
LocalCluster调度程序没有使用所有内核,并且比默认线程调度程序慢吗?
提问于 2021-08-31 04:27:44
我使用dask数组来加速一台机器(4核或32核)上的计算,使用默认的“线程”调度程序或dask.distributed LocalCluster (线程,没有进程)。
考虑到dask.distributed调度器是新的,并且附带了一个很好的仪表板,我希望使用这个调度器。但是,我发现LocalCluster调度程序比默认调度程序慢(因子2或更多)。LocalCluster调度程序也没有充分利用所有请求的核心,偶尔在32核机器上只使用一个或几个内核。
问:这是预期的行为吗?如果没有,我可以做些什么来提高LocalCluster调度程序的性能?
下面是我用于测试的代码、示例输出(运行在4核计算机上)和测试后系统监视器的快照。
码
import numpy as np
import dask.array as da
import dask.distributed
from datetime import datetime
n_threads= 4
n = 40_000
def test(n=40_000, chunk=1000):
da.random.seed(731)
x = da.random.random((n,n), chunks=(chunk,chunk))
y = x + x.T
z = y[::2,5000:].mean(axis=1)
return z
print("Test default threads scheduler (size={}, {} threads)".format(n, n_threads))
start = datetime.now()
result1 = test(n=n).compute(scheduler="threads", num_workers=n_threads)
print("Done in {}".format(datetime.now()-start))
print("Test dask distributed LocalCluster scheduler (size={}, {} threads)".format(n, n_threads))
client = dask.distributed.Client(processes=False, n_workers=1, threads_per_worker=n_threads)
print("Client: ", client)
start = datetime.now()
result2 = test(n=n).compute()
print("Done in {}".format(datetime.now()-start))
client.close()
error = np.mean(np.abs(result1-result2))
print("Mean absolute difference between results: {}".format(error))输出
>> python test_dask.py
Test default threads scheduler (size=40000, 4 threads)
Done in 0:00:09.872372
Test dask distributed LocalCluster scheduler (size=40000, 4 threads)
Client: <Client: 'inproc://192.168.0.129/32574/1' processes=1 threads=4, memory=16.67 GB>
Done in 0:00:18.028071
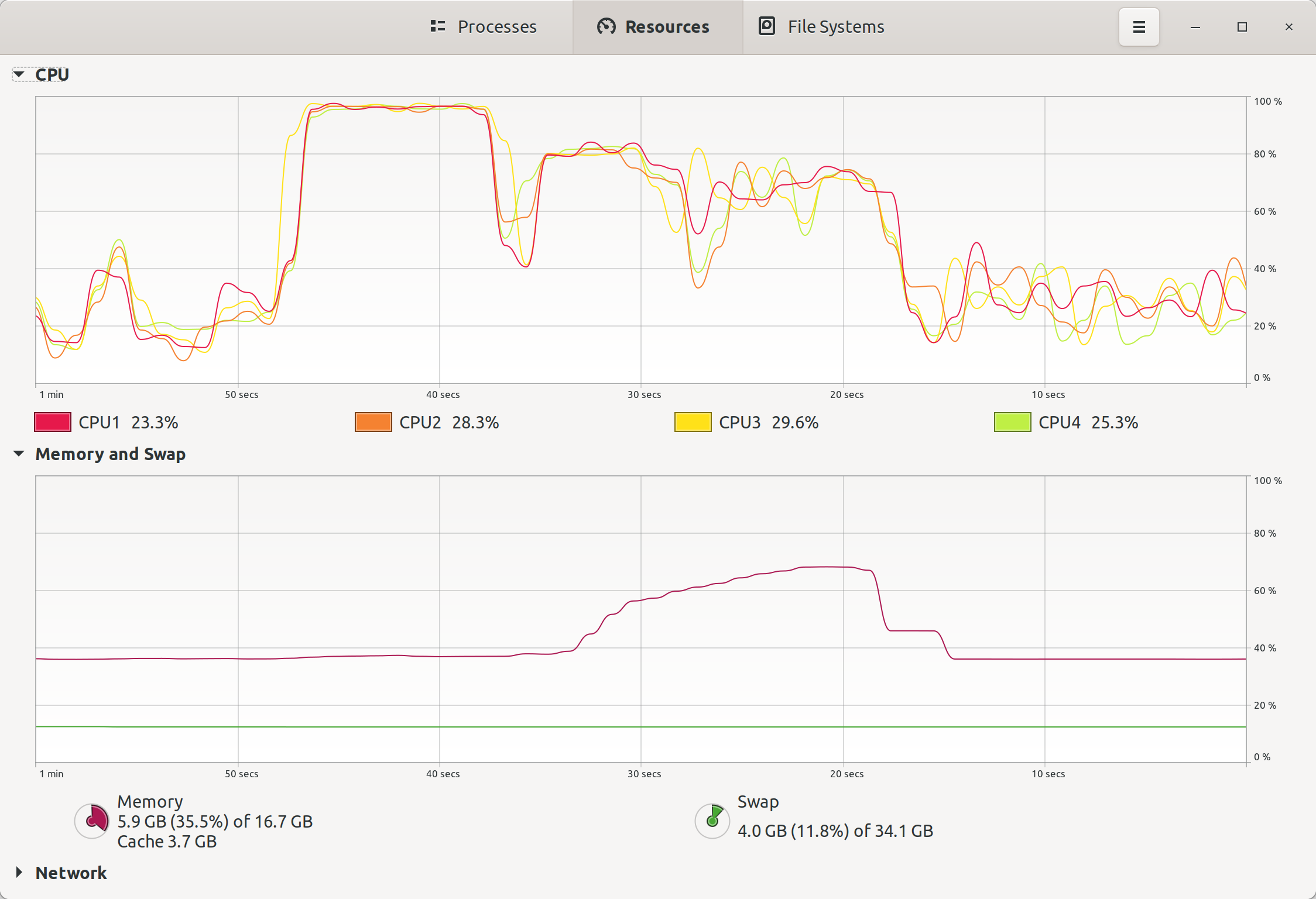
Mean absolute difference between results: 0.0CPU和内存使用
(默认线程调度程序为43-53秒,LocalCluster为23-45秒)

回答 1
Stack Overflow用户
发布于 2021-08-31 05:02:28
Numpy工作负载通常能很好地处理许多线程,而不是许多进程,因为底层操作会释放GIL,而对于线程则会最小化内存副本。
分布式调度器(即LocalCluster)允许您选择进程和线程的组合,并且确实可以在进程中工作(尽管这是比较少见的)。请参阅长串的论点,特别是n_workers、threads_per_worker和processes。如果您有一个工作线程和多个线程,您应该有类似于非分布式线程调度程序的东西。
但是,请注意,分布式调度程序比默认的线程调度程序更复杂。这通常意味着更聪明的性能,但总是意味着更多的每个任务的开销/延迟。当每个任务的执行时间非常短时,您会感觉到,这可能是简单的numpy操作的情况。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/68998665
复制相关文章







腾讯云开发者

