大模型-混合专家系统MoE介绍


1,MoE原理介绍
MoE模型利用稀疏性特点,加快了大模型训练和推理的速度。但是由于路由器倾向于激活主要的几个专家,导致每个专家被分配的token不均衡,主流解决方案集中在优化路由器分配策略,负载均衡损失和变长的批量计算。本文将按照以上思路一一介绍。
MoE定义
将传统 Transformer 模型中的每个前馈网络(FFN) 层替换为MoE层,就构成了混合专家系统,其中MoE 层由两个核心部分组成:一个门控网络和若干数量的专家系统。
- • 门控网络/路由 功能:用于决定哪些令牌 (token)被发送到哪个专家。门控网络根据输入的特征动态地分配每个令牌到最合适的专家 构成:门控网络通常是一个小的神经网络,可以是全连接层或轻量级的神经网络结构。 训练:门控网络由可学习的参数组成,并且与网络的其他部分一同进行预训练。通过反向传播算法,门控网络的参数会不断调整,以优化令牌的分配策略。
- • 专家系统 功能:每个专家负责处理分配给它的token,能够针对不同类型的输入提供专门的处理能力,从而提高模型的整体性能。 构成:前馈网络 (FFN)或其他类型的神经网络结构。每个专家可以有不同的参数和架构,以适应不同的任务需求。 讲练:其参数与门控网络一同进行训练,通过反向传播,每个专家的参数会不断优化,最小化整体损失函数。训练过程中,专家系统会逐渐学会处理特定类型的输入,从而提高模型的泛化能力和性能。
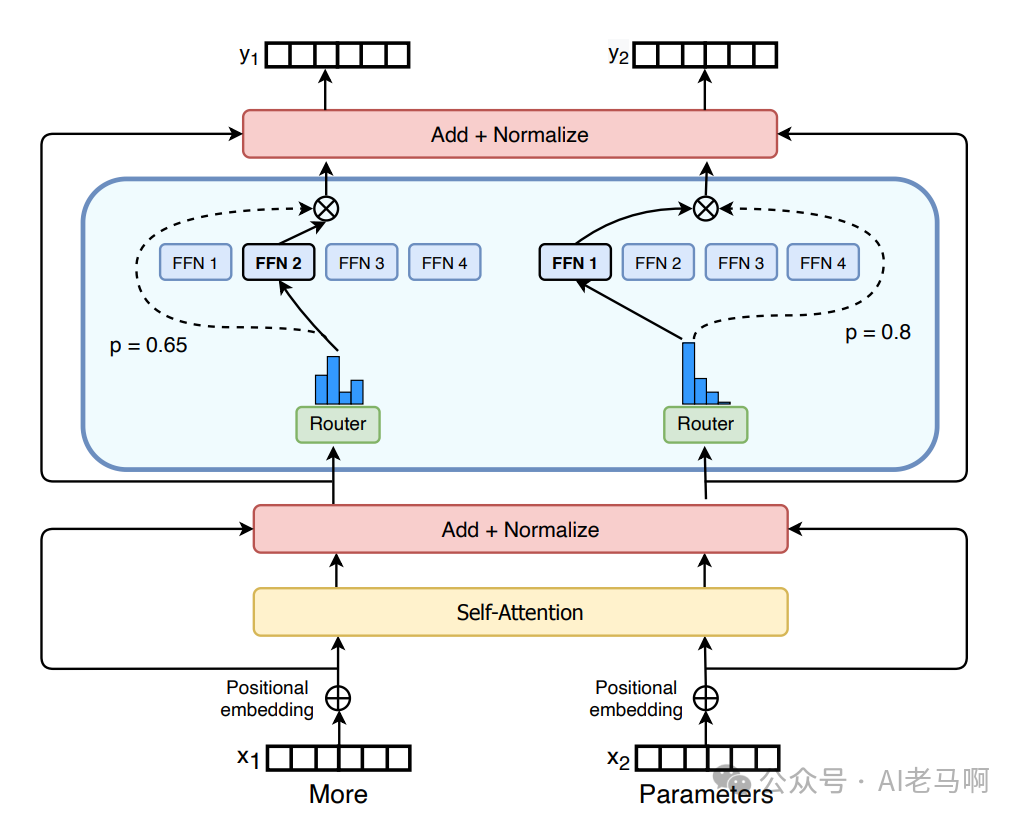
MoE系统具备的稀疏性,使得模型在训练和推理时,使用少量的计算资源,就可以完整摸型计算,而效果与稠密模型持平。
稀疏性定义
稀疏性的概念采用了条件计算的思想,稀疏性允许仅针对整个系统的某些特定部分执行计算,并非所有参数都会在处理每个输入时被激活或使用,而是根据输入的特定特征或需求,只有部分参数集合被调用和运行。
条件计算的概念(即仅在每个样本的基础上激活网络的不同部分)便在不增加额外计算负担的情况下扩展模型规模成为可能。
利用稀疏性扩大模型规模。 模型规模是提升模型性能的关键因素之一。在有限的计算资源预算下,用更少的训练步数训练一个更大的模型,往往比用更多的步数训练一个较小的模型效果更佳。
公式定义
公式1表示N个专家系统的求和过程。公式2是路由器的具体计算过程。W表示路由权重矩阵,由softmax处理后获得样本x,被分配到每个expert 的权重,然后只取前 k 的最大权重。
推理流程示例
假设 batch=2,seq=5,hidden_size=128,n=4,k=2,expert_capacity=6
步骤 | 操作 | 张量形状 |
|---|---|---|
输入 | 原始输入 | [2,5,128] |
路由计算 | 通过w_g [128,4] 计算专家分配 | [2,5,4]权重 |
TopK 选择 | 选取每个token的Top2专家 | [2,5,2]专家索引 |
分桶与填充 | 按专家索引分组,填充or截断至capacity=6 | [6,128]每个专家输入 |
专家计算 | 4个专家并行处理各自的桶 | [6,128]每个专家输出 |
加权聚合 | 按路由权重从专家输出中提取有效的token,合并为原始形状 | [2,5,128] |
2,MoE token负载不均衡问题
在混合专家模型训练中,门控网络往往倾向于主要激活相同的几个专家,这种情况可能会自我加强,因为受欢迎的专家训练得更快,因此它们更容易被选择。
问题: 如果所有的令牌都被发送到只有少数几个受欢迎的专家,导致每个专家分配到的token数量是不平均的,那么训练效率将会降低。
优化思路有两个方向:
- • 调整路由分配策略,尽可能的将token均分到每个专家系统[1]
- • 如果token在每个专家上数量不均,该如何并行批量计算[2]
专家容量和容量因子
- • 专家容量 Expert Capacity:每个专家能够处理的最大token数量。
- • 容量因子 Capacity Factor:扩大专家容量的因子,可以看做是减少丢弃token的超参数。
- • 容量计算公式,对于包含E个专家的MoE层,每个专家的容量上限为:
实际中,容量因子为全局超参数(通常设为1.0-2.0)。Batch Size 训练或推理的批次大小。Sequence Length输入序列长度。E专家数量。以上公式可以看出,如果容量因子为1,每个专家的容量为总的token均分到每个专家系统,如果大于1,则每个专家有一定的容量buffer,可以处理被多分配的oken 数量。
方案一:动态调整专家容量
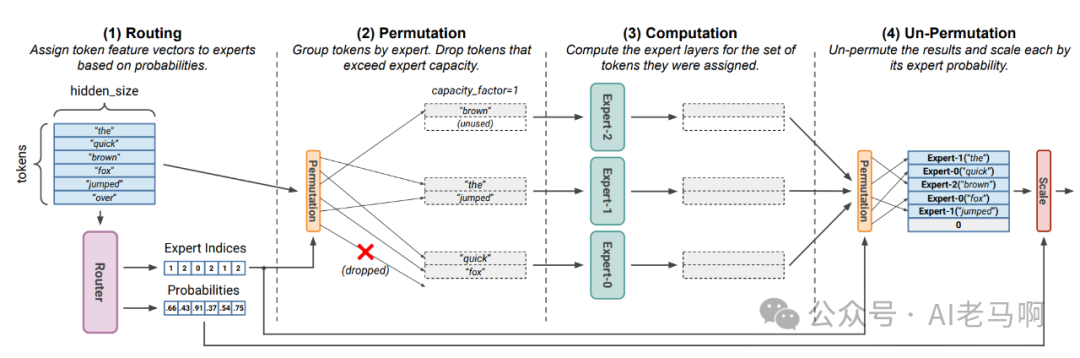
核心思想: 通过调整容量因子超参,动态的调整专家容量,这样每个专家有更大的能力处理多于的token数量。
局限:
- • 容量因子越大,被丢弃的token数量越少,但padding数量增加,造成计算浪费
- • 如果存在被丢弃的token,只能通过残差网名进行弥补,而用实验表明,丢弃token数量一定程度上会影响最终模型的效果
还有其他的一些路由策略:比如负载感知路由分数调整,在路由的分数中引入负载反惯,动态调整专家选择概率。Sinkhorn双归一化路由将路由过程建模为最优传输问题,使用Sinkhorn算法对路由矩阵进行,行(token)和列(专家)的双归一化。
方案二:可微分的负载均衡损失
核心思想: 引入辅助损失,鼓励给予所有专家相同的重要性,确保所有专家接收到大致相等数量的训练样本,从而平衡专家之间的选择。
以上问题的根源是,路由不能均分token到每个专家系统,那在损失中加入乘法因子,鼓励其均分token。加入损失有很多种,比如在 switch transformer[1] 中作者加入了一种可微分的负载均衡损失。
方案三:块稀疏对角矩阵运算
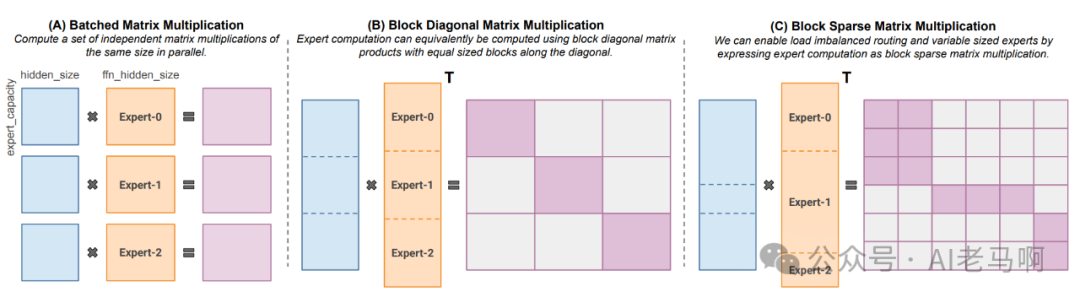
核心思想: MegaBlocks解决一个GPU上有多个专家,如何实现高效没有限制路由策略的MoE。
如果GPU上分配了E个专家,一个最简单的办法就是执行E次串行的GEMM就可以。但是这样GEMM之间没有并行,GPU利用率不高。如果硬要把E个不同维度的矩阵乘法一起算,也就是Grouped GEMM。这个操作在CUTLASS现。(bsz, m, k)*(bsz, k, n) — (bsz, m, k)
Variable Sized Batched GEMM 优化性能的核心就是,将多个GEMM操作分解成很多小矩阵块的GEMM操作,块矩阵乘法的尺寸是确定的,因为块比较小,它们可以同时计算来完成大矩阵的 Variable Sized Batched GEMM。这里小矩阵块乘法利用CULTLASS中的128*128矩阵乘。GPU同时发起很多这样的小块矩阵乘,以达到更高的计算效率。
小矩阵乘的输出位置是不连续的,因此需要一个数据结构高效访问Blocked-Sparse Matrix。这里利用了blocked compressed sparse对行列访问速度和转置操作做了优化。
详细的过程可以参考下,Megablocks[2]。
3,MoE系统优势和局限
- • 预训练速度更快,且有更快的推理速度。
具有相同参数量的稠密模型和MoE模型,在训练和推理时,MoE模型具有明显优势。因为每次计算只有少数的专家系统被激活,而不是全部的参数。这样计算量降低,相应的训练和推理时间也减少了。
- • 所有专家都需要加载到内存中,需要大量显存
从另外角度,推理时,只用到少量的专家系统,但是必须加载全部的专家到内存中,对内存消耗巨大。
- • 稀疏VS稠密,如何选择?
稀疏混合专家模型适用于拥有多台机器且要求高吞吐量的场景。在固定的预训练计算资源下,稀疏模型往往能够实现更优的效果,相反,在显存较少且吞吐量要求不高的场景,稠密模型则是更合适的选择。
- • 阻碍MoE模型大规模流行的原因有那些?
虽然MoE模型在同量级模型中,训练和推理速度快,但是面临个三个主要的问题: 1) 模型复杂度,2) 训练稳定性 ,3) 通信开销大
参考: [1] Fedus, W., Zoph, B., and Shazeer, N. Switch transformers:Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research,23(120):1–39, 2022. [2] Trevor Gale, Deepak Narayanan, Cliff Young, and Matei Zaharia. Megablocks: Efficient sparse training with mixture-of-experts. arXiv preprint arXiv:2211.15841, 2022.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号