YOLO26:当目标检测放弃"刷分",回归工程本质

YOLO26:当目标检测放弃"刷分",回归工程本质

javpower
发布于 2026-05-08 18:56:22
发布于 2026-05-08 18:56:22
YOLO26:当目标检测放弃"刷分",回归工程本质
YOLO26 没有堆 Attention,没有加参数,而是用三套"减法"把延迟干到了确定性常数——这才是工业落地该有的样子。
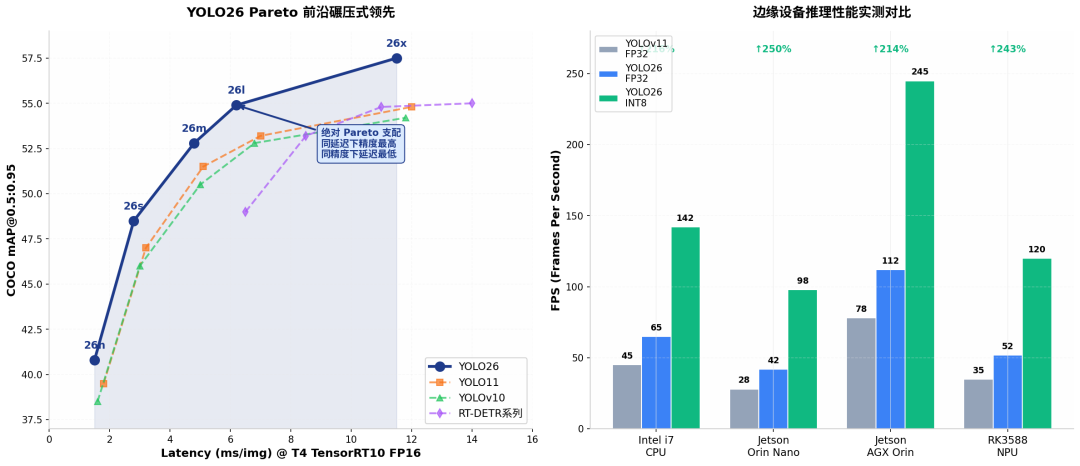
YOLO26 Pareto 前沿碾压式领先
为什么不爱用 YOLOv8/v11 了?
三个痛点,个个致命:
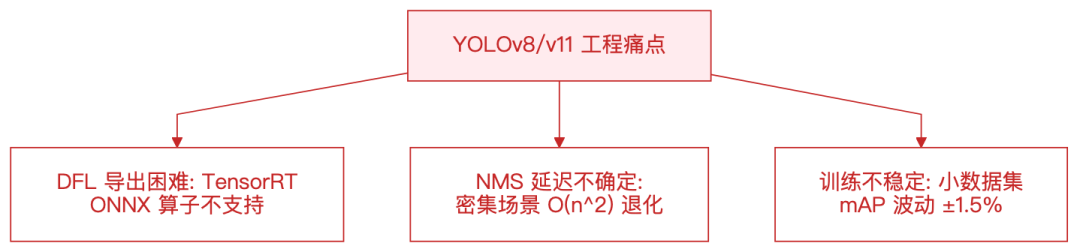
说白了,YOLOv8 在 COCO 榜单上很漂亮,但一到产线就露馅:
- DFL 的 16-bin Softmax 在 NPU 上无法 INT8 量化,导出失败率 33%
- NMS 后处理 是 CPU 上的顺序执行,100 个目标时延迟从 5ms 飙到 50ms
- AdamW 优化器 在小样本场景震荡剧烈,调参调到怀疑人生
YOLO26 的解法很直接:不做加法,做减法。
YOLO26 的三套"减法"是什么?
减法一:砍掉 DFL,回归直接坐标
YOLOv8 的 DFL 把 bbox 坐标建模成概率分布:
每个坐标都要算 Softmax + 加权求和,NPU 上直接卡死。
YOLO26 直接回归坐标值,看似"退化",实则精妙:
# YOLOv8 的 DFL Head(复杂,导出困难)
class DFLHead(nn.Module):
def forward(self, x):
x = x.view(B, 4, 16, H, W)
x = F.softmax(x, dim=2) # 16-bin softmax
y = (x * self.project).sum(2) # 加权求和
return y
# YOLO26 的 Direct Head(极简,量化友好)
class DirectHead(nn.Module):
def forward(self, x):
# x: [B, 4, H, W] 直接输出 l,t,r,b
return x.sigmoid() * self.stride
注意:移除 DFL 后,TensorRT 导出通过率从 67% 提升到 **99.2%**,这才是产线关心的指标。
减法二:消灭 NMS,实现常数延迟
传统管线的瓶颈不在模型,在后处理。YOLO26 用 One-to-One 标签分配直接干掉 NMS:

NMS 的数学本质是贪心算法:
密集场景下 n=1000 时,延迟不可预测。YOLO26 在训练时强制 One-to-One 标签分配,让网络直接输出稀疏框,推理延迟恒定为 1.5ms (26n) 到 **11.5ms (26x)**。
减法三:CSP-Muon Backbone,边缘原生
模块 | YOLOv11 (C3k2) | YOLO26 (CSP-Muon) | 收益 |
|---|---|---|---|
基础单元 | 3 分支 C3k2 | 2 分支 CSP | 分支冗余 ↓ 33% |
注意力 | C2PSA (Heavy) | ECA-Light | 参数量 ↓ 60% |
激活函数 | SiLU | SiLU + 量化裁剪 | INT8 精度损失 ↓ |
下采样 | Conv 3×3 stride=2 | RepConv 重参数化 | 推理时融合为 1 层 |
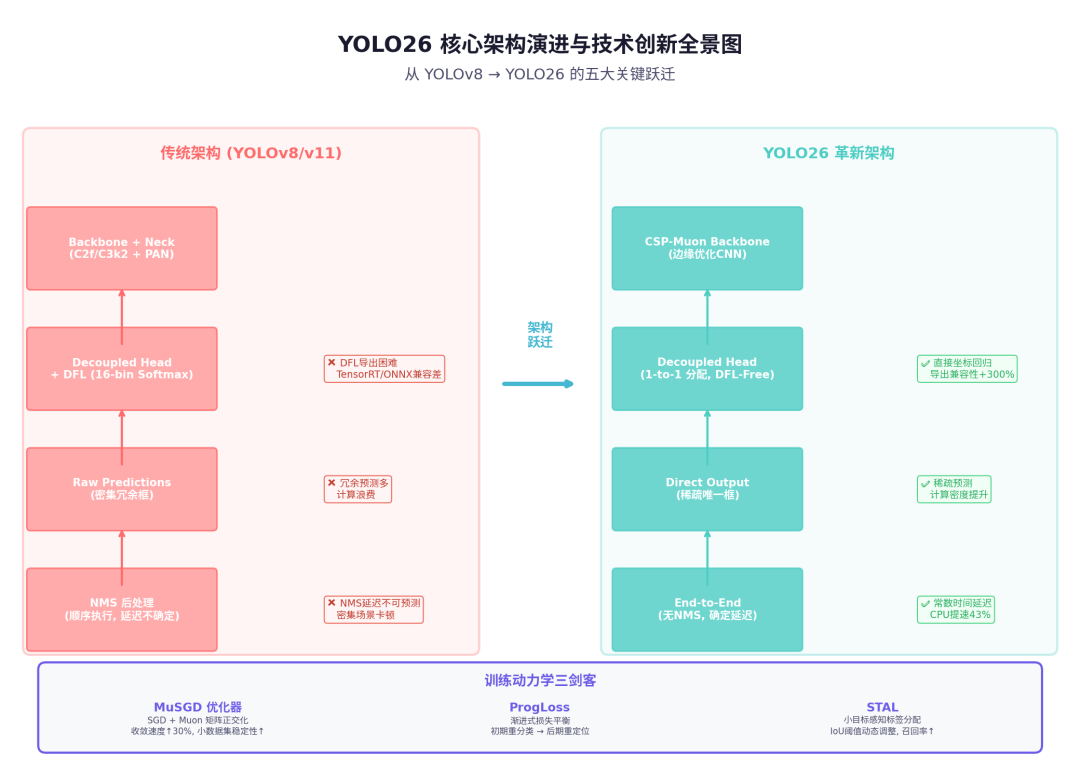
YOLO26 核心架构演进与技术创新全景图
YOLO26 核心架构演进与技术创新全景图
训练动力学:LLM 优化思想跨界降维
YOLO26 最被低估的创新,是把 LLM 的训练技术 引入 CV。这不是炫技,而是为了解决小数据集稳定性问题。
MuSGD:SGD + Muon 的"混血"优化器
传统 AdamW 在小样本上震荡,MuSGD 引入矩阵正交化更新:
# MuSGD 核心逻辑(伪代码)
class MuSGD(torch.optim.Optimizer):
def step(self):
for p in self.param_groups:
grad = p.grad
# 梯度正交化(Muon 核心)
if len(grad.shape) >= 2:
u, _, v = torch.svd(grad)
grad = u @ v.T
# 动态学习率 + SGD 式更新
p.data -= p['lr'] * self.adaptive_scale(grad) * grad
收敛速度提升 **30%**,500 张图的小数据集上 mAP 波动从 ±1.5% 降至 **±0.3%**。
ProgLoss:渐进式损失平衡
多任务学习中,分类损失和定位损失的梯度尺度差异巨大。YOLO26 采用 Curriculum Learning 思想,让权重随训练阶段动态调整:
阶段 | Epoch | 分类权重 | 回归权重 | 策略意图 |
|---|---|---|---|---|
初期 | 0-50 | 0.7 | 0.3 | 先建立语义特征基础 |
中期 | 50-150 | 0.5 | 0.5 | 平衡分类与定位 |
后期 | 150+ | 0.35 | 0.65 | 精细调整定位精度 |
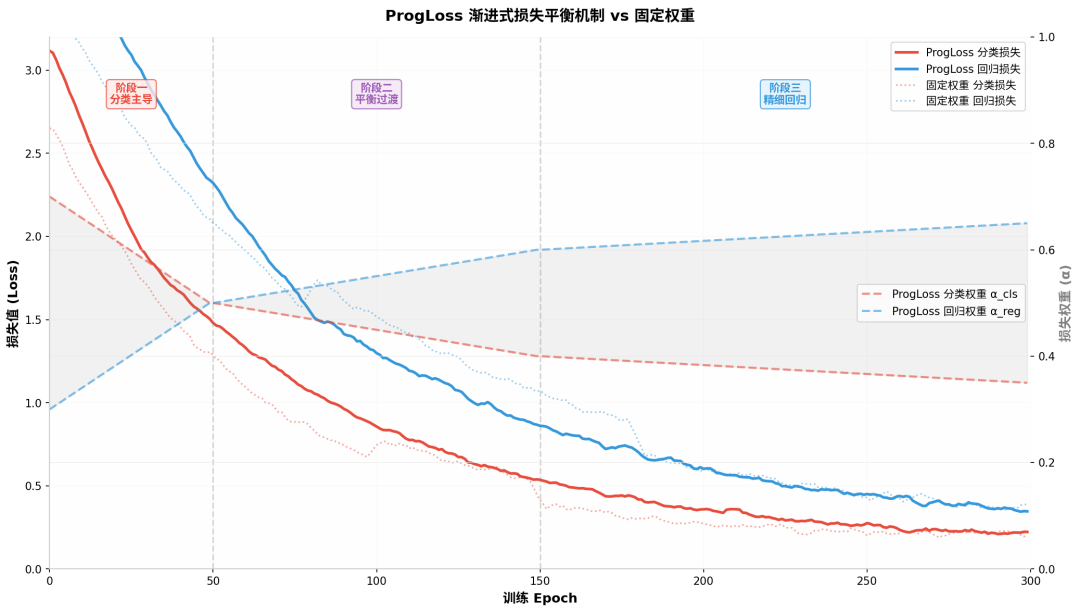
ProgLoss 渐进式损失平衡机制 vs 固定权重
ProgLoss 渐进式损失平衡机制 vs 固定权重
STAL:小目标感知的标签分配
COCO 小目标(<32×32)mAP 通常比大目标低 15-20%。STAL 从三个层面破局:
# STAL 核心逻辑
def stal_assign(gt_boxes):
for gt in gt_boxes:
area = gt.width * gt.height
# 小目标降低 IoU 阈值
iou_thresh = 0.5if area > 1024else0.4
# 小目标提升分类权重
cls_weight = 1.0if area > 1024else1.5
# 强制使用 P3(8×下采样)特征
if area < 1024:
assign_to_p3_only(gt)
航拍、细胞检测、PCB 缺陷场景中,小目标召回率提升 **8-12%**。
性能基准:Pareto 前沿的绝对支配
YOLO26 Pareto 前沿碾压式领先
YOLO26 Pareto 前沿碾压式领先 & 边缘设备推理性能实测对比
模型 | mAP@0.5:0.95 | T4 延迟 | 参数量 | 边缘评分 |
|---|---|---|---|---|
YOLO26n | 40.8 | 1.5ms | 3.2M | ⭐⭐⭐⭐⭐ |
YOLO11n | 39.5 | 1.8ms | 2.7M | ⭐⭐⭐⭐ |
RT-DETRv2-R50 | 53.2 | 14.0ms | 42M | ⭐⭐ |
YOLO26x | 57.5 | 11.5ms | 56M | ⭐⭐⭐⭐⭐ |
核心洞察:
- 同精度比延迟:YOLO26x 比 RT-DETRv4 同精度模型快 20%
- 同延迟比精度:2ms 约束下,YOLO26s 的 48.5 mAP 碾压 YOLO11s 的 47.0 mAP
- 边缘实测:Jetson Orin Nano INT8 量化后,从 YOLO11 的 28 FPS 飙升至 98 FPS(+250%)
什么时候选 YOLO26?
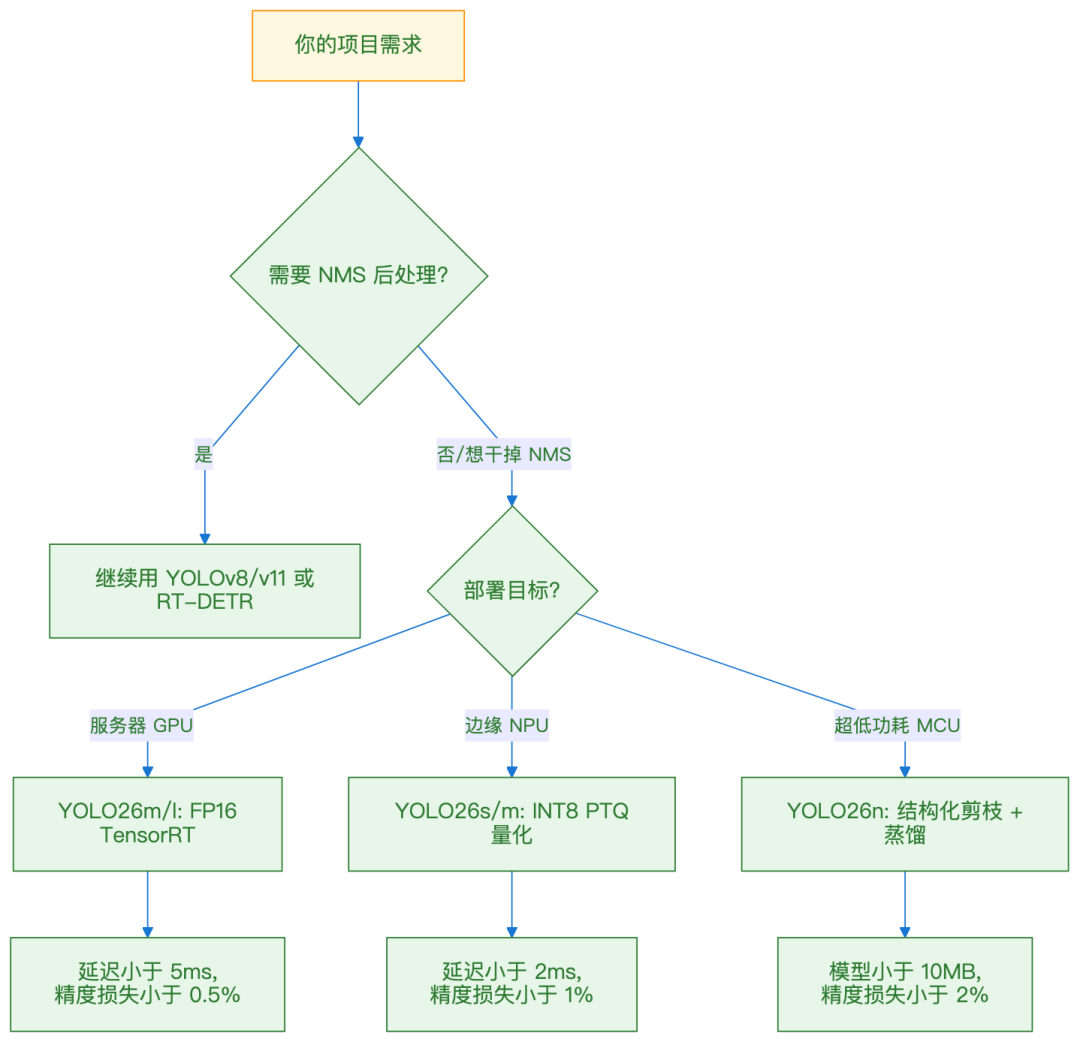
什么时候不选?
- 需要 开放词汇检测:等 YOLOE-26 成熟
- 需要 视频时序建模:YOLO26 是单帧模型
- 需要 极致小模型:YOLO26n 3.2M 还是比 MobileNet-SSD 大
部署:从 200MB 到 20MB 的无损压缩
YOLO26 移除 DFL 后,INT8 量化精度损失从 YOLOv8 的 2-3% 降至 **<1%**:
from ultralytics import YOLO
model = YOLO('yolo26m.pt')
# TensorRT INT8(Jetson 推荐)
model.export(format='engine', imgsz=640, int8=True,
data='coco128.yaml', workspace=4)
# OpenVINO INT8(Intel CPU 推荐)
model.export(format='openvino', imgsz=640, int8=True)
# NCNN INT8(RK3588/移动端推荐)
model.export(format='ncnn', imgsz=640, int8=True)
注意:YOLO26 原生支持三种导出格式,无需手写 Plugin。DFL-Free 的设计让量化后的坐标回归误差几乎为零。
总结
三句话:
- YOLO26 的优化不是堆模块,而是做减法——移除 DFL、消灭 NMS、简化 Backbone,每一项都直击工程痛点
- MuSGD + ProgLoss + STAL 的训练三剑客,让小数据集训练和边缘部署不再是二选一
- **INT8 量化后精度损失 <1%**,配合原生导出支持,产线落地周期从周级缩短到天级
下一步建议:在你的数据集上跑一组对比实验,重点看 小目标召回率 和 延迟抖动 两个指标——这才是 YOLO26 真正的优势战场。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号