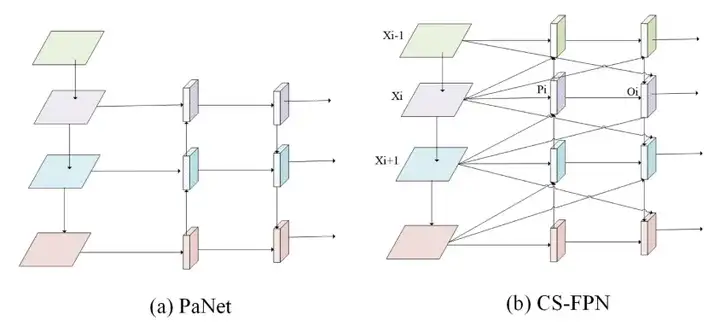
同时,为了解决不同尺度特征在融合时空间对齐偏差和语义表达不一致的问题,CS-FPN引入两个关键模块进行联合优化:FRM + Sandwich Fusion。
FRM:特征重校准模块
CS-FPN中融合信息的第一阶段采用的是FRM(Feature Recalibration Module)。该模块的设计目标是精准对齐不同尺度之间的空间位置信息,并通过通道注意力机制提升显著性区域的特征表达能力。
它主要通过以下步骤完成“信息重构”:
- 将浅层特征与深层特征通过 1×1卷积统一通道维度;
- 分别执行通道压缩并引入 Sigmoid激活函数,生成权重图(低频g_L,高频g_H);
- 采用加权残差机制对每个特征图进行强化;
- 利用“反向注意力”策略,强化浅层中的边缘细节权重,增强深层中的语义差异表达;
- 最终通过 Concat通道拼接 完成信息融合。
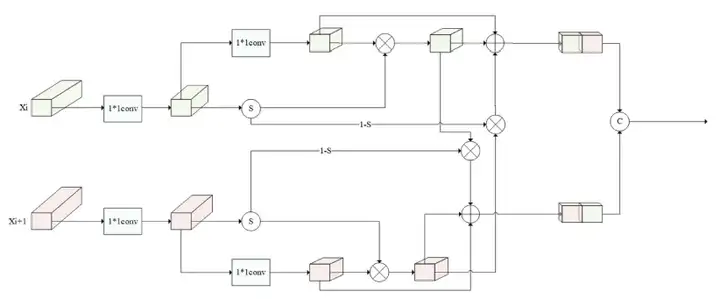
这一模块显著提升了深浅层特征之间的信息交互能力,在保持特征完整性的同时增强了边界、轮廓、纹理等关键信息的表达。
Sandwich融合模块:多分支加权融合机制
在FRM完成初步融合之后,CS-FPN结构继续引入Sandwich模块,以提升多尺度特征间的整合效率。
Sandwich模块的核心设计在于通过上采样和下采样得到的不同分支特征,与中间层特征一起进行加权融合。其融合机制采用加权求和的形式,其中各分支的权重是可学习参数,且通过ReLU和Softmax函数保证非负性与归一化。
该模块有两大优势:
- 自适应选择对检测任务更重要的特征分支,提升融合策略的动态性;
- 在靠近检测头的区域使用下采样分支替代完整三分支融合,降低计算负担。
整体上,Sandwich模块有效缓解了浅层语义不足与深层细节缺失的矛盾,是CS-FPN中的重要性能支撑模块。
RFAConv:感受野注意力卷积
针对传统卷积模块在复杂背景下对目标区域识别能力不足的问题,CF-YOLO引入了RFAConv模块(Receptive Field Attention Convolution)。该模块能够在保持模型轻量化的基础上,有效增强对多尺度目标区域的聚焦能力。
RFAConv模块主要通过以下步骤工作:
- 使用滑动窗口将输入特征划分为多个非重叠子块,构建局部感受野;
- 对这些局部区域进行平均池化和1×1卷积,提取局部上下文相关性;
- 应用Softmax函数生成权重分布图,对原始特征图中各感受野区域进行注意力加权;
- 与原始特征融合,输出具有全局感知能力的特征图。
该模块实现了局部细节建模与全局上下文建模的统一,在复杂光照和背景干扰场景中表现出更高的鲁棒性。
LSDECD:轻量空间深度增强检测头
传统YOLOv11中,各检测头之间缺乏有效的信息交互,导致多尺度检测精度有限。为了解决这一问题,CF-YOLO设计了LSDECD(Lightweight Spatial-Depth Enhanced Cross-Detection)检测头,在保持轻量化结构的同时,显著提升了特征表示能力。
LSDECD的主要特点包括:
- 统一输入特征的通道数,采用Group Normalization规范化;
- 引入Detail Enhancement Convolution(DEConv)进行细节建模,该模块包含中心差分、水平差分、垂直差分与角度差分卷积,用于增强边缘、轮廓等局部特征;
- 多个层级的特征通过共享卷积操作进行信息交互,形成跨层语义增强机制;
- 加入可学习的尺度调整参数,确保各检测头适配不同大小目标的回归能力。
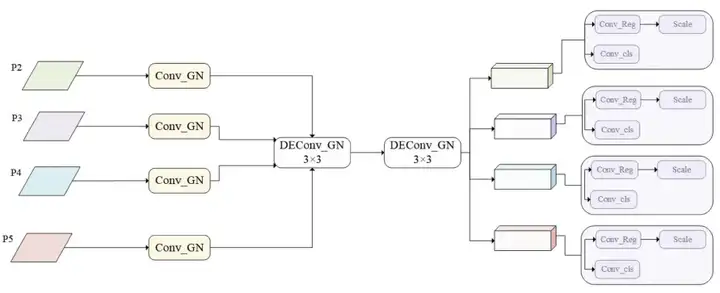
该检测头既提升了预测精度,也控制了参数规模与推理延迟,适用于资源受限场景中的部署需求。
三、实验结果亮眼表现
为了验证CF-YOLO在小目标检测任务中的有效性,作者在多个典型的无人机遥感图像数据集上进行了深入实验,并通过消融实验与横向对比评估其各模块的贡献和整体性能。所有模型均以YOLOv11n为baseline,统一输入分辨率为640×640,训练轮数300,采用SGD优化器,具体超参数设置详见原论文。
消融实验分析
为评估各模块对整体性能的影响,论文设计了逐步引入模块的消融实验,包括CS-FPN、FRM、Sandwich融合、RFAConv和LSDECD检测头。
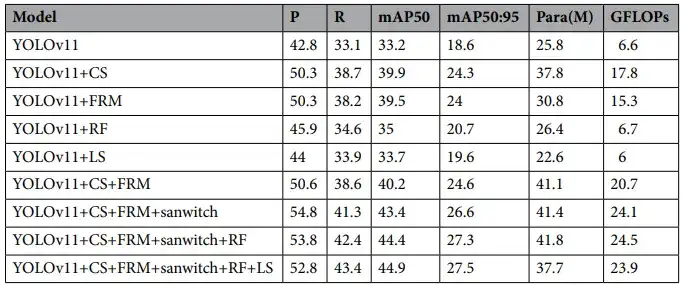
分析结论:
- 单独引入CS-FPN结构即带来显著mAP提升,证明其在多尺度融合上的有效性;
- FRM模块进一步改善了特征对齐问题,提高精度与召回率;
- Sandwich模块在保留浅层细节的同时,提升上下层特征的交互表达;
- RFAConv增强了模型对复杂背景的感知鲁棒性;
- LSDECD检测头通过差分卷积与语义交互显著提高了小目标检测性能。
最终完整CF-YOLO模型在精度提升的同时,保持了极具竞争力的参数量与计算效率。
特征融合策略对比实验
作者进一步对比了不同特征融合策略在检测性能上的差异,包括传统融合、单独FRM或Sandwich模块,以及两者联合使用。
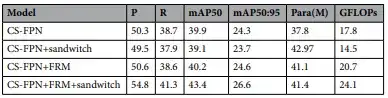
结论表明:
- FRM与Sandwich各自都有提升效果,但其组合才能实现性能最大化;
- 两阶段融合机制在边缘保持与语义建模之间达成平衡,提升整体mAP值;
- 该策略特别适合高密度小目标场景,如城市街道和人群密集区。
主流模型对比实验
为了验证CF-YOLO的综合性能,作者将其与YOLOv5、YOLOv8、YOLOv10、RT-DETR等多种主流轻量级或中量级检测模型进行了全面对比。
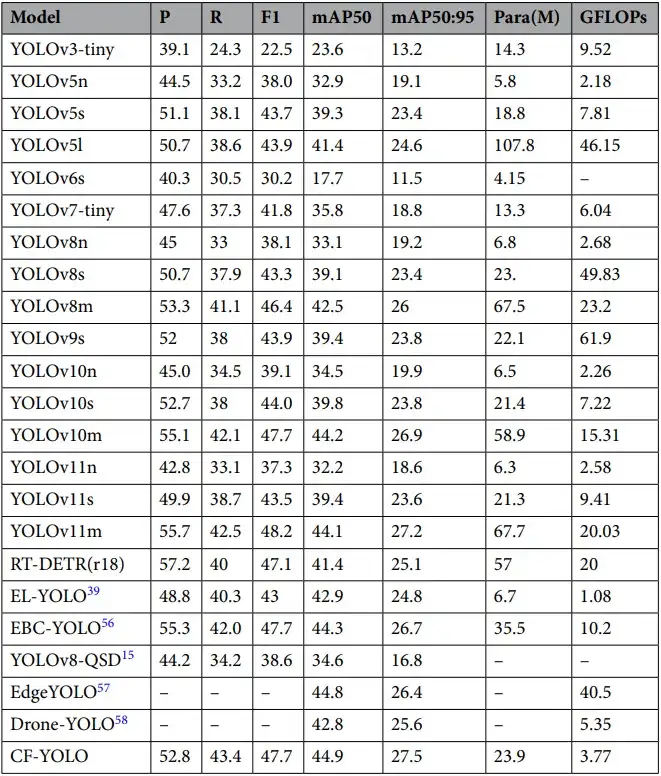
主要发现:
- CF-YOLO在mAP50和mAP95上均优于YOLOv8s和YOLOv10m等更大模型;
- 尽管模型体积更小,但在小目标类别(如行人、非机动车)上的识别能力更强;
- 参数控制在4M以内,非常适合部署于边缘设备或嵌入式无人机平台。
不同数据集上的性能对比
TinyPerson数据集
该数据集包含大量极小尺寸行人目标,检测难度极高。
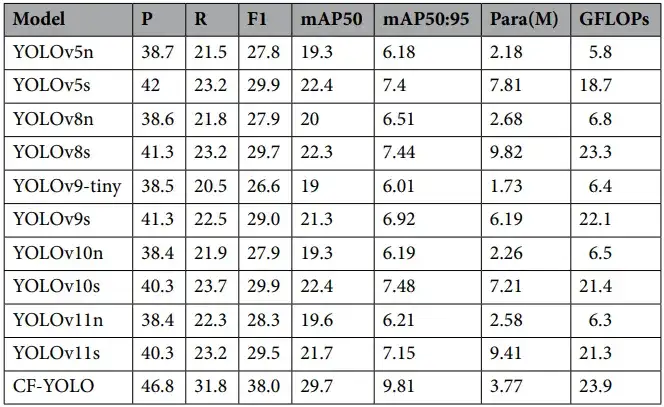
CF-YOLO在该数据集上的表现:
- mAP50提升超10个百分点;
- 对远距遮挡目标识别能力显著优于YOLOv5/8系列;
- 展现出良好的高密度场景鲁棒性。
HIT-UAV数据集
该数据集涵盖夜晚、红外、复杂天气等场景。
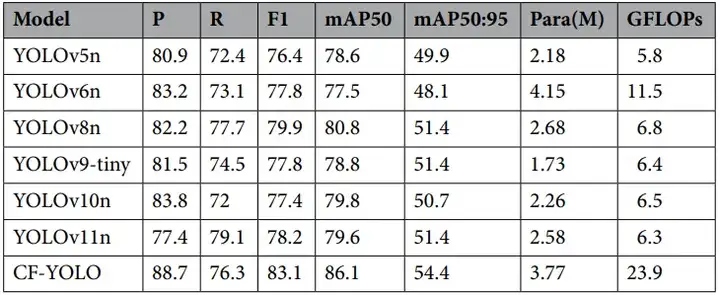
CF-YOLO在该数据集上的表现:
- F1分数大幅领先YOLOv11n与YOLOv8n;
- 对红外图像下边缘模糊目标仍能稳定定位;
- 表明其在特征表达上的泛化能力更强,适用于高复杂遥感任务。
检测可视化对比分析
为了进一步直观展示模型优势,作者展示了多组检测结果的可视化图像,包括远距行人、遮挡目标、夜间场景等。


可视化分析显示:
- 在复杂背景中,CF-YOLO能够保持清晰的边界定位;
- 对极小目标(如远处骑行者、车辆)具有更高的召回能力;
- 检测结果更加稳定,漏检率显著下降。
总结与展望
CF-YOLO在小目标检测任务上取得了令人瞩目的成就,其核心优势可以总结如下:
- 构建更鲁棒的多尺度特征融合结构,有效保留小目标边缘信息;
- 提出位置校准+加权融合协同机制,显著提升特征交互质量;
- 引入感受野注意力卷积与跨层检测头设计,增强语义理解与特征聚合能力;
- 在多个挑战性数据集上取得领先精度,尤其适配无人机视角任务场景;
- 在保持模型轻量化的前提下实现性能飞跃,兼顾精度与推理效率。
不过,也需要注意:由于结构引入较多模块,CF-YOLO在计算复杂度上仍略高于原始YOLOv11n模型,未来仍需在模型压缩、模块轻量化与动态调整机制上继续深入探索。
展望未来,CF-YOLO为远距离、复杂环境下的小目标检测提供了全新范式,特别适合应用于安防监控、应急救援、农业管理等场景,值得相关研究者与工程团队重点关注。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号