大模型应用之概念篇(1):文件结构、模型命名、参数规模


背景
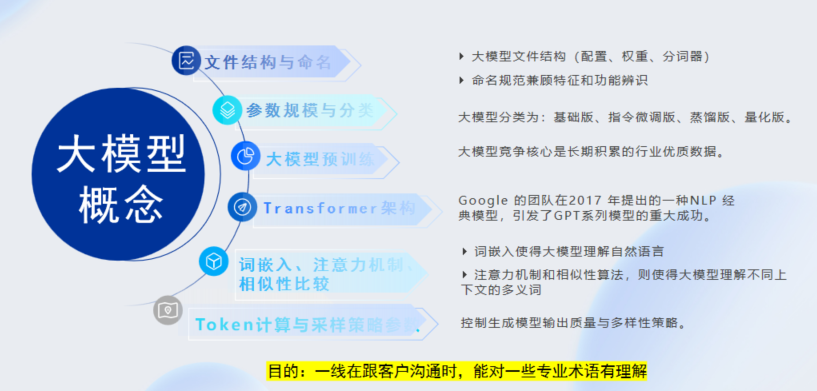
我们了解相关的专业术语,其实利于大模型业务推广,尤其是一线推广过程中,能够提高专业度和客户依赖性。
大模型的文件结构(Llama-2为例)
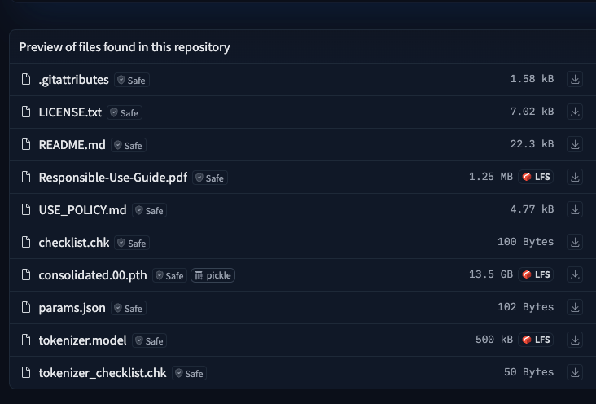
参考:https://huggingface.co/meta-llama/Llama-2-7b
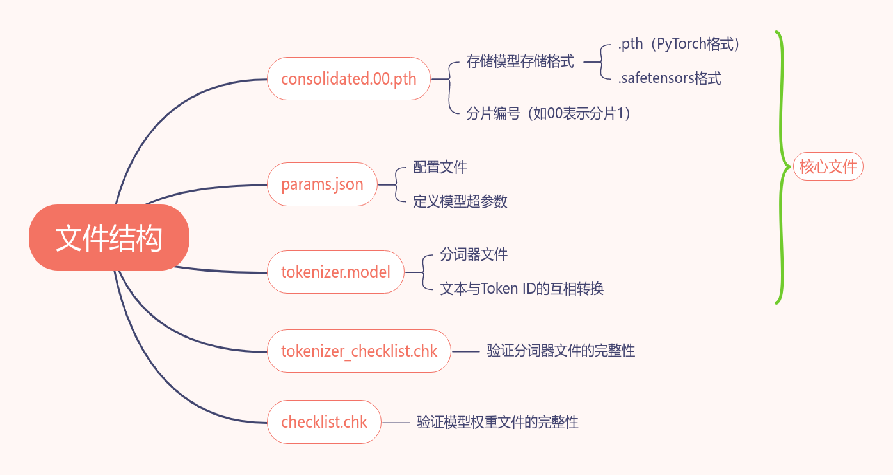
小结:PyTorch是深度学习框架之一,使用 .pth 文件(或 .pt)作为模型权重文件的标准格式。
大模型命名
模型名称的定义通常会包含一系列信息,以帮助用户快速了解模型的关键特性
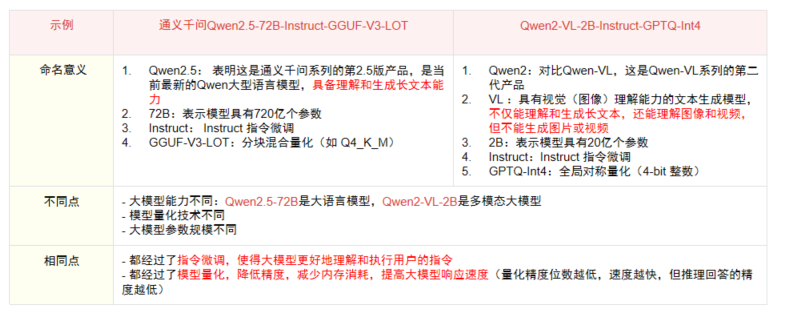
一、模型架构差异
基础能力维度
- Qwen2.5-72B作为720亿参数规模的纯文本大语言模型(LLM),其核心优势在于复杂语义理解和长文本生成能力
- Qwen2-VL-2B则是20亿参数规模的多模态模型(VL:Vision-Language),在保留文本理解能力的基础上,新增视觉模态处理能力,可实现图像/视频的内容解析
量化技术方案
- 72B版本采用GGUF-V3-LOT分块混合量化技术(如Q4_K_M),通过对模型参数进行分块差异化压缩,在保持推理精度的同时显著降低显存占用
- VL-2B版本则应用GPTQ-Int4全局对称量化方案,采用4-bit整数精度实现整体模型压缩,更适合边缘设备部署
二、技术共性特征
- 均采用指令微调(Instruct Tuning)技术,通过监督学习优化模型对用户意图的捕捉能力,使模型输出更符合人类指令预期
- 都经过严格的量化处理:
- 量化位宽直接影响推理效率,典型表现为:精度每降低1bit,推理速度可提升20-30%
- 需注意量化带来的精度-效率权衡(Quantization-Accuracy Trade-off),如Int4量化会使模型输出波动性增加约15%
大模型参数规模(DeepSeek-r1和qwen3为例)
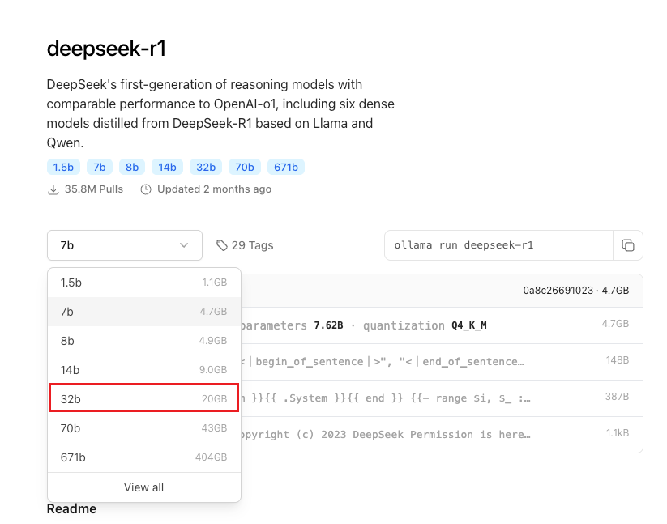
参考:https://ollama.com/library/deepseek-r1
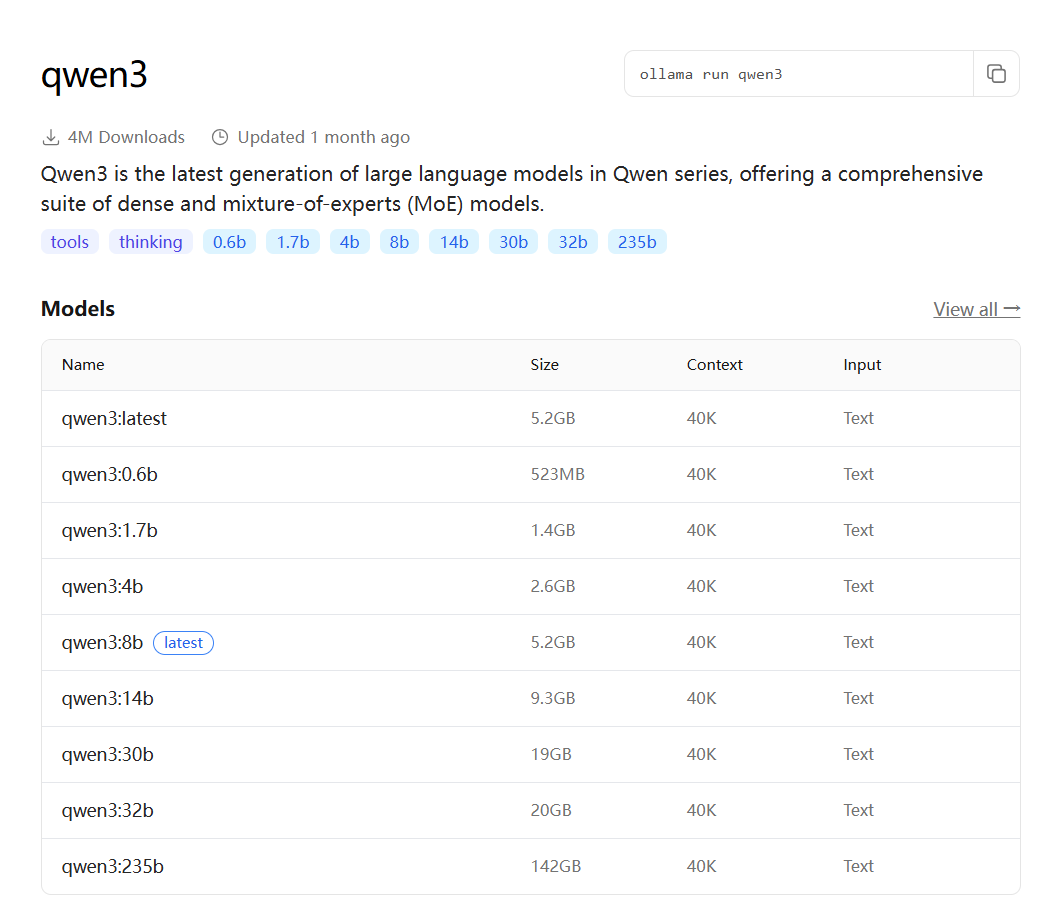
参考:https://ollama.com/library/qwen3
小结:
大模型参数的数量,则类比人类大脑本身的成长和成熟。
671B参数数量:这些一般指参数的个数,B是Billion/十亿的意思。
参数:是指模型内部通过海量数据学习获得的数学权重和连接关系,直接决定模型的认知能力和任务处理性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-29,如有侵权请联系 cloudcommunity@tencent.com 删除
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号