万字解析:OpenClaw、Manus、Cursor 与 Operator 是如何构建智能体记忆的?
原创
万字解析:OpenClaw、Manus、Cursor 与 Operator 是如何构建智能体记忆的?
原创
走向未来
发布于 2026-02-03 15:26:29
发布于 2026-02-03 15:26:29
自主智能体记忆架构、核心算法以及工程实践实践指南:从OpenClaw到企业级架构
文 / 走向未来
进入 2026 年,大模型智能体(AI Agent)的发展重心已经从单纯的模型推理能力,转移到了如何独立完成长周期、多步骤的复杂任务。在这一转变中,记忆机制(Memory Mechanism)成为了系统设计的核心。
如果说 2024 年是“百模大战”的元年,那么 2026 年,毫无疑问是智能体(AI Agent)的觉醒之年。这几天,你的技术圈子一定被 OpenClaw 和它的 MoltBook刷屏了。OpenClaw 将自主智能体的概念,从玩具向生产力工具的方向上往前推进了一步。OpenClaw 的实践是一个很好的切入点,它让我们看到了记忆机制对于自主智能体的重要性。本文将基于最新的行业研究,详细解析当前主流的智能体记忆架构、核心算法以及工程实践方案,为开发者提供一份务实的参考指南。
01 从 OpenClaw 看记忆机制的可控性需求
OpenClaw(及其前身 ClawdBot/MoltBot)在记忆设计上采取了一种“本地优先”的策略。它没有使用复杂的云端数据库,而是将长期记忆存储为本地文件系统中的 Markdown 文档(即 MoltBook)。
这种设计主要解决了两个实际问题:
- 数据的透明与修正:用户可以直接打开记忆文件,查看智能体记录了什么。如果记录有误(例如错误的 API Key 或用户偏好),用户可以直接编辑文件进行修正,而无需操作复杂的数据库。
- 数据的主权:记忆文件存储在本地,可以与 Obsidian 或 Notion 等笔记软件互通,方便用户管理。
为了解决本地多任务并发可能导致的文件写入冲突,OpenClaw 引入了 “泳道队列”(Lane Queue) 系统,强制任务串行执行,确保记忆写入的准确性。
OpenClaw 的案例表明,随着智能体应用的深入,开发者和用户都需要对智能体的“记忆”拥有更高的掌控权。以此为基础,我们进一步探讨在更复杂的企业级场景下,如何构建完善的记忆系统。
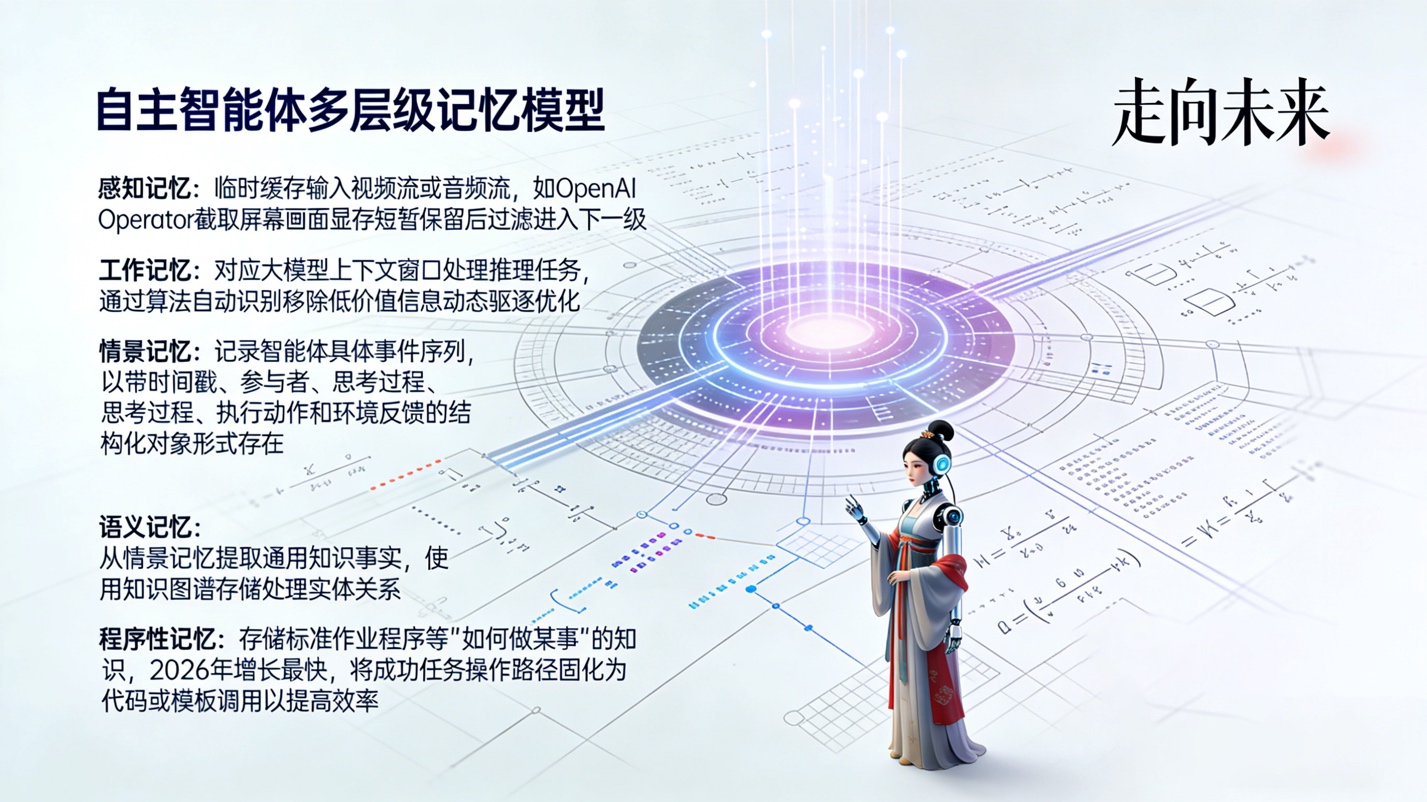
02 理论框架:自主智能体的五层记忆模型
在 2024 年前后,智能体的记忆主要依赖向量数据库(Vector Database)(参考阅读:《知识增强大模型》第三章《向量数据库》)进行简单的检索增强(RAG)(参考阅读:《知识增强大模型》第四章《检索增强生成》)。到了 2026 年,为了支持更复杂的任务,业界普遍采用了参考认知心理学的多层级记忆模型。
1.jpg
目前的通用架构包含以下五个层级:
- 感知记忆(Sensory Memory):
- 功能:用于临时缓存输入的视频流或音频流。
- 实践:例如 OpenAI Operator,它会持续截取屏幕画面,但在未触发特定事件前,这些数据只在显存中保留极短时间,经过过滤后才进入下一级。
- 工作记忆(Working Memory):
- 功能:对应大模型的上下文窗口(Context Window),用于处理当前的推理任务。
- 优化:虽然上下文窗口越来越大,但为了降低成本和提高准确率,系统会利用算法自动识别并移除低价值信息(动态驱逐)。
- 情景记忆(Episodic Memory):
- 功能:记录智能体经历的具体事件序列。
- 形式:现在的标准不再是纯文本,而是结构化的对象,包含时间戳、参与者、思考过程(CoT)、执行动作和环境反馈。
- 语义记忆(Semantic Memory):
- 功能:从情景记忆中提取出的通用知识和事实,不依赖于具体的时间地点。
- 技术:通常使用知识图谱(Knowledge Graph)来存储,以便处理复杂的实体关系。
- 程序性记忆(Procedural Memory):
- 功能:关于“如何做某事”的知识,例如标准作业程序(SOP)。
- 趋势:这是 2026 年增长最快的部分。系统会将成功的任务操作路径固化为代码或模板,下次遇到类似任务直接调用,提高效率。
03 基础设施:图数据库与时序处理
为了支撑上述复杂的记忆模型,底层的数据库选型也发生了变化。单纯的向量数据库在处理复杂关系和时间变化时存在局限,因此 JanusGraph 分布式图数据库 (参考阅读:《知识增强大模型》第七章《图数据库与图计算》)和 时序知识图谱(TKG) 开始被广泛应用。
3.1 引入图数据库的必要性
在企业级应用中,单纯依靠向量相似度检索(Vector Search)往往不够精准。
- 混合检索:JanusGraph 等图数据库支持“混合索引”。这意味着系统可以先通过向量检索找到语义相关的模糊信息(如“系统故障”),再通过图结构查询找到精确的关联信息(如“该故障与3分钟前的代码提交有关”)。
- 存储与计算分离:为了应对大规模数据,现代架构通常将存储层(如 ScyllaDB)与索引层(如 Elasticsearch)分离,以支持高频写入和快速检索。
3.2 时序知识图谱(TKG)与动态环境
传统的知识图谱记录的是静态事实(A 与 B 是朋友)。但在实际业务中,关系是随时间变化的。
2026 年的架构开始采用四元组表示法:(主体, 关系, 客体, 时间)。
- 应用场景:例如 Google Project Astra 在处理视觉记忆时,会记录物体最后一次出现的时间和位置。即使用户的物品被移动或遮挡,智能体也能根据时间戳回溯其位置。
3.3 结构化摘要技术
为了解决长文档的理解问题,微软推出的 GraphRAG 技术被广泛采用(参考阅读:《知识增强大模型》第九章《知识图谱增强生成与GraphRAG》)。最新的实践中,常结合 Leiden 算法 对知识图谱进行社区聚类,生成从微观到宏观的分层摘要,帮助智能体更好地理解全局信息。
04 核心算法:记忆的存储与遗忘
智能体不能永久存储所有信息,这会带来高昂的存储成本和检索噪音。因此,如何管理记忆的生命周期是算法的核心。
4.1 基于动量的管理机制
Amory 框架 提供了一种计算记忆“价值”的方法。它通过公式计算每条记忆的动量分数(Momentum Score):
- 热存储:高分数的记忆保留在快速访问区(如 Redis)。
- 冷存储:分数衰减后,记忆被归档到低成本存储(如 S3)。
- 语义转化:在记忆衰减的过程中,后台程序会将具体的情景(如“昨天查询了A股”)概括为语义事实(如“用户关注股市”),然后删除原始的琐碎细节。
4.2 强化学习驱动的优化
AgeMem 等方案引入了强化学习(RL)来优化记忆管理。智能体在执行任务时,除了生成回复,还可以执行 ADD_MEMORY(添加记忆)或 FORGET_MEMORY(遗忘记忆)的操作。系统会根据任务完成质量和 Token 消耗进行奖励,训练智能体自动判断哪些信息值得保留。
05 行业案例:主流智能体的记忆架构调研
不同的应用场景催生了不同的记忆架构设计。以下是 2026 年几个代表性智能体的实践方案:
5.1 Manus:通用任务处理
- 架构特点:Manus 采用显式的三文件架构来管理上下文。
- task_plan.md:记录任务总目标,只读或少写,防止任务跑偏。
- notes.md:作为草稿本,记录中间过程,定期清理。
- context.md:记录当前环境状态。
- 程序性记忆:Manus 倾向于将解决方案转化为代码(CodeAct)并存储,下次直接运行代码,而非重新推理。
5.2 Cursor:代码工程
- 架构特点:Cursor 针对代码库构建了 Merkle Tree(默克尔树) 索引。当代码发生变动时,仅重新计算受影响的部分,实现毫秒级感知。
- 语义索引:它不仅进行文本匹配,还构建代码的抽象语法树(AST),通过引用关系(如函数定义跳转)来辅助检索,确保代码修复的准确性。
5.3 OpenAI Operator:浏览器操作
- 架构特点:Operator 专注于浏览器交互,它记录的是结构化的 DOM 树历史。
- 优势:通过对比操作前后的 DOM 树差异,智能体可以明确判断一个点击或输入操作是否成功,而不仅仅依赖视觉截图。
5.4 Cognition Devin:软件开发环境
- 架构特点:Devin 使用了操作系统级别的 快照技术(Blockdiff)。
- 功能:它不仅记录对话,还记录整个开发环境(虚拟机)的状态。如果尝试修复 Bug 失败,它可以将整个环境回滚到尝试前的状态,清除所有副作用。
5.5 Microsoft Magentic-One:多智能体协作
- 架构特点:采用 双层共享账本 机制。
- 任务账本:由编排者维护,记录总体计划。
- 进度账本:由执行者维护,记录具体操作。
- 隔离性:不同角色的智能体(如网页浏览者和代码编写者)之间不默认共享所有上下文,而是通过显式的“汇报”写入账本,减少干扰。
5.6 Palantir AIP:企业决策
- 架构特点:基于 本体(Ontology) 的记忆。
- 功能:智能体的记忆直接挂载在企业的具体业务对象(如订单、设备)上。记忆中包含了对这些对象的可执行操作记录,确保与业务系统深度绑定。
06 安全与隐私保护
随着智能体掌握的数据越来越多,安全性变得至关重要。
- 机密计算(TEE):在金融等高敏感领域,采用可信执行环境(TEE),确保记忆的检索和推理过程在硬件隔离的区域内进行,即使是管理员也无法查看。
- 访问模式混淆(ORAM):为了防止攻击者通过观察数据访问频率推断隐私,高安全架构引入了 ORAM 技术。它通过读取额外的无关数据块并打乱顺序,来掩盖真实的读取意图。
07 总结与建议
综上所述,2026 年的智能体记忆机制已经从简单的向量检索升级为复杂的系统工程。
对于开发者而言,构建下一代智能体记忆系统建议关注以下几点:
- 架构融合:采用“混合图架构”,以图数据库(JanusGraph)处理关系,以向量数据库处理语义,以时序逻辑处理动态变化。
- 生命周期管理:设计合理的存储和遗忘机制,避免无效信息堆积。
- 可控性:参考 OpenClaw 的设计理念,为用户提供可查看、可修正的记忆接口。
- 场景适配:根据具体业务(如代码、浏览器操作、企业决策)选择合适的数据结构(如 AST、DOM 树或业务本体)。
智能体的记忆系统建设,是实现从“工具”向“自主智能”跨越的关键基础设施。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号