智能的未来:拆解自主Agent四大支柱,你的LLM“活”了吗?
原创
智能的未来:拆解自主Agent四大支柱,你的LLM“活”了吗?
原创
走向未来
发布于 2026-01-28 19:52:40
发布于 2026-01-28 19:52:40
感知-推理-记忆-执行:详解大模型自主认知智能体的架构
走向未来
大语言模型(LLM)的出现,标志着人工智能在认知自动化领域取得了显著进展。我们正处在一个转折点,复杂的想法似乎可以直接转化为可执行的系统。然而,尽管LLM展现了强大的语言理解和生成能力,但它们本质上仍是“聊天机器人”,是被动的回应者,而非主动的行动者。它们缺乏在动态环境中自主追求目标、与外部工具交互或保留长期记忆的能力。这种局限性导致了当前模型在处理真实世界复杂任务时,与人类的能力之间存在明显的性能鸿沟。
为了跨越这一鸿沟,研究的焦点正从单纯提升模型规模转向构建“智能体”(Agentic)系统。这种转变的核心,是将LLM从一个全能的“大脑”重新定位为一个认知“核心”或“主干”,并围绕它构建一个完整的认知架构。这不再是关于模型本身,而是关于一个由多个协同工作的子系统构成的整体。一个简单的、预定义步骤的“工作流”不等于一个“智能体”。工作流是僵化的,它在受控环境中表现良好;而智能体则是自主的、适应性强的,它能够根据环境反馈动态生成和调整策略,甚至从错误中恢复。

b/001.jpg
本文深入分析构建这样一个自主智能体所必需的四大架构基石:感知系统、推理系统、记忆系统和执行系统。我们将探讨这些组件如何协同工作,将大语言模型从一个抽象的知识模拟器,转变为一个能够在现实世界中感知、思考、记忆和行动的真正自主的认知实体。本文的PDF版本及参考资料已收录至“走向未来”知识星球。
感知系统:智能体的世界接口与现实锚点
智能体的自主交互始于感知。感知系统的核心任务是捕获环境中的原始数据,无论是文本、图像还是结构化信息,并将其转化为LLM可以理解和利用的有意义的表征。这是智能体将其抽象知识“锚定”到物理或数字世界的第一个环节。

d/005.jpg
最初的感知是纯文本的,但这严重限制了智能体的应用场景。真正的突破来自于多模态感知,特别是视觉语言模型(VLM)和多模态大语言模型(MM-LLM)的发展。这些模型通过编码器、输入投影仪和LLM主干的架构,试图将视觉信息和语言信息统一到一个嵌入空间中,使智能体能够“看到”其操作的环境,例如图形用户界面(GUI)。
然而,仅仅“看到”是不够的。研究表明,智能体在GUI操作中的许多失败,源于“GUI锚定”的困难——即无法将屏幕截图中的视觉元素与其功能和精确坐标相关联。为了解决这个问题,研究探索了两种关键的增强路径。第一种是增强视觉焦点,如“标记集”(Set-of-Mark, SoM)操作,通过在图像上用边界框或标签明确标注关键区域,引导模型集中注意力。另一种是集成更丰富的感知模态,如VCoder利用分割图和深度图,为模型提供精细化的对象信息和空间关系。
第二种更稳健的路径是超越纯视觉,引入结构化数据。例如,在Web环境中,智能体可以不依赖截图,而是直接解析HTML的文档对象模型(DOM)或操作系统的可访问性树(Accessibility Tree)。这些信息树提供了关于界面组件(如按钮、文本框)的语义角色、状态和层次结构的精确描述。
一个成熟的感知系统,会将这两种路径结合起来。它既使用多模态模型来理解视觉布局(“那个红色的按钮在哪里”),也使用结构化数据来理解语义功能(“这个HTML元素是一个‘提交’按钮”)。这种视觉与语义的结合,是构建丰富、可操作的环境模型的关键,也是解决模型“幻觉”问题、确保其行动基于现实而非猜测的基础。
推理系统:智能体的认知核心与决策中枢
如果感知系统是智能体的“眼睛”,那么推理系统就是其“大脑”。它接收来自感知系统的信息,并围绕当前任务制定、评估和调整行动计划。这是智能体自主性的核心体现,它将LLM从一个简单的输入输出函数,转变为一个动态的、目标导向的规划器。
d/001.jpg
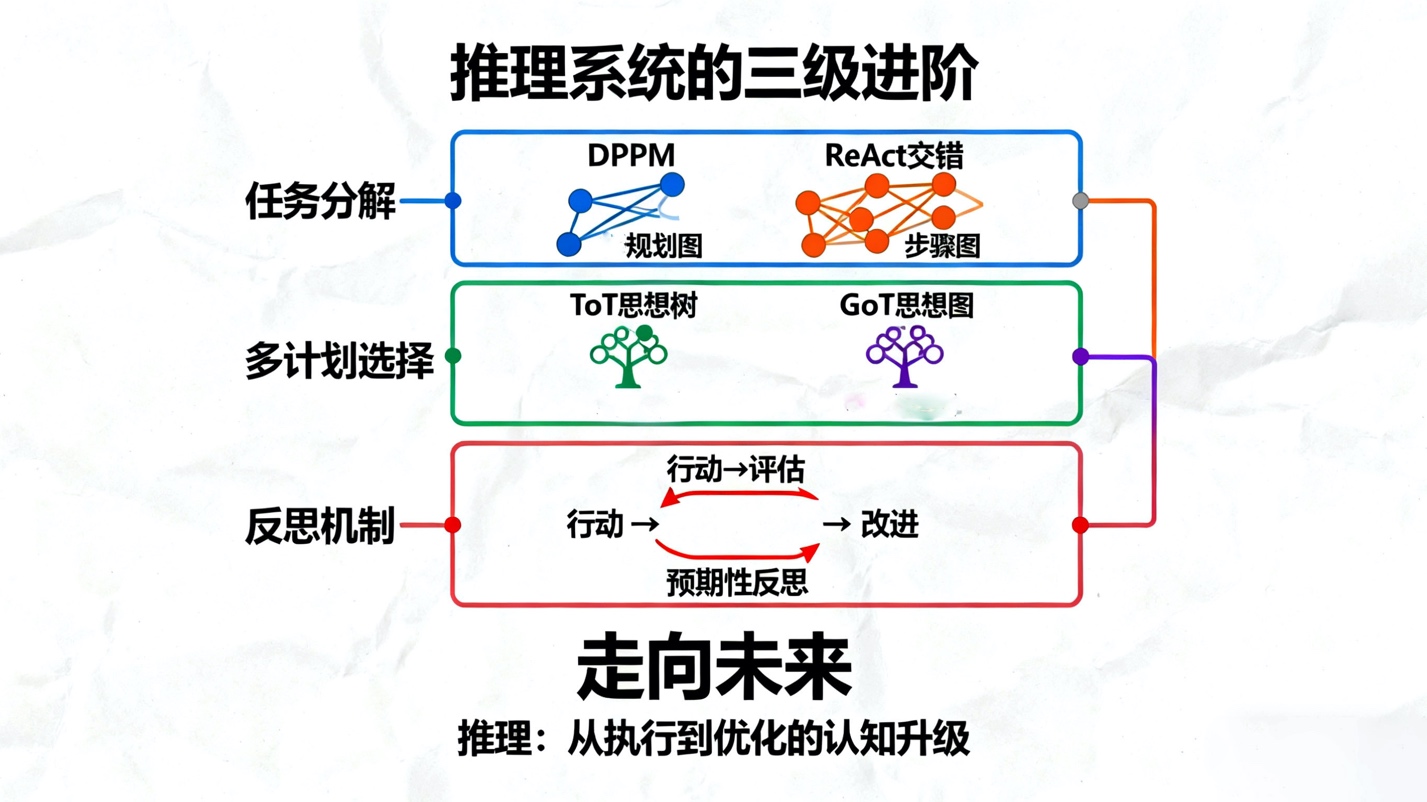
构建这一认知核心的第一步是任务分解。复杂问题必须被分解为更小、更易于管理的子任务。研究表明,分解策略本身对智能体的效率和鲁棒性有重大影响。一种策略是“先分解”,例如DPPM(分解、并行规划、合并),它首先将任务完全分解,然后并行生成各个子任务的规划,最后再整合成一个全局计划。这种方式可以避免在顺序规划中常见的错误累积。另一种策略是“交错分解”,如著名的ReAct(推理与行动)框架,它将推理和行动步骤交织在一起,使智能体能够根据每一步的环境反馈动态调整后续计划,从而更好地应对不可预见的环境变化。
由于任务的复杂性和LLM的固有不确定性,单一的计划往往是次优的。因此,更强大的推理系统会采用多计划生成与选择机制。这标志着从“链式思考”(Chain-of-Thought, CoT)向更广阔的“探索式思考”转变。例如,“自洽性CoT”(CoT-SC)会生成多个推理路径并选择多数答案。“思想树”(Tree-of-Thought, ToT)则更进一步,它将问题求解构建为一个树状探索过程,智能体可以在每个节点上评估多个“思想”分支,并决定哪个分支最有可能导向成功,从而实现更深思熟虑的规划。更高级的“思想图”(Graph-of-Thoughts, GoT)允许思想路径合并和循环,实现了更复杂的推理结构。
推理的最高形式或许是“反思”。智能体不仅要规划未来,还必须能批判性地评估过去。反思机制允许智能体检查其已完成的行动、计划和结果,分析错误的原因,并从中提炼出可用于改进未来性能的见解。这使智能体能够从失败经验中学习,而无需人类干预。一种更具前瞻性的“预期性反思”(Anticipatory Reflection),甚至让智能体在执行一个步骤之前,主动扮演“魔鬼代言人”的角色,挑战自己即将做出的决策,预演潜在的失败并提前制定缓解措施。
最后,当任务复杂度超越单个智能体的能力时,推理系统可以演变为多智能体系统。在这种架构中,认知负担被分配给一组具有不同专长的“专家”智能体,例如规划专家、反思专家、错误处理专家或工具使用专家。LLM不再是唯一的思考者,而是扮演了“协调者”的角色,负责调度和整合这些专家的能力,以模块化、可扩展的方式解决极端复杂的问题。
记忆系统:智能体的经验积累与持续进化
标准LLM最根本的缺陷之一是缺乏记忆。它们的知识在训练后被冻结,并且其交互历史仅限于短暂的“上下文窗口”。一个无法记忆过去、无法从中学习的实体,不能被称为真正的自主智能体。因此,记忆系统是连接智能体过去和未来的桥梁。
短期记忆在概念上等同于模型的上下文窗口,它是一个临时的“工作区”。真正的挑战在于构建长期记忆。目前,实现长期记忆的途径主要有三种。第一种是“具身记忆”,即通过持续的微调(fine-tuning)将经验和知识编码到模型参数(权重)中。这种方式类似于人类的“内隐记忆”或“肌肉记忆”,但它的成本高昂且过程缓慢。
第二种是“检索增强生成”(RAG)。这是当前最主流的范式,它将知识存储在LLM之外的外部知识库中(通常是向量数据库)。当需要时,智能体首先检索相关信息,然后将其“注入”到短期记忆(上下文窗口)中,以指导生成。这好比人类的“外显记忆”,即主动“查阅资料”的过程。这一范式正是为了解决大语言模型固有的“幻觉”和“知识陈旧”两大顽疾。资深人工智能专家王文广在其灯塔书《知识增强大模型》中,系统性地阐述了这一架构的理论与实践。他指出,RAG通过外部知识源(如向量数据库)为模型提供了“事实锚点”,使其生成的内容不再是无源之水。然而,简单的向量检索(RAG)在处理高度结构化、关系复杂的知识时仍显不足。因此,一个更高级的记忆系统会从RAG演进到“GraphRAG”,即“图模互补”的应用范式。如王文广在书中(第8、9章)所深入探讨的,知识图谱(Knowledge Graph)以其强大的关系建模能力,弥补了向量检索在深度推理和全局视野上的短板。对于智能体而言,知识图谱不仅是“事实”的存储库,更是“经验”和“程序”的结构化载体。这种图模互补的架构,使得智能体在需要时,既能进行快速的语义检索,也能执行可解释的深度图谱推理,从而获得更精确、更可靠的记忆支持。
第三种是利用SQL等结构化数据库。这使得智能体能够存储和查询精确的、结构化的知识,例如用户信息、订单详情或公司规章。
构建记忆系统时,一个比“如何存”更深刻的问题是“存什么”。为了实现真正的自主性,智能体需要存储的远不止是事实(知识)。研究指出,智能体必须存储“经验”,包括成功和失败的任务记录。通过明确标记“失败的经验”,LLM可以在未来学会避免重蹈覆辙。
更进一步,智能体应存储“程序”。“智能体工作流记忆”(Agent Workflow Memory, AWM)是一种新兴方法,它允许智能体从过去的成功经验中“归纳”出可重用的任务工作流或例程。当下一次遇到相似任务时,智能体可以直接调用这个“程序”,而不是从头开始推理。这标志着从“事实回忆”到“行为回忆”的重大转变,是一种更高级的学习形式。
最后,记忆系统还需存储“用户信息”,如MemoryBank等机制,通过综合过往交互来理解用户的偏好和个性。一个拥有记忆的智能体,才能实现连续性和适应性,从一个一次性的工具转变为一个持久的、可进化的合作者。
执行系统:智能体的物理交互与现实闭环
感知、推理和记忆都是智能体内部的认知活动。而执行系统,则是智能体的“手脚”,它负责将内部的抽象决策转化为对环境的具体影响。这是认知闭环的最后一环,也是智能体“思想”与“现实”接触的地方。
最基础的执行方式是工具和API集成,也就是“函数调用”。LLM生成结构化的指令(如JSON),指定要使用的工具和参数。这使其能够操作文件、查询数据库或请求网页。
然而,更强大的智能体需要能够在“多模态行动空间”中执行任务。这包括通过计算机视觉和自动化框架来控制图形用户界面(GUI)。智能体通过生成精确的鼠标点击、键盘输入和拖放操作,使其能够自动化操作任何现有的软件应用,即使这些应用没有提供API。这为智能体在庞大的存量软件生态中发挥作用打开了大门。
一种更强大的执行能力是动态的代码生成和执行。智能体可以通过编写和运行Python脚本来进行复杂的数据分析,或生成SQL查询来操作数据库。在这种模式下,智能体扮演了一个“初级开发者”的角色,利用代码的精确性和图灵完备性来解决逻辑问题。
最终,执行系统将延伸到对机器人和物理系统的控制。LLM处理来自摄像机或传感器的感知数据,生成运动规划和控制指令,协调物理执行器。
执行系统是智能体最终的“现实检验”。这个系统的鲁棒性——它如何处理一个失败的API调用、一个因界面变化而错过的点击、或是一个意外的物理阻碍——直接决定了智能体能否在非理想的真实世界中成功完成任务。
结论:迈向真正的自主智能
本文描绘了一幅清晰的蓝图,揭示了自主智能体远非一个单一的大语言模型,而是一个复杂的、模仿人类认知过程的精巧架构。我们正见证着一个根本性的转变:从将LLM作为被动的语言模拟器,转向将其作为主动的认知核心,并围绕它构建完整的智能系统。

d/002.jpg
这一系统的四大支柱——感知、推理、记忆和执行——并非孤立存在,而是深度集成、协同工作的。感知系统将智能体锚定于现实;推理系统为其提供规划和反思的自主性;记忆系统使其能够积累经验并持续进化;执行系统则赋予其在现实世界中产生影响的能力。这四个组件的有机结合,构成了从被动智能到自主行动的必由之路,也为下一代人工智能的发展奠定了坚实的基础。
正如《知识增强大模型》一书(第10章)所强调的,这四大支柱的落地,最终将依赖于一个完善的“知识运营”(Knowledge Operation)体系——即对智能体所依赖的知识进行持续的质量评估、流程管理和合规治理。这确保了智能体的自主性是建立在可靠、高质量和可信的知识基础之上的,这也是其实用价值和社会价值的根本保证。

d/003.jpg
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号