MongoDB 是否支持分片(sharding)?
什么是 MongoDB 分片集群?
云数据库 MongoDB 目前已经支持分片功能。
分片集群将数据按照片键分布存储在多台物理机上,平滑的扩展能力,非常适用于 TB 或 PB 级的数据存储场景。
分片集群支持实例级别的备份和回档来保证数据高可靠。每个分片内采用多节点自动容灾的机制,保证服务高可用。
可以使用腾讯云 MongoDB 分片功能便捷高效的搭建海量分布式存储系统。
如何创建 MongoDB 分片集群?
如何查询 MongoDB 分片集群的信息?
MongoDB 分片集群扩容方式有哪些?
MongoDB 如何实现分片集群实例监控?
云数据库 MongoDB 分片集群实例提供三个维度的监控指标,来进行整个集群的数据监控。
实例维度
片维度
节点维度
提供操作请求,容量使用,负载等多项指标的监控数据,可在实例的系统监控页查看。
MongoDB 的分片策略是什么?
支持 hash key 的分片机制。
支持联合字段的 shard key。
分片实例下所有数据集合必须使用分片,建议把不分片的数据放到单独的副本集实例下。
MongoDB 分片认证机制是什么?
MongoDB 完全兼容支持 SCRAM-SHA-1 和 MONGODB-CR 两种机制。
MongoDB 分片集群命令支持情况?
分片集群选择分片方式应遵循什么原则?
分片集群需要提前对数据集合启用分片,片键对分片集群的读写性能起着至关重要的作用,低版本 MongoDB 一旦设置就不能修改。最优片键选择一般遵循如下原则 :
保证写入的数据能均衡散列到多个分片。
尽可能保证高频查询能在一个分片获取到数据,避免从多个分片获取数据后 mongos 做聚合。
如果是高频类的范围查询,建议采用范围分片。
如果是高频类的指定查询,建议采用 hash 分片。
分片集群如何进行提前预分片?
对于分片集群来说,提前预分片,可以最大化保证数据均衡写入到多个分片,同时避免高峰期不同分片 chunks 不均衡而触发 moveChunk 操作引起的业务抖动。MongoDB 支持两种分片策略进行数据预分片。
Hash 预分片
hash 预分片,该功能默认支持,可通过以下命令实现,其中 n 为分片数。
sh.shardCollection("db.collection", {bookId:"hashed"}, false, { numInitialChunks: 8192*n} )
Balance 窗口设置
如果分片 chunk 不均衡会触发 moveChunk 来完成 balance 操作,moveChunk 过程会涉及到数据搬迁,会增加系统负载,业务高峰期会受到一定影响,因此建议在业务低峰期进行数据均衡操作,设置 balance 窗口。示例如下:
use configdb.settings.update({"_id":"balancer"},{"$set":{"activeWindow":{"start":"02:00","stop":"05:00"}}},true)
如何优化分片集群查询请求不带片键,导致数据库性能变差的问题?
问题现象
查询请求如果带上片键,可以保证数据落在对应的 shard,这样可以实现读性能的最大化。但是,实际业务场景中,一个业务访问同一个表,有些查询请求带有片键字段,而有些查询请求并不携带片键字段,这部分不带片键的查询请求便需要广播到多个 shard,之后经 mongos 聚合后再返回客户端,这类不带片键的查询效率较差。
解决方法
如果集群分片数比较多,不带片键的查询请求频率也很高,您可以通过建立辅助索引表来规避解决该问题。
例如,某 feed 信息流业务,每条 feed 信息对应一条详情数据,存放到 feed_info 详情表中。每条 feed 详情对应一条数据,如下:
{"_id" : ObjectId("614498889f97fd4692d22991")“feedId”: “223”“userId”: 3445“feedInfo”: “xxxxxxx”}
由于该 feed_info 详情表会频繁按照 userId 进行查询,因此选择 userId 作为分片片键。但是业务除了根据 userId 查询外,也会根据 feedId 进行查询,并且 feedId 查询频率也很高,由于根据 feedId 查询不带片建,因此该类查询会广播到所有分片,在多分片场景性能会很差。
这时候就可以引入 FeedId_userId_relationship 辅助表采用 feedId 作为片键,该表和 feed_info 详情表的隐射关系如下图所示。
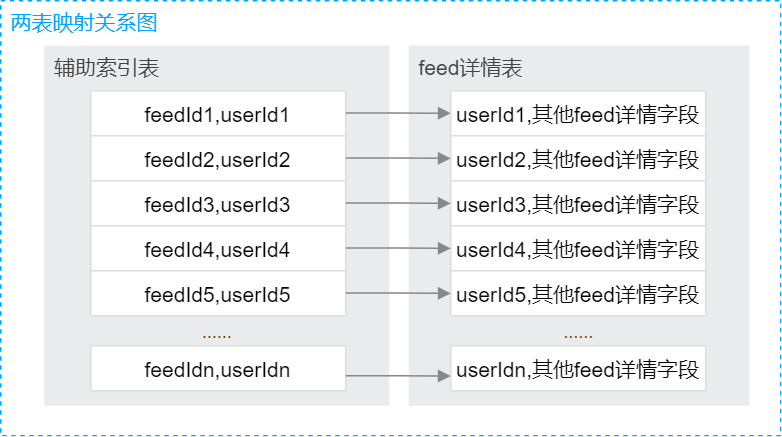
1. //FeedId_userId_relationship 表分片片建为 feedId,提前 hashed 预分片2. db.FeedId_userId_relationship.find({“FeedId”: “223”}, {userId: 1}) //假设返回的 userId 为“3445”3. //feedInfo 表分片片键为 userId,提前 hashed 预分片4. db.FeedInfo.find({“userId”: “3445”})
总之,通过引入辅助索引表,最终解决跨分片广播问题。但是引入辅助表会增加一定的存储成本,同时会增加一次辅助查询,建议只有在分片 shard 比较多,并且不带片键且查询比较频繁的情况使用。
如何清理孤儿文档?
在 MongoDB 分片集群中,由于数据迁移或其他操作中的意外情况,导致某些文档完成了复制但没有完成删除。使得同一份文档将会存在于两个 Shard 中。Config Server 记录这条文档的所属 Shard 信息,另一个 Shard 上的文档会存在但不会被感知,后续的 update、delete 操作都不会作用于这个错误的 Shard 上的文档,那么这条文档被称为孤儿文档(Orphaned Document)。在使用产品时,需要特别留意并处理这种情况,以确保数据的完整性和准确性。
MongoDB 4.4 及之后的版本,清理孤儿文档,请参见 cleanupOrphaned。
MongoDB 4.4 之前版本,清理孤儿文档,请参见 cleanupOrphaned。



