深度学习入门(六)——模块、正则化与工程调优全解析

深度学习入门(六)——模块、正则化与工程调优全解析

海棠未眠
发布于 2025-10-22 16:47:01
发布于 2025-10-22 16:47:01
深度学习训练的最后阶段,往往并不是算法问题,而是工程问题。 优化器、学习率、网络结构固然重要,但能让模型真正「稳」和「泛化好」的,是各种“看似附属”的模块:激活函数、正则化、归一化、Dropout、初始化、BatchNorm…… 这些模块构成了深度学习真正的“骨架”。 今天,我们就系统地聊聊它们的设计逻辑、推导背景,以及在实战中的细节经验。
一、激活函数:线性世界的“破壁者”
1. 为什么需要激活函数?
在神经网络里,如果每一层都只做线性变换:
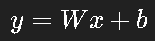
那么无论堆多少层,结果都等价于一层。 要让网络具备“非线性建模能力”,必须引入非线性函数——也就是激活函数。
激活函数的本质是:
给线性世界加一点“折叠”,让模型能表示复杂模式。
2. Sigmoid:曾经的主角
Sigmoid 是最早的激活函数之一:
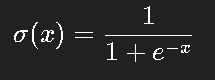
它的特性是:
- 输出在 (0,1);
- 平滑可微;
- 曾广泛用于早期神经网络(尤其是 BP 网络)。
但问题也明显:
- 导数接近 0 时容易造成梯度消失;
- 输出非零中心,训练收敛慢;
- 在深层网络中几乎无法训练。
这就是后来 ReLU 横空出世的原因。
3. ReLU:深度学习的转折点
ReLU(Rectified Linear Unit)定义极其简单:
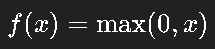
这条小小的“折线”,却成为深度学习革命的转折点。 它的优点:
- 梯度恒为 1(在正区间),不易消失;
- 计算便宜;
- 收敛速度快。
直觉理解: Sigmoid 是“压扁”的世界,而 ReLU 是“裁掉一半、保留活的那半”。
当然,它也有问题: 当输入恒为负时,梯度为 0,导致“神经元死亡”。 为此,又衍生出了很多改进版本。
4. ReLU 的变种:Leaky、PReLU、ELU、GELU
- Leaky ReLU:允许负区间有微小斜率(通常 0.01),防止死亡。
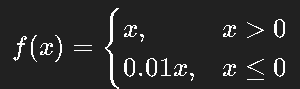
- PReLU:让负区间斜率可学习,适合特征分布变化大的场景。
- ELU:在负区间用指数平滑替代 0,让输出更连续。
- GELU(Gaussian Error Linear Unit):BERT、Transformer 的默认激活。 它让激活更“平滑”,直观理解就是: “以一定概率保留输入”,比 ReLU 更柔和。
在 PyTorch 中可直接调用:
import torch.nn as nn
act = nn.GELU()5. 激活函数的选择建议
场景 | 推荐激活 |
|---|---|
CNN | ReLU / Leaky ReLU |
RNN / LSTM | tanh / sigmoid |
Transformer / NLP | GELU |
低资源模型 | ReLU(更快) |
高精度任务 | GELU / Swish |
经验上:
如果你不知道选哪个,用 ReLU 起步,再尝试 GELU。
二、Batch Normalization:训练的“稳定器”
1. 问题背景:内部协变量偏移
在训练过程中,每层输入分布不断变化,使得下一层的学习目标也在不断改变。 这种现象称为 Internal Covariate Shift。 BN 的核心目标就是:
让每一层的输入保持稳定的分布,从而加速训练。
2. BN 的计算流程
对于一个 batch 的输入 xxx:

其中
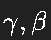
是可学习参数,用于恢复网络表达能力。
3. 实际效果
BN 的作用不只是加速收敛:
- 提高模型稳定性;
- 减少梯度爆炸;
- 具有一定正则化效果(因为 mini-batch 引入噪声)。
4. BN 的适用与替代
BN 在卷积网络中非常有效,但在序列模型(RNN、Transformer)中表现不佳,因为时间步依赖会破坏统计独立性。
此时可使用:
- LayerNorm(LN):按层归一化(Transformer 默认);
- InstanceNorm(IN):图像风格迁移常用;
- GroupNorm(GN):在 batch 太小的情况下代替 BN。
三、Dropout:防止“记忆力太好”
1. 直觉理解
深度网络往往容易过拟合,即:
训练集上表现极好,测试集上一塌糊涂。
Dropout 的想法极简单:
每次训练时,随机“关闭”部分神经元,让模型学会冗余表达。
例如 dropout rate = 0.5,表示每次随机让 50% 的神经元失活。
2. 实现与推理阶段区别
训练时:
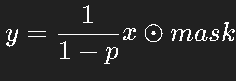
测试时不再随机屏蔽,而是直接使用缩放后的权重。
PyTorch 实现:
import torch.nn as nn
drop = nn.Dropout(p=0.5)3. Dropout 的延伸
后来又出现了一些变体:
- SpatialDropout:在卷积中同时屏蔽整个通道;
- DropConnect:随机屏蔽权重而非神经元;
- Stochastic Depth:ResNet 中随机“跳过”整个层,适合超深网络。
四、权重初始化:训练能否开始的关键
1. 为什么初始化重要?
如果初始权重太小:
- 梯度几乎为零,训练停滞。 如果太大:
- 激活饱和或梯度爆炸。
初始化的任务就是:
让每层的输入、输出方差尽可能一致。
2. 常见初始化方法
- Xavier (Glorot) 初始化: 适用于 tanh / sigmoid 激活。
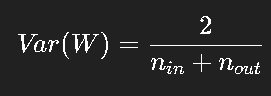
- He 初始化: 专为 ReLU 设计。
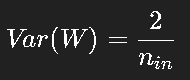
PyTorch 自动根据激活函数选择合适的初始化:
nn.init.kaiming_normal_(layer.weight, nonlinearity='relu')3. 直觉结论
- ReLU 系列 → He 初始化;
- Sigmoid / tanh → Xavier;
- Transformer / LayerNorm → 通常小随机数即可。
正确初始化往往是“能否开始训练”的第一道门槛。
五、正则化方法:让模型不再“死记硬背”
1. L1 / L2 正则化
在损失函数中加入惩罚项:

L2 会让参数趋向更小,从而减少过拟合。 L1 则倾向产生稀疏参数(部分变为 0)。
2. Early Stopping
当验证集误差开始上升时,提前停止训练。 这是一种非常有效的“软正则化”,几乎所有训练框架都支持。
3. 数据增强(Data Augmentation)
从模型外部减少过拟合的方法:
- 图像:旋转、裁剪、翻转、颜色扰动;
- 文本:同义替换、随机删除;
- 音频:时域平移、噪声叠加。
这类方法本质上是“扩充数据分布”,让模型不再死记。
六、工程调优:从“能跑”到“跑得好”
1. 监控梯度
始终要观察梯度范数是否稳定:
- 梯度过大 → 爆炸;
- 梯度过小 → 消失。
实战中可以打印梯度均值或用 grad clip:
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)2. 检查 Batch Size 与 LR 的匹配
经验法则:
当 batch size 翻倍时,学习率也应近似翻倍。
大 batch 能减少噪声,但收敛可能更差,需配合 Warmup + Cosine Decay。
3. 调试技巧
- 如果 loss 一开始就是 NaN → 学习率太大;
- 如果 loss 一直不变 → 梯度为零;
- 如果 loss 抖动剧烈 → BN 参数或数据预处理异常;
- 如果验证集性能持续下降 → 过拟合。
七、部署阶段的注意事项
训练好的模型要真正落地,还需考虑:
- BN / Dropout 的推理模式(
model.eval()); - 模型量化与蒸馏;
- 图优化(TensorRT / ONNX Runtime)。
部署中 BN 层往往会被“融合”进卷积层以加速推理。
八、结语
至此,我们从神经元讲到了优化器,从激活函数讲到了工程调优。 深度学习的学习路径看似曲折,其实始终围绕一个核心:
让模型能稳定地学、持续地学、泛化地学。
那些看似复杂的模块,并不是“炫技”, 而是为了解决一个个具体的训练痛点。
当你有一天能在 log 中看懂梯度、学习率、loss 之间的关系, 你会发现——深度学习其实是一个非常“人性化”的过程。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2025-10-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号