大模型高效推理|投机解码原理介绍


投机解码是提升大模型推理速度的关键方式之一,其优势在于利用 drafter-then-verfiy的范式,很大程度解决了自回归解码一次仅生成一个token的局限,很多推理架构也配置了该特性。本文围绕投机解码主要讨论以下问题:
1)投机解码的定义和组成部分drafter和verfiy介绍 2)两类草稿模型设计的过程以及优缺点。 3)介绍贪婪解码和投机采样,两种验证规则如何平衡输出质量和效率。
1,投机解码定义和公式
1.1,投机解码定义 speculative decoding
投机解码是一种先草稿后验证(Draft-then-Verify)的解码范式,在每一步解码过程中,草稿模型先高效的生成多个草稿token,然后使用目标大语言模型,一次性的并行验证所有草稿token是否可接收,进而达到一次解码输出多个token的效果,实现大模型推理速度的加倍。
由定义可知,投机解码主要由两部分组成:Drafting 草稿模型和 Verification验证规则。
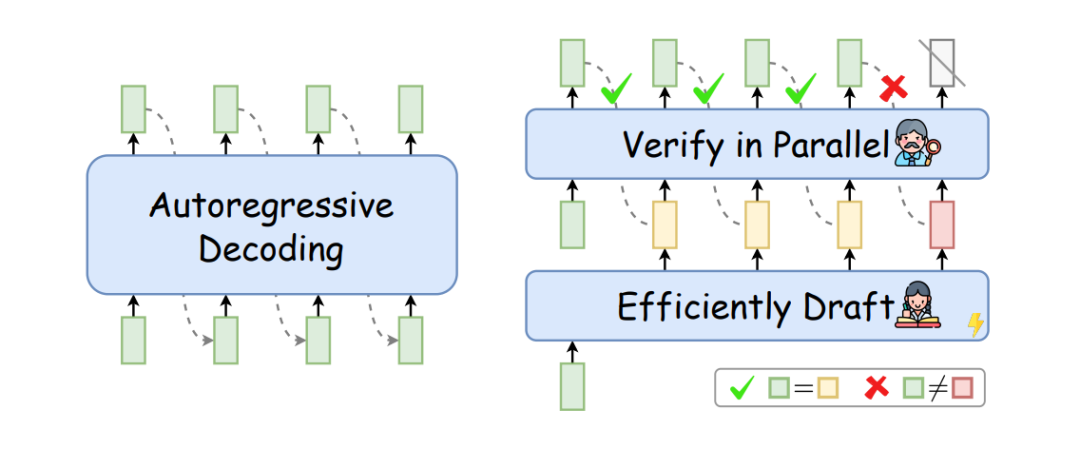
为了方便投机解码的公式定义,先来看下必要的自回归解码公式。
给定输入序列 ,自回归解码大模型 ,其生产下一个token 的公式为:
其中的q表示自回归解码模型在给定输入数列情况下,得到的条件分布概率。 从q采样得到输出token x。
1.2,Drafting 公式
草稿模型 ,主要任务是根据输入序列 ,高效的生成K个未来草稿输出 。
其中K表示草稿模型预测的token数, 表示各种草稿模型设计实现, 表示K个条件概率分布。
1.3,Verification 公式
草稿模型生成了K个草稿token,需要使用目标大语言模型 进行验证,并根据接受规则检验草稿token是否可接收。
通过目标大模型一次并行得到K个草稿模型的条件概率分布。之后需要使用验证规则 验证是否可接收。
通过以上公式可知:最终大模型的解码速度取决于,每一步解码中多个草稿token 的接收率。而接收率由多个因素决定,包括:草稿token的质量,验证标准,草稿模型和目标模型的一致性。
首先从drafter的生成token的质量说起。
2,草稿模型 drafter
草稿模型对推理速度有重大影响,关键体现在两个方面,草稿模型的推理准确度(高质量)和草稿模型推理延时。其主要解决的问题是,如何在较低的推理延时下保证高质量的输出。目前主流的草稿模型设计分为以下几类:独立草稿生成(Independent Drafting)和 自草稿生成(Self-Drafing)
2.1 独立草稿生成 Independent Deafting
模型:
一般采用与目标大模型同系列的,独立小型语言模型作为草稿生成模型,如 Llama-7B、Mistral-7B 等。而目标模型通常为上百亿的大语言模型,如 Llama-70B、GPT-4、PaLM 等。
优势:
- • 推理延时低:小型草稿模型参数少、计算量小,单步生成速度远快于目标大模型,能快速产出批量草稿序列。
- • 可针对性优化:草稿模型可独立进行轻量化训练或微调,专门优化草稿生成的准确率,提升与目标模型输出分布的匹配度,无需改动目标大模型,灵活性高。
- • 资源占用可控:小型模型的内存占用和计算资源需求低,便于部署和并行处理。
不足:
- • 模型分布不匹配:如果存在同系列的模型,还比较容易对齐。如果是不同架构,草稿模型与目标大模型的训练数据分布、语义理解能力存在差异,草稿序列与目标模型预期输出偏差较大,接受率低,导致目标模型拒绝草稿的比例高,需要频繁进行修正性生成,反而增加整体推理成本。
- • 额外维护成本:需单独维护草稿模型的训练、更新和部署,增加了模型管理的复杂度;若草稿模型与目标模型更新不同步,可能进一步加剧分布不匹配问题。
2.2 自草稿生成 Self-Drafing
模型:
仅依赖目标大模型自身完成草稿生成,通过调整生成策略,如低温度采样、小批次快速生成、截断式解码等,产出草稿序列,无需引入额外模型。
优势:
- • 分布一致性高:草稿序列与目标模型的输出源自同一模型,分布完全匹配,接受率显著高于独立草稿模型,减少修正次数,提升投机解码的整体效率。
- • 无额外资源消耗:无需部署和维护独立草稿模型,节省内存、存储和算力资源,尤其适合对资源成本敏感的场景。
- • 质量可控性强:可通过调整目标模型的生成参数(如采样温度、top-k 值)平衡草稿质量与速度,且草稿质量上限与目标模型一致,能更好支撑高质量输出需求。
不足:
- • 推理延时较高:目标大模型参数规模大,即使采用轻量化生成策略,单步草稿生成速度仍慢于小型独立模型,可能削弱投机解码的提升效果,尤其在长序列生成场景中延时优势不明显。
- • 策略平衡难度大:若为降低延时而过度简化生成策略(如减少解码步长、采用贪心采样),可能导致草稿质量下降;若优先保证质量,则难以显著降低延时,难以在 “低延时” 与 “高质量” 间找到最优平衡点。
- • 灵活性受限:草稿生成逻辑与目标模型深度绑定,无法像独立草稿模型那样针对草稿任务单独优化(如专门训练草稿生成能力),适配不同场景的调整空间较窄。
3,验证 verification 设计
在解码的每一步,生成的多个草稿token需要经过并行的验证,来保持与大语言模型输出的一致性。验证规则大体可分为:贪婪解码和投机采样。
3.1,贪婪解码 Greedy Decoding
贪婪解码就是每次仅选择概率字符最大作为输出token。对于k个草稿token通过以下公式获得。
定义草稿token第一个验证失败的token位置为c,称之为分岔点。在分岔点之后的草稿token会被丢弃。分岔点处的token使用大语言模型模型的top-one输出代替。
小结:贪婪解码一般导致较低的接收率,因为只有和大模型top-one输出相同的草稿token才会被接收。
3.2,投机采样 Speculative Sampling
为了保证高的接收率同时保证输出分布和目标大语言模型保持一致,设计了投机采样。
公式中r是从0到1均匀分布中取到的随机数, 和是关于草稿token 在草稿模型和目标大语言模型的条件概率。由公式可知到 时,草稿token时被接收的,反之被拒绝。
在分岔点c的token,采用了修正规则,重构分岔点 c 处的概率分布后,重新进行随机采样得到token。
通过对比大小模型的概率差,构建新分布,让分岔点的概率即保留了小模型 “快速草稿” 的效率,又使用大模型高置信度进行了修正。
小结:以上投机采样的token输出分布经过多位学者的理论证明,是和大模型输出token的分布一致的,所以被广泛的采用。
4,总结
通过介绍投机解码的定义和公式,也算是对其提高推理的速度的原理略知一二了。有几个关键的问题:
- • 如何平衡草稿模型生成效率和生成草稿token的准确度。
通过增大草稿小模型,复杂化生成策略等,提升了草稿token的质量后,其生成的速度会降低。但高效的生成速度,可能会影响质量,导致较低的接收率影响整体的推理速度。目前的解决方案是,将小的草稿模型和目标大语言模型进行对齐(Behavior Alignment)。对齐的方式一般采用知识蒸馏(Knowledge Distillation),也存在一些潜在的方向值得研究[1]
- • 如何的将投机解码整合到其它先进技术中。
现在基于文本的投机解码开始大量应用,但是对于多模态的解码,仍有大量的工作需要研究。
参考: [1] arxiv:2401.07851
更多精彩:
历史文章:
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号