DeepSeek-OCR上下文感知压缩提升识别效率

DeepSeek-OCR上下文感知压缩提升识别效率

用户2771172
发布于 2026-05-18 19:41:15
发布于 2026-05-18 19:41:15
引言
在传统大模型处理长文本时,单页文档往往包含上千词,推理计算量会激增至原来的数十倍。现有方法随内容扩展,序列长度迅速膨胀,造成服务器资源消耗剧增。DeepSeek团队通过实验发现,单张图片可用不到一百个视觉token承载大量文本,实现最高达20倍的压缩率。然而,极限压缩如何兼顾内容还原精度?市面主流OCR工具常需几千token才能识别文本,效率与准确率难以兼得。DeepSeek-OCR系统在此背景下实现突破,采用视觉编码与光学压缩技术,将冗长文本转换为极简视觉信号,实测解码准确率高达97%。该论文指出,这一新范式正在重塑长文本解析的效率边界,其底层架构创新及数据表现令人瞩目。
为什么需要光学压缩
主流大语言模型(LLM)在处理长文本时,其计算资源消耗随序列长度呈二次增长,导致大规模文档理解和长上下文推理成本高昂、效率受限。尽管OCR技术能够将图片转化为文本,但在复杂结构解析和信息压缩方面仍存在显著瓶颈,难以兼顾速度与准确率。作者指出,文本直接输入LLM会产生大量token,带来显存占用和推理速度的双重挑战;而传统OCR在多样化排版场景下易出现识别错误,且解码过程难以有效压缩信息。面对数千字且结构复杂的文档,这些方法难以同时保证精度与效率。为此,该论文提出利用视觉模态进行光学压缩,通过将文本编码为图片并借助视觉语言模型解码,以极少的视觉token高效表达大量信息,从而显著降低模型输入负担。该策略为长文本和大规模文档理解提供了全新突破,凸显了高效光学压缩系统的实际需求。
系统架构有何突破
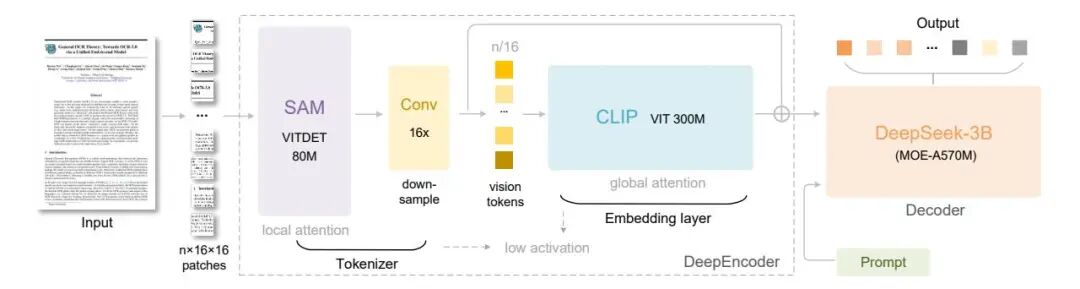
在近期的系统架构创新中,DeepSeek团队构建了高效视觉编码器DeepEncoder,实现了海量视觉信息的精准聚合。核心架构采用分层设计,首先通过窗口注意力机制的SAM模块提取关键感知特征,随后串联CLIP模型获取全局视觉知识,最后由卷积压缩模块进行16倍降采样,将庞大信息浓缩为极少的视觉tokens。这一流程显著降低了内存占用与计算成本。
DeepEncoder具备多分辨率输入能力,能够覆盖小型图片至超高分辨率报纸等复杂文档场景。作者利用动态插值位置编码及多模式联合训练,使模型在单一架构下兼容不同分辨率与切片方式,确保解析精度与部署灵活性并存。
在解码端,采用DeepSeek-3B-MoE专家混合结构,推理阶段仅激活少量专家模块,兼顾表达能力与高效运算。该解码器能够从高度压缩的视觉tokens还原原始文本信息,表现出极强还原能力。整体系统实现了端到端的光学上下文压缩,突破了传统OCR与VLM在长文本处理上的算力瓶颈,为大规模文档解析和智能数据生成带来高效解决方案。
如何实现高效识别
DeepSeek团队通过设计创新性的DeepEncoder结构,实现了高效的视觉识别。该结构将窗口注意力与全局注意力有机融合,分别由SAM和CLIP模块负责。窗口注意力聚焦于局部特征的提取,显著降低激活内存消耗,而全局注意力则强化语义整合能力,提升模型对跨区域信息的理解。两者串联,使模型在各视觉层次均能精准捕获关键信息。为压缩视觉信息,DeepSeek-OCR在特征模块间引入卷积压缩器,通过两层卷积将视觉token数量降采样至原来的1/16。即使面对千字级文档,数千视觉tokens也可压缩到几百个,极大减轻计算压力,并保持高识别精度。实验表明,仅用100个视觉token时,准确率仍超过90%,压缩率显著领先于同类方法。此外,DeepEncoder支持多分辨率和动态分配模式,允许根据实际场景灵活配置输入分辨率与token数量。Gundam模式实现局部高分辨率与全局视角拼接,适应复杂布局与大尺寸图像需求,从而确保模型在多样文档类型下均能实现高质量解析与识别。

实际效果有多强
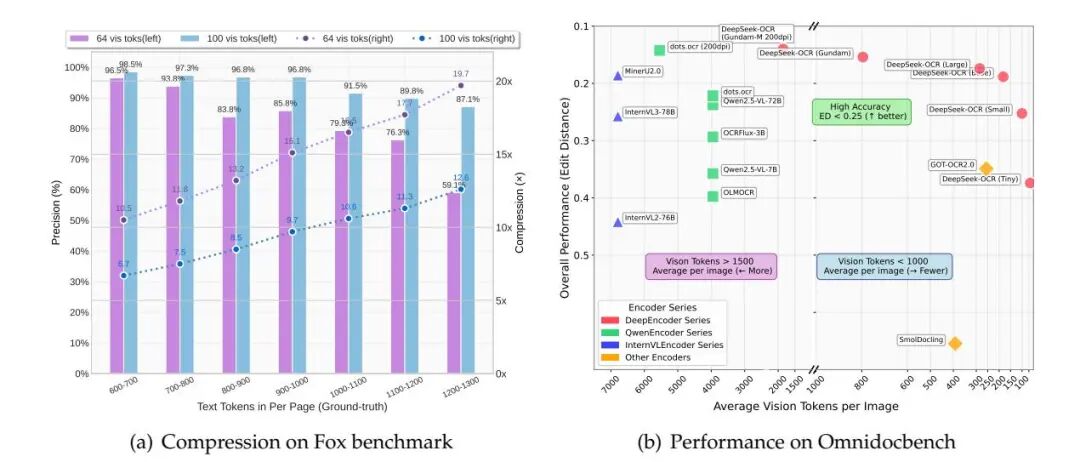
在Fox基准测试中,DeepSeek-OCR以10倍压缩率实现了97%解码准确率,远超传统方法,即使压缩率提升至20倍,准确率仍保持在60%左右,充分体现了模型在算力节约与文本编码上的行业领先水平。OmniDocBench评测结果显示,DeepSeek-OCR仅需100-400视觉token即可达到与主流大模型相当甚至更优的编辑距离表现,在表格、公式、报表等结构化信息提取方面尤为突出。模型支持近百种语言,可高效解析中文、英文及多语种PDF,适应全球化场景需求。依托“深度解析”能力,DeepSeek-OCR不仅识别文本,还能结构化提取图表、化学式和几何图形,显著扩展了应用边界。该模型在长文本压缩、复杂文档解析及多语言处理等关键环节展现出强大技术实力,为大规模智能文档处理与数据生成奠定了坚实基础。

应用前景与未来方向
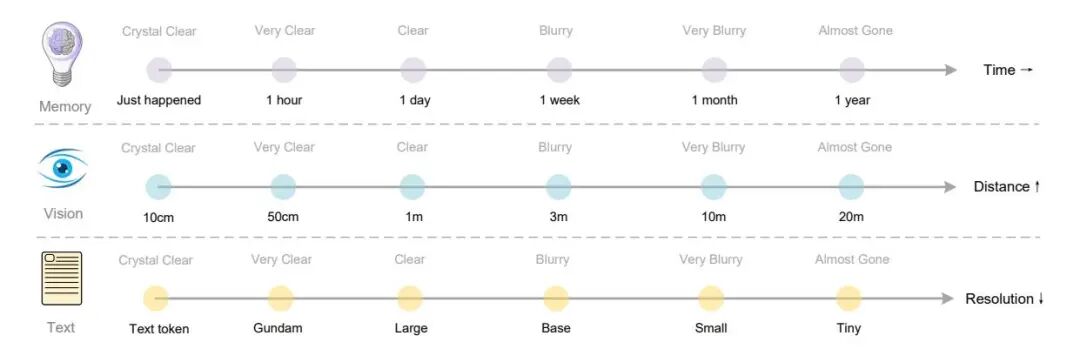
全球多语言数据处理正面临突破,DeepSeek-OCR在大规模训练数据生成与智能文档解析方面展现出显著优势。该模型支持近百种语言的PDF识别,覆盖少数民族语言,为跨语言信息获取提供了坚实技术基础。与此同时,DeepSeek-OCR不仅能够精准识别文本,还具备图像理解能力,支持图像描述与对象检测等任务,极大拓展了其应用领域。未来,作者提出通过光学上下文压缩技术提升长文本处理效率,模型可将历史对话内容压缩为图像,有效降低算力消耗,实现超长上下文管理。这一创新模拟了人类记忆衰减机制,为“无限上下文”架构提供了新思路。尽管光学压缩仍处于探索阶段,相关效果与局限有待进一步验证,但随着技术完善,DeepSeek-OCR有望成为大模型训练和智能文档分析的核心工具。提升压缩准确率、适应多样化文档结构及优化评估体系,将是推动技术广泛应用的关键。
Github:https://github.com/deepseek-ai/DeepSeek-OCR arXiv:https://arxiv.org/abs/2510.18234
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号