YOLOv12 对比 YOLO11:注意力机制如何重塑实时目标检测的竞争格局
原创
YOLOv12 对比 YOLO11:注意力机制如何重塑实时目标检测的竞争格局
原创
CoovallyAIHub
发布于 2025-09-02 10:44:53
发布于 2025-09-02 10:44:53
YOLO11 延续了 YOLO 系列以 CNN 为核心、高度优化的传统,通过架构和训练方法的渐进式改进,持续提升检测效率与精度。YOLOv12 则转向以注意力机制为中心的设计,融合高效的区域注意力、FlashAttention 以及 R-ELAN 式特征聚合机制,显著缩小了 Transformer 式建模与实时检测速度之间的差距,在多项基准测试中以可比的延迟实现了更高的 mAP。如果您的项目需要成熟稳定、支持完善的推理流水线及边缘部署方案,推荐选择 YOLO11;如果您追求更先进的注意力驱动改进,并能够接受相应的内存和实现开销,YOLOv12 是更合适的选择。
值得一提的是,Coovally 模型训练平台已经全面集成 YOLO11 和 YOLOv12 等主流模型,为用户提供从训练到部署的一站式解决方案,大幅降低算法选型和工程实现的复杂度。

模型数据集.GIF
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
一、为什么这一比较至关重要
YOLO 系列始终是机器人、无人机和视频分析等实时应用中最受欢迎的检测器架构。YOLO11 到 YOLOv12 的迭代不仅体现了技术上的微调,更标志着一场根本性的架构转向:从基于 CNN 的主干网络与特征融合策略(11),迈向以高效注意力机制和新型聚合模块为核心的设计(v12)。对于需严格控制延迟和资源的系统而言,这些差异将直接影响模型的精度、推理速度和内存占用——因此清晰理解两者区别显得尤为关键。
二、核心差异概览
架构重点
- YOLO11:延续 CNN 主干网络的渐进优化(包括新 CSP/C3 模块、SPPF 结构、增强特征融合等),优化训练策略并提升部署兼容性。其设计强调稳健性、广泛硬件支持与高速推理。
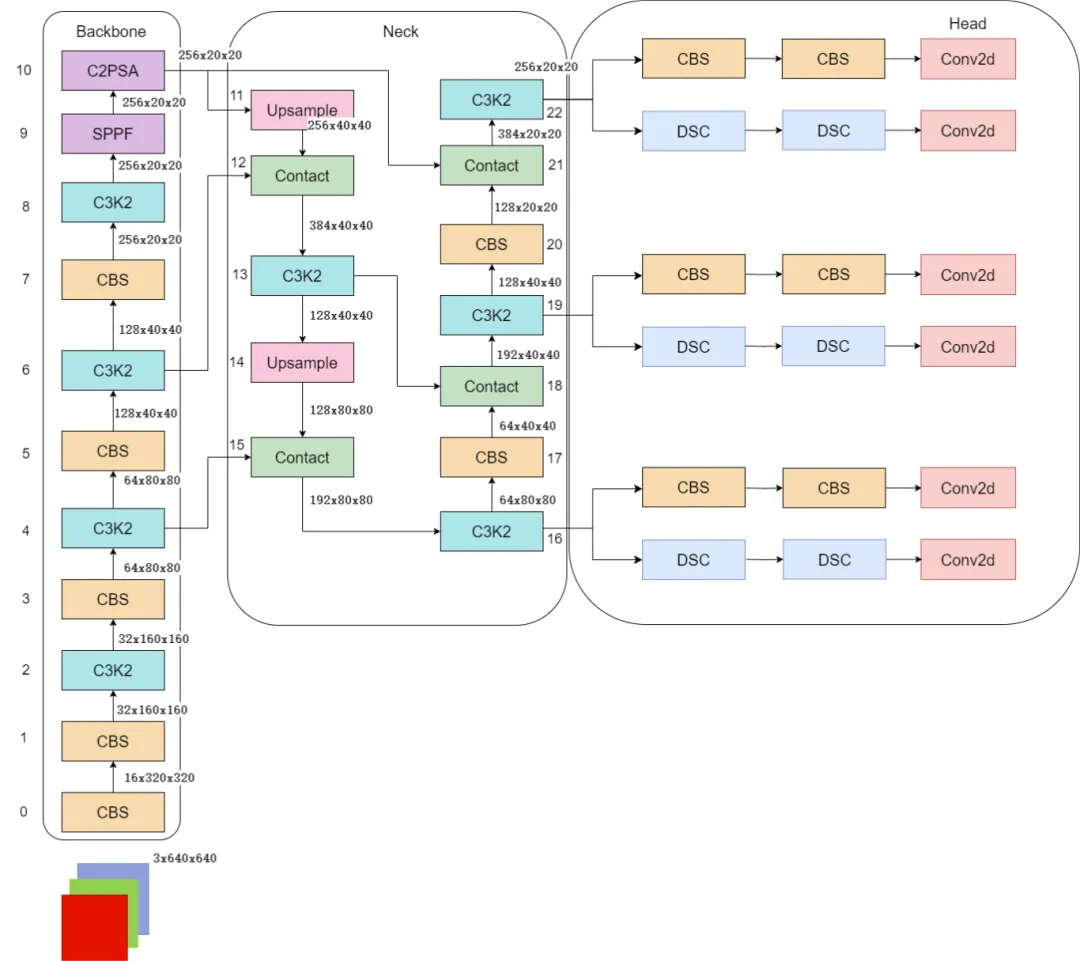
图片9.png
- YOLOv12:以注意力机制为核心,引入区域注意力、FlashAttention 和残差高效层聚合网络(R-ELAN),在低计算开销下有效捕捉全局上下文信息,显著提升模型表达能力。
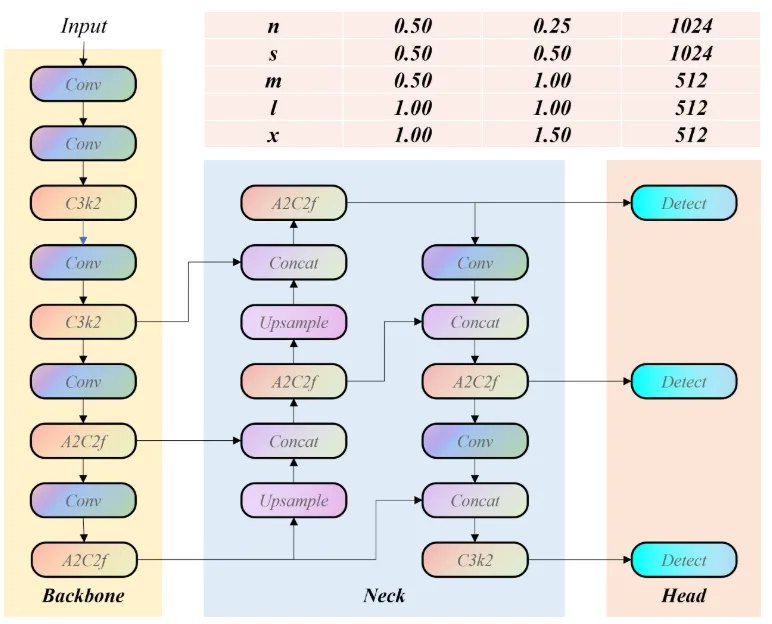
screenshot_2025-09-01_14-51-26.png
精度-速度权衡
YOLOv12 借助高效的注意力设计(如区域注意力和 FlashAttention),在维持与 11 相近延迟的同时,持续提高 mAP 指标。论文中报告,同等规模模型下 v12 平均提升 1–2% mAP,而延迟基本持平或略高。
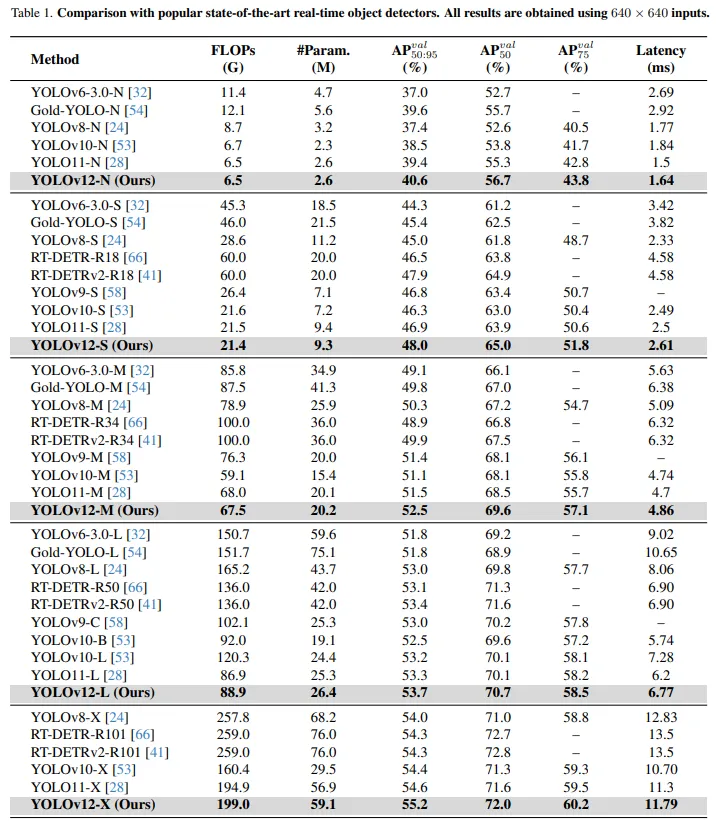
5.png
实际应用表现
- YOLO11 在现有工具链和边缘设备中通常表现稳定,内存占用可控,兼容性良好。
- YOLOv12 需依赖优化后的注意力算子(如 FlashAttention 内核),训练过程中可能出现较高的峰值内存使用,但其最终精度更高,尤其适用于复杂场景。
三、底层技术差异
主干网络与基本模块
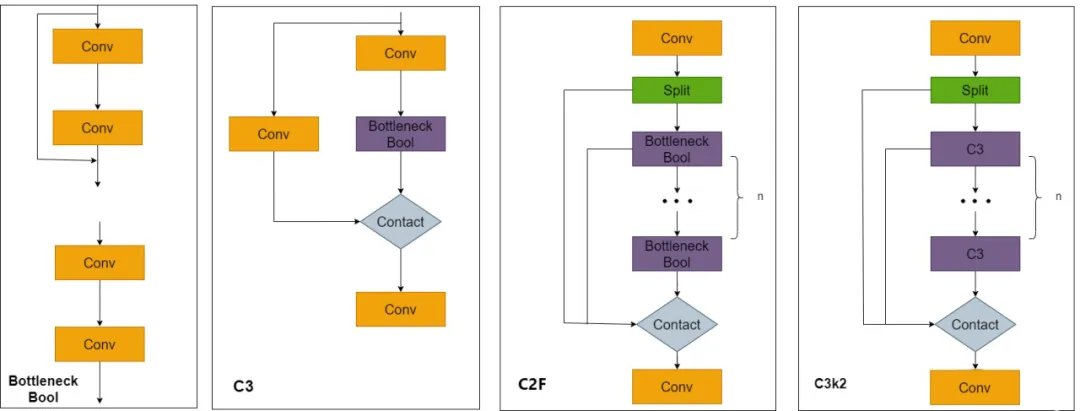
YOLO11 推出多项CNN模块优化,如C3k2、C2PSA 和SPPF变体,增强梯度流、通道交互与空间上下文建模能力,在保持速度的同时提升中小目标检测性能。
图片10.png
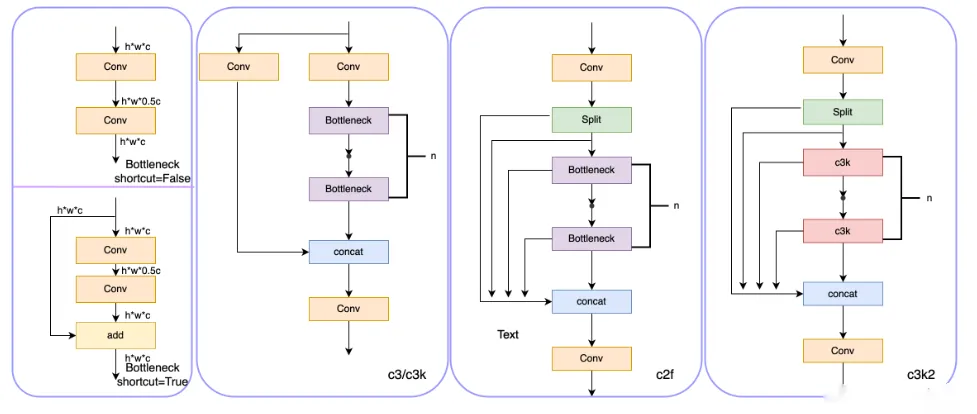
图片11.png
YOLOv12 则大幅引入注意力机制:
- 区域注意力 / FlashAttention:以近似方式降低计算和内存消耗,扩大感受野而不显著增加成本;
- R-ELAN:结合残差连接与高效跨尺度特征聚合,提升多尺度细节保持能力。
特征融合与多尺度处理
两版均沿用 FPN/PAN 结枃进行多尺度特征融合,但 YOLOv12 在融合过程中引入注意力权重,使模型能够选择性地融合跨尺度上下文信息,显著提升遮挡与小目标场景下的检测能力。
训练策略与正则化
YOLO11 继续优化数据增强(如马赛克增强和标签平滑)和损失函数(IoU 变体),提升训练稳定性。YOLOv12 在此基础上调整学习率调度和正则化方法,以适配注意力机制,避免过拟合,需严格依论文推荐设置方可达到最优效果。
四、性能基准对比
多项第三方测试与官方论文表明,YOLOv12 在 COCO 等数据集上相比11实现了稳定且显著的 mAP 提升,同时在同规模模型(Nano、Small、Medium)下推理延迟接近。例如,YOLOv12-N 在 T4 GPU 上比 v11-N 提高 1–2% mAP,延迟基本一致。
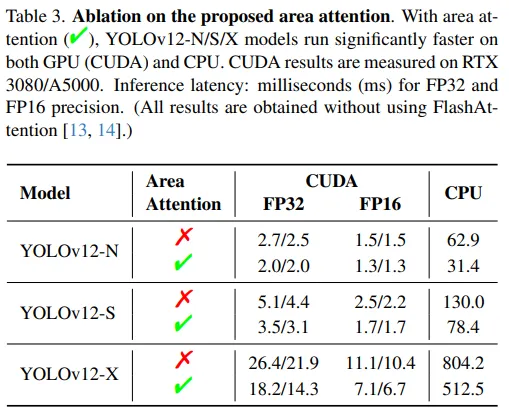
12.png
- 注意事项:
- 性能结果受实现优化(如算子融合、FlashAttention 版本)、批大小与硬件内存影响;
- 训练细节与预处理流程也可能导致结果波动;
- 若部署目标为嵌入式设备,务必在实际硬件中验证两款模型。
五、实用选型建议
选择 YOLO11,如果:
- 您需要一款经过充分验证、兼容性强、支持完善的边缘设备推理模型;
- 当前部署环境缺乏优化注意力算子或无法集成定制操作;
- 优先考虑低内存占用和工程简易性。
选择 YOLOv12,如果:
- 您追求极致精度,且具备优化注意力机制所需的工程能力;
- 任务场景包含大量小目标、遮挡或复杂背景,需依赖全局上下文;
- 希望尝试下一代以注意力为核心的 YOLO 架构。
Coovally平台还提供直观的可视化训练界面,清晰设置参数,监控训练过程(Loss, mAP等指标实时可视化)。
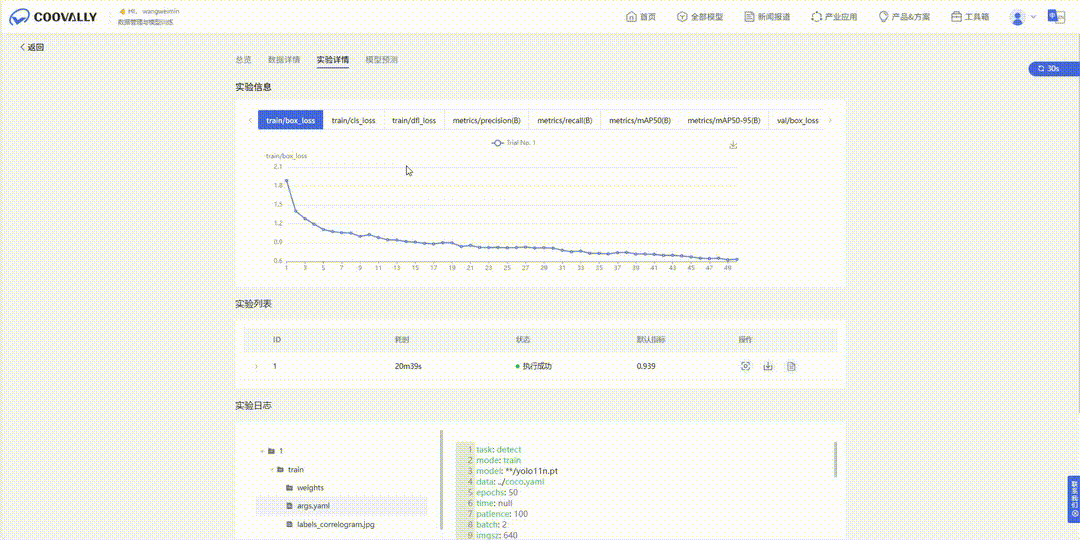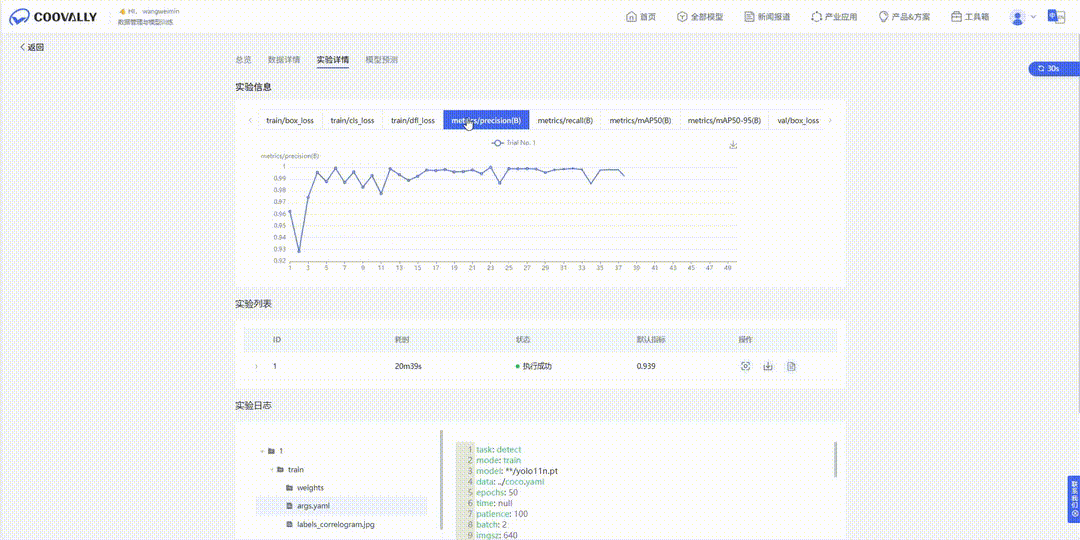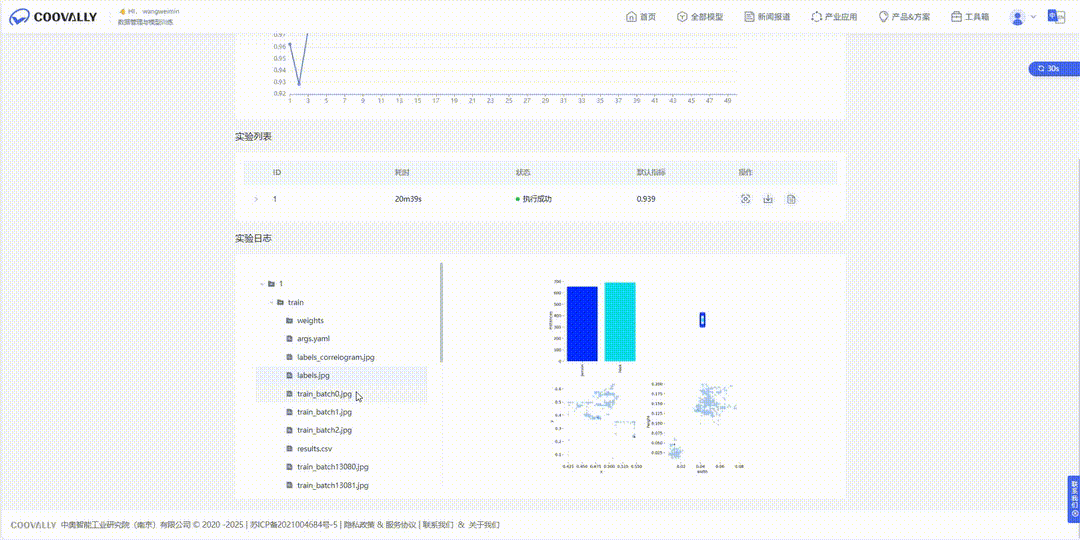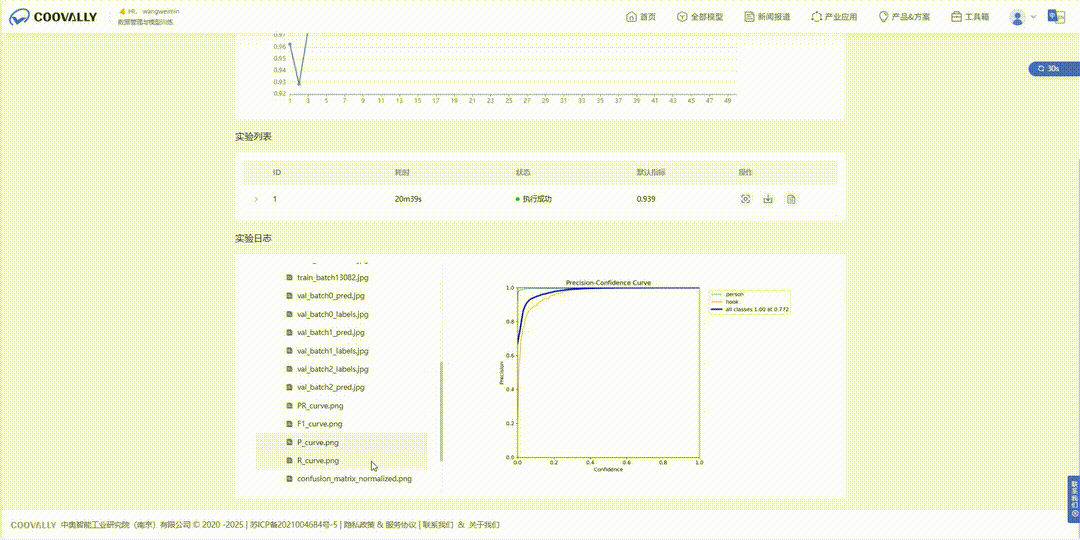
实验日志.GIF
并行实验,效率倍增! 想同时比较 YOLO11, YOLOv12在你的数据集上的表现?一键发起多个训练任务并行运行,结果一目了然,快速锁定候选者。支持分布式训练,充分利用硬件资源,大幅缩短训练时间。
六、扩展资源与阅读
- YOLO11 详解:YOLO11全解析:从原理到实战,全流程体验下一代目标检测
- YOLOv12 详解:YOLOv12来袭!打破CNN主导,实现速度精度新高度,实时目标检测的效率之王!
总结
YOLOv12 代表了一条显著的技术发展路径:通过区域注意力、FlashAttention 和 R-ELAN 等模块的精心设计,成功将注意力机制引入实时检测系统,兼顾性能与效率。而 YOLO11 仍是在生产环境和边缘部署中久经考验的可靠选择。最终决策应基于您的精度需求、硬件条件、内存限制与工程资源进行综合判断。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号