【腾讯云HAI域探秘】使用LCM-LORA助力炼丹师极速出丹
原创
【腾讯云HAI域探秘】使用LCM-LORA助力炼丹师极速出丹
原创
用户10801825
修改于 2023-12-18 14:36:40
修改于 2023-12-18 14:36:40
最近在使用腾讯云推出的高性能应用服务 HAI 体验 AI 作画,HAI 预置了 Stable Diffusion 等主流 AI 作画模型及常用插件,提供 GUI 图形化界面即开即用,大幅降低上手门槛。HAI 提供了两种算力方案,基础型算力提供 16G 的显存,0.88/每小时的价格,拿来炼丹性价比还是很高的。感兴趣的小伙伴可以参照 如何利用 HAI 轻松拿捏 AI 作画 进行体验。
显存 | 算力 | CPU&内存 | 费用 | |
|---|---|---|---|---|
基础型 | 16GB+ | 8+TFlops SP | 8 核 32G | 0.88/每小时 |
进阶型 | 32GB+ | 15+TFlops SP | 8~10 核 40G | 2.41/每小时 |
在使用 HAI 提供的 Stable Diffusion WebUI 应用时,遇到了出图缓慢,显存爆掉的问题,当然这是 Stable Diffusion 的原生问题,与 HAI 无关。但是 HAI 是 按使用时长计费 的,一想到白花花的银子就浪费在等待出图的时间上,就心痛难忍。于是开始寻找能加速出图的方法,这就是今天的主角:LCM-LoRA模型。使用 LCM-LoRA 体验极速出图,让你的 HAI 更具性价比!
一、LCM 介绍
LCM 的全称是 Latent Consistency Models(潜在一致性模型),由清华大学交叉信息研究院的研究者们构建。在这个模型发布之前,Stable Diffusion 等潜在扩散模型(LDM)由于迭代采样过程计算量大,生成速度非常缓慢。通过一些创新性的方法,LCM 只用少数的几步推理就能生成高分辨率图像。据统计,LCM 能将主流文生图模型的效率提高 5-10 倍,所以能呈现出实时的效果。在此基础上,研究团队进一步提出 LCM-LoRA,可以将 LCM 的快速采样能力在未经任何额外训练的情况下迁移到其他 LoRA 模型上,为开源社区已经存在的大量不同画风的模型提供了一个直接而有效的解决方案。
- 论文链接:https://arxiv.org/pdf/2310.04378.pdf
- 项目地址:https://github.com/luosiallen/latent-consistency-model
二、如何在HAI中使用LCM-LoRA
LCM-LoRA 模型分为两个版本:LCM-SD1.5-LoRA 和 LCM-SDXL-LoRA。分别对应 SD1.5 基础模型和 SDXL 基础模型,使用时根据所用的基础大模型版本选择相应的LoRA模型。
2.1 下载LCM-LoRA模型文件
- 方法一:LCM团队已经将LCM模型及LoRA模型上传到始智AI(wisemodel) ,以方便国内用户下载,下载地址:https://www.wisemodel.cn/organization/Latent-Consistency-Model。
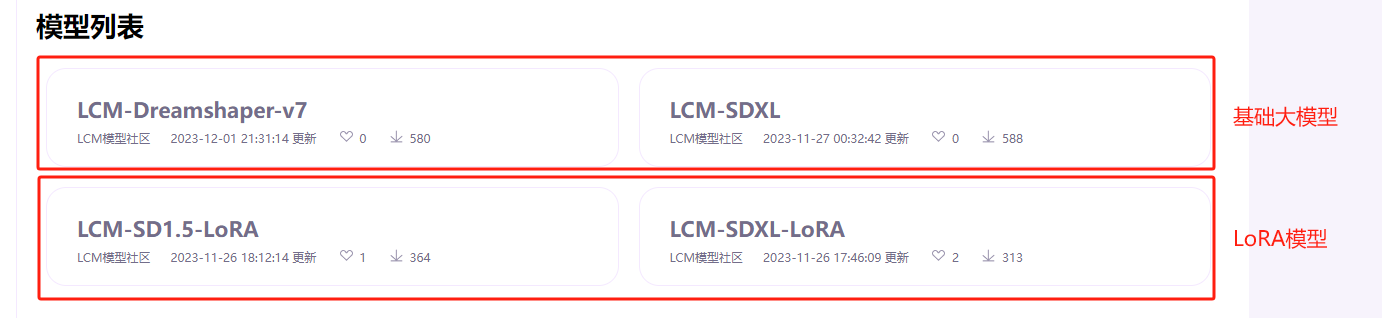
模型文件下载成功后,注意将默认文件名修改一下,便于后续的使用,之后通过JuyperLab将模型文件上传至 HAI 的 /root/stable-diffusion-webui/models/Lora/ 目录下即可。
- 方法二:直接在 HAI提供的JuyperLab 命令行终端执行以下命令从HF国内镜像下载
#下载LCM-SD1.5-LoRA
wget -O /root/stable-diffusion-webui/models/Lora/lcm-lora-sdv1-5.safetensors https://hf-mirror.com/latent-consistency/lcm-lora-sdv1-5/resolve/main/pytorch_lora_weights.safetensors
# 下载LCM-SDXL-LoRA
wget -O /root/stable-diffusion-webui/models/Lora/lcm-lora-sdxl.safetensors https://hf-mirror.com/latent-consistency/lcm-lora-sdxl/resolve/main/pytorch_lora_weights.safetensors模型下载成功后,在SD-WebUI的LoRA页签或者在/root/stable-diffusion-webui/models/Lora/能看到模型文件即可。
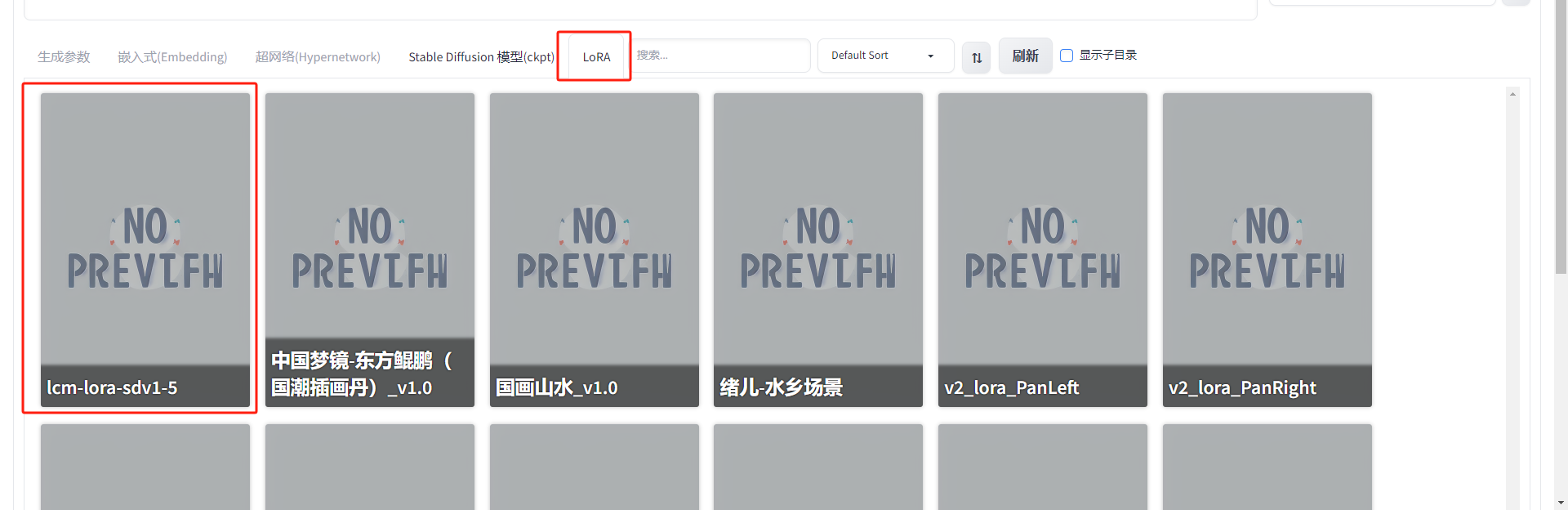

2.2 使用LCM-LoRA模型
LCM-LoRA模型的使用与其他LoRA模型略有差异。主要关注迭代步数、提示词相关性两个配置即可,如果使用SDXL基础模型,还需要额外关注一下采样方法。接下来就分别说明一下SD1.5 基础模型和SDXL 基础模型如何配合LCM-LoRA模型提速。
- SD1.5 基础模型使用 LCM-LoRA
参数项 | 参数值 | 参数说明 |
|---|---|---|
正向提示词 | 结尾添加: | 这里与使用普通LoRA模型是一样的 |
迭代步数 | 4~8 | 传统的迭代步数一般是 20 以上,使用 LCM-LoRA 模型的迭代步数设置在 |
提示词相关性 | 1或者2 | 传统的提示性相关性一般都在 |
其余参数 | 与正常情况下保持一致即可 |
- SDXL 基础模型使用 LCM-LoRA
参数项 | 参数值 | 参数说明 |
|---|---|---|
正向提示词 | 结尾添加: | 这里与使用普通LoRA模型是一样的 |
采样方法 | LCM或者Euler a | 这里推荐使用LCM采样方法,作品画质相较于Euler a会更好 |
迭代步数 | 4~8 | 传统的迭代步数一般是 20 以上,使用 LCM-LoRA 模型的迭代步数设置在 |
提示词相关性 | 1或者2 | 传统的提示性相关性一般都在 |
其余参数 | 与正常情况下保持一致即可 |
注意:Stable Diffusion WebUI目前并没有预置LCM采样方法,需要通过安装AnimateDiff插件来获得。在Stable Diffusion的“扩展(extensions)”菜单,选择“可用(available)”,点击“加载自(load from)”,搜索“animatediff“,点击“安装(Install)”。
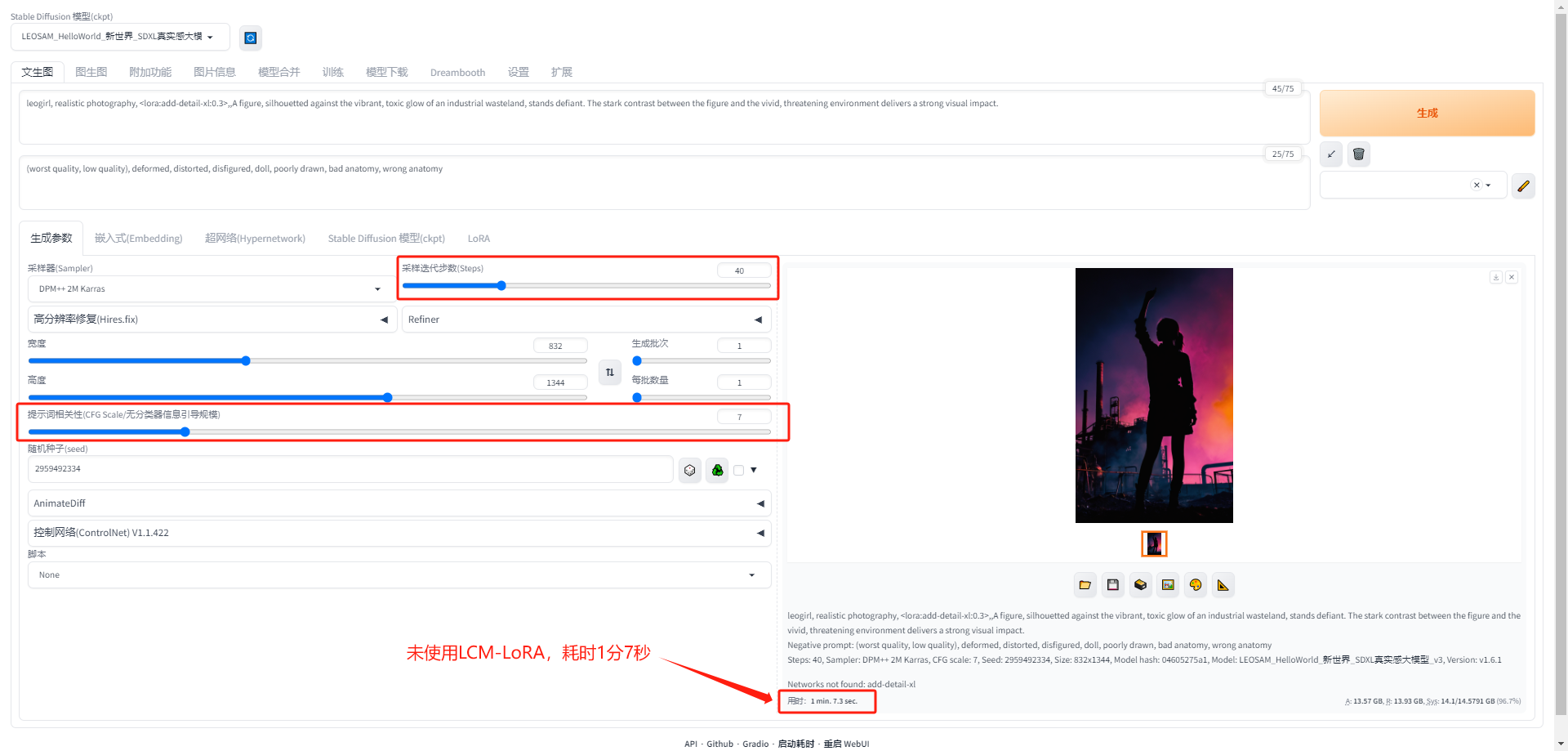
效果对比
- 正常情况下出图:耗时1分7秒,显存使用率96.7%
- 使用 LCM-LoRA 模型出图:耗时15秒,
速度快了接近5倍!显存占用率88.7%,降低了8%
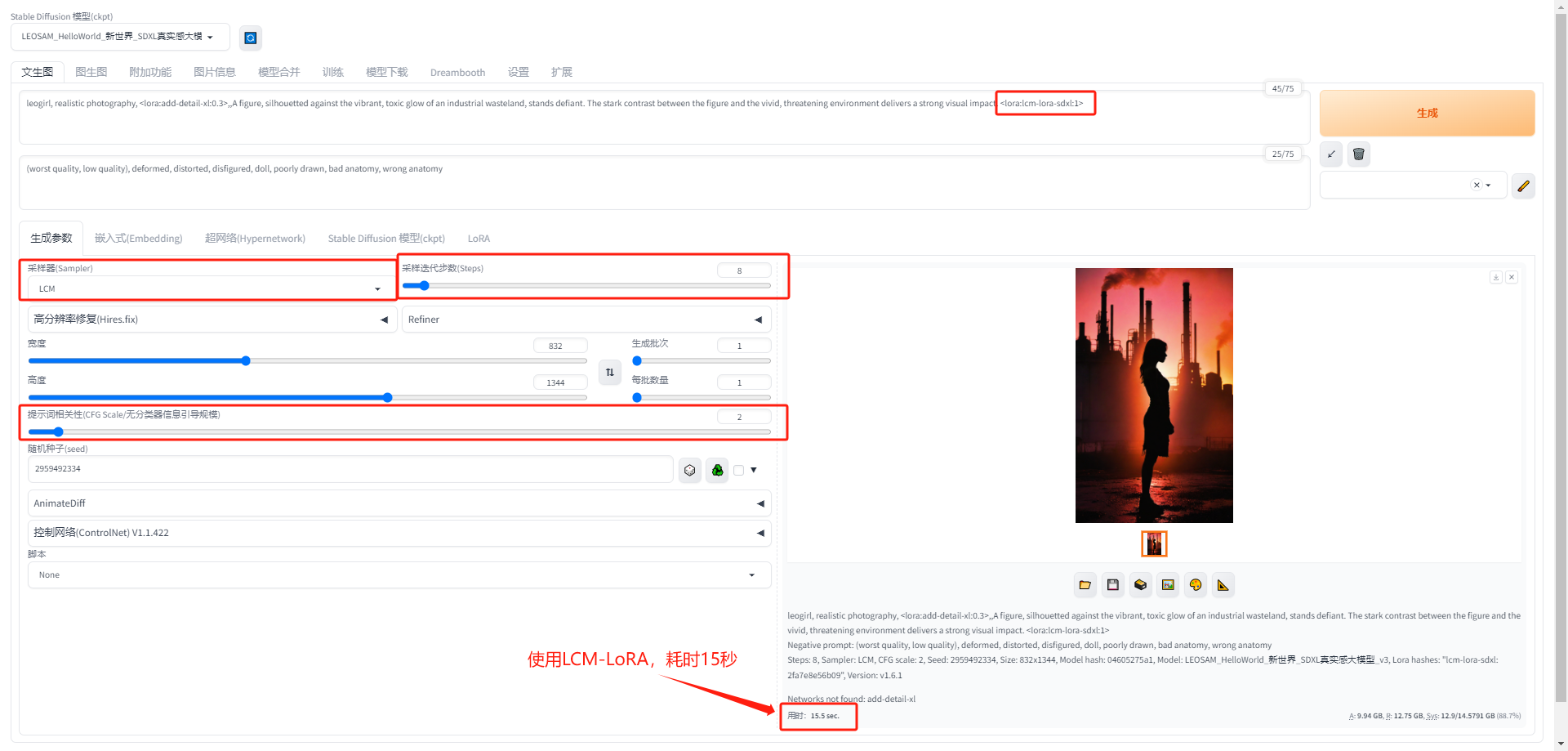
- 图片质量对比:第一张是正常出的图,第二张是使用LCM-LoRA 模型后的出的图


总结
可以看到,在使用了LCM-LoRA模型后,使用SDXL模型生成图片的速度提升了近5倍,显存使用率也有一定的下降,不过图片质量也略微有些下降,但也勉强够用。以后再也不担心HAI的账单超标了。
最后也是希望HAI的Stable Diffusion应用能够预置更多的常用插件和一些常用基础模型,譬如中文插件、AnimateDiff插件等,同时也希望可以提供更为方便快捷的模型下载途径。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号